Un nuevo abordaje para el Self-Service BI Ha sido salvado
Introducción
Una nueva estrategia de modelado para bases de datos relacionales puede resolver un problema recurrente en la implementación del “Self-Service BI”.
Recientemente Bill Inmon, considerado el padre del Data Warehouse ha sido co-autor, juntamente con Francesco Puppini, de un libro titulado “Unified Star Schema”. He leído el libro y sí que parece que es un abordaje interesante para solventar un problema recurrente en entornos de Business Intelligence corporativos. En este artículo voy a recurrir a algunos conceptos de su teoría y a explicar la estrategia de modelado que promete finalmente entregar una solución robusta y sencilla para conectar distintos star-schemas.
Unified Star Schema (USS)
En resumen, la idea principal del Unified Star Schema (USS) está basada en un concepto muy sencillo para conectar las distintas entidades de datos de un DW. En cambio, de crear una red compleja conectando cada table con su referente, se introdujo una table central (router) que gestionaría todas las conexiones a través de ella.

Figura del libro: The Unified Star Schema.
De esa manera solo hay un tipo de conexión que sería entre las tablas (dimensiones y hechos) y la table central que fue bautizada de “Bridge table”. La “bridge table” se encargaría de obtener los enlaces y relaciones correspondientes a cada tabla. La siguiente figura ilustra un ejemplo de data marts que están desconectados y como sería el modelo utilizando la “bridge table”:

Figura del libro: The Unified Star Schema.
Ventajas para self-service BI
Por self-service BI se entiende la posibilidad de explorar y descubrir los datos en cualquier plataforma de BI moderna, como Tableau, Qlik View / Qlik Sense, Tibco SpotFire, MS PowerBI, etc., por parte de analistas de datos y representantes comerciales.
El problema actual es que los modelos DW basados en el modelado tradicional siempre contienen las conexiones de bucle (a menos que no sea trivial), lo que conduce a la ambigüedad. Es por eso por lo que la plataforma de BI limita las posibilidades de conexiones de tablas entre sí para evitar bucles, llevando a las limitaciones de las posibilidades de exploración de datos o la necesidad de soluciones alternativas en el lado del modelo de datos.
La conversión del esquema tradicional por un esquema USS es que un esquema en estrella simple elimina el conjunto de restricciones impuestas por las plataformas de BI.
Además, el esquema USS ayuda a resolver los siguientes desafíos:
· Bucles
· Fan Trap
· The Chasm Trap
· Uniones de granularidad no conforme
Esos son conceptos presentes en básicamente todos los DW corporativos relativamente complejos y es un desafío para los equipos de modelado que tienen que mantener esos modelos.
Implementación del USS
La “Bridge table” no tiene ningún valor de negocio, es utilizada únicamente para enlazar las tablas y será omitida de los usuarios en las herramientas de explotación.
Seguro que los que trabajan con modelo de datos se están preguntando como sería posible y como “popular” esa tabla.
Para que el USS funcione hay algunas asunciones. La primera es que cada table debe tener una llave primaria (PK) basada en una única columna.
Una vez que todas las tablas sigan a ese requisito, la “bridge table” sería una tabla tipo matriz donde:
· Columnas — Listado de PK de cada tabla del DW + una columna extra llamada “Stage”. Luego, el número de columnas sería igual al número de tablas en el DW + 1
· Filas — el resultado de un “union all” de todas las tablas del DW con únicamente las PKs de cada tabla. Entonces, el número de registros de la “bridge table” sería la suma de todos los registros de todas las tablas del DW
Cargando la “Bridge Table”
Para implementar esa solución obviamente hay que inserir un proceso en la carga de las tablas para rellenar la “Bridge Table”, siguiendo la estructura comentada arriba:
- La columna “Stage” deberá contener el nombre de cada table.
- Cada columna deberá contener la PK y las FKs de cada tabla.
- Los registros que no hay PK para la columna estarán vacíos (NULL).
Esta figura ilustra como quedaría la tabla basada en un modelo de 2 tablas de hecho: Sales Orders y Sales Forecast:
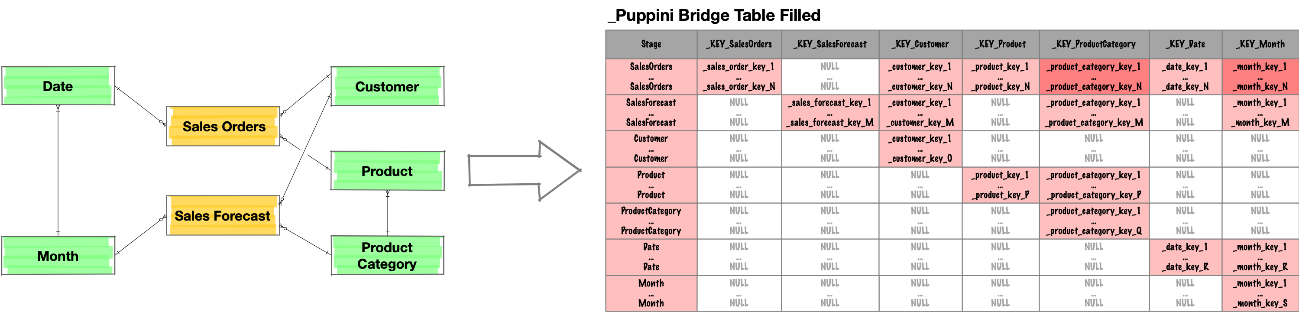
Figura del libro: The Unified Star Schema.
Puede que inserir un proceso en medio de la carga de todas las tablas del DW sea un inconveniente y quizá en tamaño de la tabla asuste un poco, pero actualmente con las posibilidades infinitas de storage y procesamiento ofrecidas por las tecnologías en Cloud, eso no sería un problema.
Consultando datos
¿Una vez cargadas las tablas, como sacamos los datos? Es sencillo.
Toda consulta deberá pasar obligatoriamente por la “bridge table” porque es allí donde están definidos los enlaces entre las tablas. El “join” entre las tablas utilizará las columnas llave correspondientes. Ejemplo: Para sacar total de ventas y forecast por categoría de producto del modelo ejemplo, la consulta sería:
· Considerando que la “bridge table” se llama _PuppiniBridge
select pc.CategoryName,
sum(so.SalesAmount),
sum(sf.ForecastedAmount) from _PuppiniBridge pb
left join SalesOrders so
on pb._KEY_SalesOrders = so._KEY_SalesOrders
left join SalesForecast sf
on pb._KEY_SalesForecast = sf._KEY_SalesForecast
left join ProductCategory pc
on pc._KEY_ProductCategory = pc._KEY_ProductCategory
group by
pc.CategoryName
Una vez que todas las tablas están cargadas, en la capa semántica los desarrolladores deberán conectar todas las tablas a la Bridge table. Seguramente el mantenimiento de la estructura y del modelo quedará mucho más sencillo. Adicionalmente, para los usuarios finales que no tienen que tener conocimientos de modelado de datos, podrán utilizar una solución arrastrando cualquier atributo de cualquier tabla y el resultado siempre será válido.
Conclusión
En el USS, con una solución sencilla solventamos dos grandes típicos problemas en ese tipo de implementación:
1- Los analistas y desarrolladores tendrán un esquema “limpio” y una solución robusta para gestionar
2- Los consumidores de datos no tendrán que preocuparse con “dónde saco la info” o “si combino ese atributo con aquello el resultado es distinto de lo que esperaba”
Según mi experiencia, la solución del USS es idónea para implementaciones de Self-Service BI. Una vez pasado el reto de implementar la “Bridge Table”, los analistas de datos y los consumidores podrían hacer su trabajo en la plataforma de BI concentrándose en los conocimientos y no en los desafíos de conectividad de datos, evitando muchas de las posibles trampas que suelen existir allí.
Autor del artículo
Fernando Vitorino Roldán, senior specialist de Consultoría Tecnológica de Deloitte
Recommended for you
Opens_in_a_new_window