La programación reactiva en Spring Ha sido salvado

Artículo
La programación reactiva en Spring
¿Qué es?
La programación reactiva es un paradigma de programación cuya principal característica es el uso de llamadas asíncronas no bloqueantes siempre que sea posible. Esto incluye no sólo las habituales llamadas a recursos muy lentos a través de la red, sino a todo aquello que sea posible, como las llamadas a base de datos, la gestión de peticiones y en general todo el flujo de llamadas. En este artículo nos centraremos en las herramientas que proporciona Spring.
¿Cómo funciona?
El funcionamiento concreto depende de la implementación. En general se basa en la utilización de un pool de hilos que realizarán todos los procesos. Las tareas a realizar son encoladas y se van asignando a algún hilo libre del pool. En el momento en que tienen que realizar una llamada, esta se realiza de forma asíncrona y el hilo se libera de nuevo al pool para poder ser reutilizado. Cuando la llamada termine, el callback encolará una nueva tarea que, eventualmente, será asignada a algún hilo libre del pool para continuar el procesamiento.
¿Qué cambia al programar?
El principal cambio es que todo se basa en flujos (streams). Se definen distintas piezas que reaccionarán a los datos que le lleguen, transformándolos en nuevos flujos que podrán ser la entrada para otra pieza distinta. Estas piezas reaccionan a los datos que les llegan.
Estos flujos son una abstracción más avanzada que los habituales callback de las llamadas asíncronas. Permiten más operaciones y no necesitan acceder al elemento para continuar definiendo las transformaciones. Además, permiten un encadenamiento de llamadas más legible, evitando por ejemplo tener que hacer callbacks dentro de callbacks.
Al principio es fácil confundir lo que estamos haciendo. Estamos acostumbrados a que al ejecutar nuestro código se tratan los datos, con el flujo reactivo, lo que estamos haciendo en realidad en nuestros métodos es definir el flujo, los pasos que seguirá y qué se realiza en cada uno de ellos. La verdadera ejecución comienza en una fase posterior con la suscripción, en la que se ejecutan cada uno de los pasos por separado, lo que también complica la depuración.
Es importante tener cuidado de no realizar llamadas bloqueantes. Además de arruinar el modelo, podría ocurrir que, si existen muchas de estas llamadas, se bloqueasen todos los hilos, congelando la aplicación por completo.
Una ventaja de la programación reactiva es que las acciones se hacen con flujos, lo que permite que si, por ejemplo, al final de la cadena se limita el número de elementos de la salida, no es necesario procesar todo y después filtrar. Cuando al filtro llegue el número de elementos deseados, se detendrá todo el procesamiento al desuscribirse, evitando los pasos anteriores en la cadena del resto de elementos.
¿Cómo se hace en Spring?
Existen dos librerías principales (junto con muchas otras), RxJava y Reactor. Aunque puede usar la primera, Spring utiliza preferentemente Reactor, basado en los Reactive Streams. En este caso tenemos dos componentes principales en los que pivota todo, Mono y Flux. Estos dos tipos genéricos se diferencian en que el primero gestiona un único elemento y, el segundo, un conjunto de elementos.

Ilustración 1: Flujo Mono
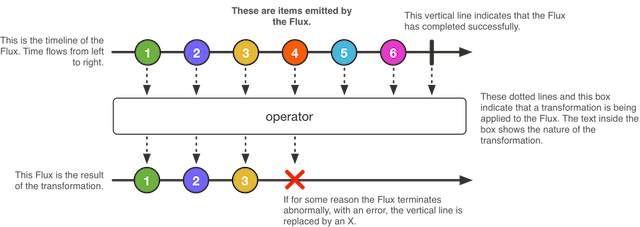
Ilustración 2: Flujo Flux
Estos elementos contienen muchas funciones de agregación, separación, control de flujo, etc.
Spring provee también de una librería web específica para trabajar de forma reactiva: WebFlux. Esta sustituye a la librería habitual para web y trae, por defecto, el servidor Netty en lugar de Tomcat.
A continuación mostramos un ejemplo en Spring de petición REST con programación imperativa y otro con programación reactiva:
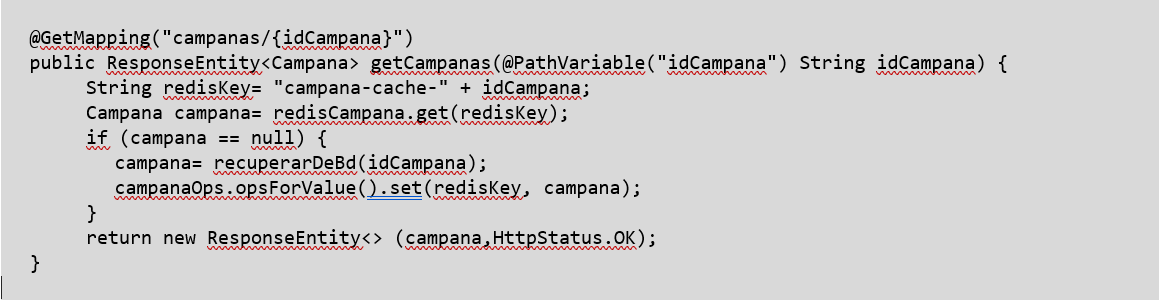

En ambos casos se recupera un elemento de Redis y, si no se encuentra, se recupera de base de datos y se guarda en Redis para futuras referencias. Nos abstraeremos de cómo se recupera el elemento de base de datos, que en el segundo caso devolverá un Mono del elemento.
En el caso reactivo lo que se devuelve en la llamada a get es un Mono. Este no contiene el elemento, únicamente “la referencia” al código que lo recuperará. Será Spring que se suscribirá a este Mono para enviar la respuesta y será entonces cuando se ejecuten las operaciones.
Ambos pueden gestionar el caso de que no exista un elemento en base de datos, en el primer caso lanzando una excepción y, en el segundo, con un Mono.error, que detendrá el flujo.
Estado actual
Para que un sistema aproveche realmente los beneficios de la programación reactiva, debe serlo por completo en todo el stack. Un único elemento bloqueante podría echarlo a perder. Y existe un componente principal en muchas aplicaciones utilizadas hoy en día que tiene serios problemas para ser reactivo: JDBC.
Estos drivers utilizados por las bases de datos, principalmente las relaciones, es eminentemente bloqueante. A día de hoy, son varios los esfuerzos por sustituirlo por soluciones reactivas (ADBA, R2DBC de Pivotal y Fibers de Project Loom), pero todas se encuentran en un estado inmaduro o incompleto, ofreciendo soluciones limitadas en el mejor de los casos.
Existen, sin embargo, soluciones reactivas para otro tipo de bases de datos, las no SQL. Spring ofrece librerías reactivas para Mongo, Cassandra, Redis y Couchbase. También existe soporte para mensajería con Kafka y RabbitMQ, así como para peticiones REST utilizando WebClient en lugar de RestTemplate.
Ventajas e inconvenientes
La principal ventaja de la programación reactiva es la de atender muchas peticiones con un conjunto limitado de hilos, que son aprovechados al máximo. Tienen una mejor y más predecible escalabilidad y, en general, tardan menos tiempo en arrancar y empezar a servir peticiones. En general, también consumen menos memoria y CPU, al hacer un uso más eficiente. Puede utilizar un número fijo de hilos.
Por ejemplo, en una petición web compleja, gran parte del tiempo de procesador se malgasta en esperas, ya sean llamadas a base de datos o a otros servicios. En no pocos casos se supera el 50% de tiempo de procesador en wait. Con el uso de la programación reactiva esta cifra se reduce drásticamente, sacándole mucho más partido a la CPU. El tiempo de respuesta será el mismo o ligeramente superior, pero se podrán atender más peticiones a la vez.
Por contra, el modelo de programación se complica bastante y el código es menos legible, más difícil de mantener y depurar. Se requiere un tiempo de aprendizaje y es más complejo de probar. Otro inconveniente es la falta de librerías reactivas, especialmente en tecnologías con más tiempo en el ecosistema, siendo JDBC el mayor exponente.
Cuándo usarla
La programación reactiva encaja muy bien con arquitecturas de microservicios donde se tienen aplicaciones ligeras y apificadas que deben escalar horizontalmente y en las que podría haber muchas llamadas entre sí. Las aplicaciones web que deben responder muchas conexiones minimizando la latencia son buenas candidatas.
La aplicación de este nuevo paradigma no aportaría una gran diferencia, y sí mayor complejidad, en procesos de uso intensivo de CPU, como criptografía, resolución de problemas matemáticos, ordenaciones, etc. En general, no es recomendable en procesos que no requieran muchas llamadas a base de datos u otros servicios, o en el caso de que estas llamadas no puedan gestionarse de forma reactiva.
Conoce a nuestro experto

Alejandro Ladera
Alejandro es Analista Senior del área de System Development&Integration, en la práctica de DxD de Deloitte. Está especializado en la tecnología Java, en la que cuenta con 5 certificaciones de Oracle y 8 años de experiencia profesional. Ha trabajado, principalmente, en sistemas de venta del sector de transporte para grandes clientes, con los mayores volúmenes de transacciones en España. También ha llevado a cabo con éxito pruebas de stress automáticas en entornos grandes y complejos, así como mejoras de eficiencia con gran impacto.