
文章
联邦学习:人工智能的发展之钥,隐私难题的解决之道(上)
随着人工智能的蓬勃发展,各企业将数据转化为创新应用,数字应用和原生品牌之间的界限变得越来越难以界定。数据、信息的跨域流动提高了生产力、增加了创新并促进了可持续发展,同时也带来了隐私、数据保护、知识产权及安全问题相关的挑战。
德勤认为,一方面,全球范围内的多项立法工作试图解决与个人隐私、数据保护和安全性相关的诸多问题,另一方面业界也存在对于数据管控的担心,过度监管可能阻碍数据的创新,从而影响企业和经济的增长。在今年6月份的G20峰会上,与会国家已经认识到平衡两种需求的重要性。
德勤一直关注人工智能应用与风险管理的发展和演进,很早就发布了人工智能风险管理框架,致力于为监管和企业提供数据治理、数据合规、隐私保护方面的帮助。德勤注意到,除了监管政策、法律方面的努力,技术方面,一种叫做“联邦学习”技术,近期也成为企业和监管关注的热点,成为平衡数据保护与数据应用的另一种可能手段。
为了解决“数据保护”与“数据孤岛”这两大难题,Google公司于2016年提出了联邦学习(Federated Learning),旨在将“人工智能的重点转移到以保障安全隐私的大数据架构为中心的算法导向上”。目前,众多企业与研究机构都在积极地探索联邦学习的应用方式,它或许将成为下一个人工智能困境的解决之道。

Part 1 - 初识联邦学习
多个数据拥有方各自收集到不同的数据,但同一机构不同部门间的数据不对称、企业间的数据交换受到监管制约、国家对用户隐私的保护,导致了单个数据拥有方的数据不足以构建一个高质量的模型。因此,他们需要构成一个互相合作的生态系统,通过联邦学习的方式,在底层数据加密或混淆的前提下,进行参数交换方式,从而建立一个虚拟的共有模型。在建立模型的过程中,数据本身不移动,也不会泄露用户信息或影响数据规范。这样的系统在各自的区域仅为本地的目标服务,从而帮助系统内的各方实现了获益。

Part 2 - 建立联邦系统
一个完整的联邦学习系统由多个数据拥有方组成,其中也可以包括第三方协作者,来协助模型的加密训练。根据用户特征重合度与用户重合度,数据拥有方通过加密的方式将数据集以不同的方式进行对齐,而后进行加密模型训练。整个建模过程实现了数据隐私的保护,同时会以约定的机制奖励数据贡献更多的拥有方。
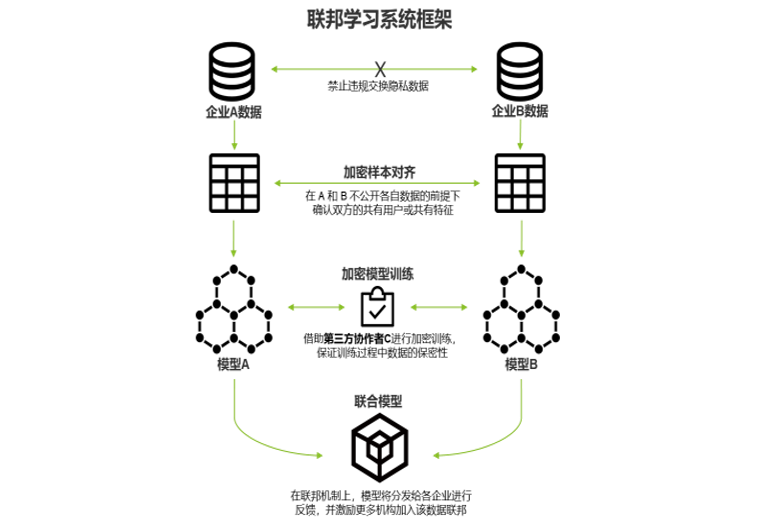
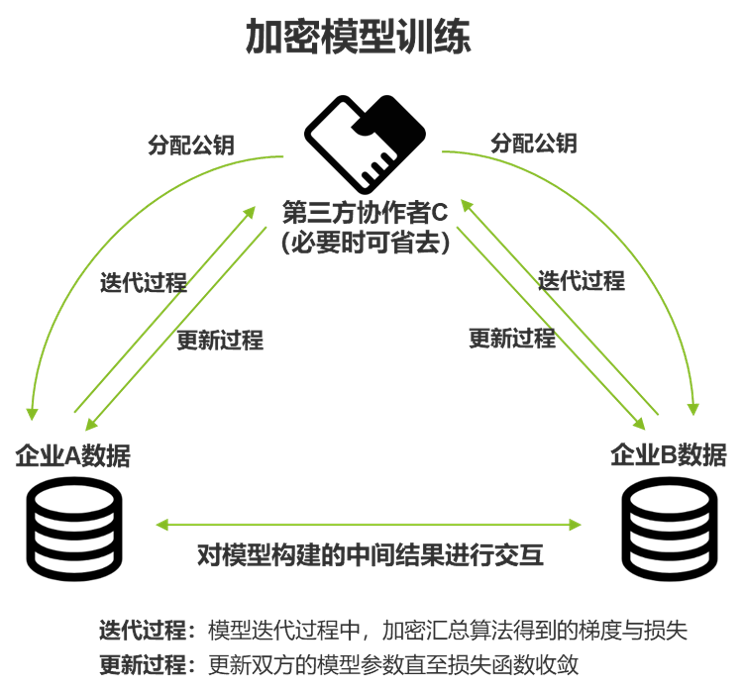
模型的训练可以借助第三方协作者来完成,由他来分配公钥给数据拥有方,从而对训练过程中使用的数据进行加密。数据拥有方之间以加密的形式实现中间结果的交互,并用于模型的迭代更新:
Part 3 - 联邦学习的优势
当前的大环境下,人工智能的重点已经从以AI基础算法为中心的导向,转移到以保障安全及隐私的大数据架构为中心的导向上。这一重心的转移,推动了联邦学习的诞生,它为使用者带来了传统机器学习所不具有的优势:
- 实现数据隔离:客户数据将不会泄露,满足其隐私保护和数据安全的需求;
- 满足监管需要:《中华人民共和国网络安全法》、欧盟的《通用数据保护条例》、HIPAA法案等都要求用户数据的收集必须公开透明,企业或机构之间在无用户授权的情况下不能交换用户数据,联邦学习可以满足这样的监管要求;
- 避免数据孤岛:联邦学习在保证参与各方保持独立性的情况下,进行信息与模型参数的加密交换。同时,参与各方的地位对等,促进公平合作;
- 清除工程障碍:联邦学习可以避免用户数据量大、网络连接费用昂贵、传输速度缓慢、传输安全性低等工程问题。
数据的隔离和对数据隐私的保护正成为AI领域的下一个挑战,但联邦学习为我们带来了新的希望。随着技术的推广与标准的完善,它将打破行业之间的障碍,建立起一个可以安全地共享数据和知识的社区,让每个参与者都能公平的分享利益。
在下一篇中,我们将结合德勤在AI领域的风险管理实践,为大家进一步介绍联邦学习在隐私、数据安全、算法管理方面的应用。

