Artykuł

Data Vault – o co w tym wszystkim chodzi?
Cykl: Oswoić Data Vault | Publikacja #1
Na wstępie - witaj! : ). Niniejszym artykułem otwieram krótki cykl omawiający metodologię Data Vault w sposób – mam nadzieję – przystępny dla każdego, kto ma choć trochę do czynienia z zagadnieniami bazodanowymi. Mam nadzieję uchwycić kluczowe aspekty, włączając w to elementy praktyczne i najczęstsze wyzwania.
Data Vault nie jest pomysłem nowym, a jednak dopiero w ostatnich latach dużo się o nim słyszy. Jednym z powodów może być powszechna migracja do chmury, przy okazji której rewidowane są niewydajne architektury systemów hurtowni danych – zwyczajnie dlatego, że w związku z migracją i tak potrzebna jest przebudowa – więc jest to ku temu dobra okazja. To, co sprawdzało się jeszcze kilkanaście lat temu, dziś nierzadko wymaga rewizji między innymi w związku z poniższymi:
- zmianami podejścia do prowadzenia projektów (powszechnie stosowane metodyki zwinne, przyrostowy rozwój systemów, zrównoleglenie prac, zakres, który ewoluuje wraz z postępami prac itd.);
- wciąż rosnącą ilością gromadzonych danych;
- zmiennością biznesu i reguł biznesowych używanych w transformacjach danych;
- koniecznością ochrony danych wrażliwych (RODO/GDPR);
- obsługą nie w pełni ustrukturyzowanych formatów danych;
- koniecznością obsługi interfejsów typu real-time;
- koniecznością spełniania przeróżnych norm i regulacji - np. związanych z audytem baz danych - narzucanych przez organy kontrolujące daną branżę (np. European Medicines Agency w przypadku branży farmaceutycznej).
..no dobrze, ale co to jest ten Data Vault? : )
..to może najpierw czym nie jest : ) Tak więc Data Vault nie jest tylko rodzajem modelowania struktur danych – choć na pewno jest to aspekt, który najbardziej się wyróżnia. W „pakiecie” dostajemy cały przepis na budowę „sytemu Business Intelligence” – jak to określa autor (Dan Linstedt). System ten jest bardzo dobrze przemyślany i opisany w książce „Building A Scalable Data Warehouse With Data Vault 2.0” – dostaniemy w niej wiele przykładów, próbek kodu SQL czy jakże cenną architekturę referencyjną.
Data Vault adresuje kwestie wymienione powyżej, ponieważ:
- Dobrze się skaluje dzięki genialnemu w swej prostocie podejściu do modelowania – o czym za chwilę;
- Umożliwia przyrostowe budowanie systemu, bez konieczności przepisywania istniejącego kodu – co doskonale pasuje do zwinnych metodyk projektowych;
- Oddziela zupełnie aspekt ładowania danych z systemów źródłowych od tego co z tymi danymi zrobimy przed wystawieniem ich do użytkowników (czyli od reguł biznesowych);
- Umożliwia pełen audyt danych, w tym historyzację „z pudełka”;
- Model budowany jest przy użyciu szablonów, co ułatwia automatyzację procesu tworzenia fizycznych struktur danych (kod DDL) i ładowania danych;
- Jest kompatybilny z podejściem „insert-only” oraz umożliwia równoległe ładowanie danych – a są to kluczowe aspekty w obliczu ilości danych, które trzeba przetwarzać w dzisiejszych czasach, jak i faktem, że wiele współczesnych baz danych nie jest zoptymalizowanych pod kątem operacji „update” (np. Snowflake, który i tak fizycznie robi w tym przypadku odpowiednik „inserta” - kopiuje całą mikropartycję).
..brzmi ciekawie… ale JAK to działa?
..i tu dochodzimy do sedna – czyli fizycznego modelowania danych. Modelowanie wg. Data Vault to pewien typ normalizacji, gdzie główne założenie to rozdzielenie wszystkich danych na Huby (czyli klucze biznesowe), Linki (czyli relacje między kluczami) oraz Satelity (struktury przechowujące atrybuty – dane opisujące klucze biznesowe lub relacje pomiędzy kluczami – wraz z historią zmian). Oprócz tego możliwe są dodatkowe, uproszczone struktury np. na dane referencyjne. Bardzo często na diagramach obrazujących model poszczególne typy obiektów otrzymują ustalony kolor. Nie ma tu określonego standardu, ale najczęściej spotyka się Huby zaznaczone na niebiesko, Linki na czerwono a Satelity na żółto – i tej konwencji będę się trzymać w przykładach.
Model Data Vault dzieli się na dwie główne części:
- Raw Data Vault gdzie przechowywane są dane surowe wraz z pełną historią – tak jak przychodzą z systemów źródłowych, jedynie uporządkowane twardymi regułami (hard rules) tj. typy danych mogą być bezstratnie zmapowane na typy standardowe wybranej bazy danych, możemy się zdecydować na obcięcie pustych znaków z końców stringów itp.
- Business Vault – opcjonalny obszar zasilany z Raw DV, w skład którego wchodzą obiekty (często „wirtualne” w postaci widoków) wymagające zaaplikowania reguł biznesowych. Mogą to być np:
- Dodatkowe Huby ze zdeduplikowanymi kluczami – np. „czysta” lista klientów, gdzie wszelkie duplikaty przychodzące z systemów źródłowych zmapowane są na jeden golden record;
- Dodatkowi Satelici z atrybutami wyliczonymi lub poprawionymi wg reguł biznesowych – np. ustandaryzowane, sformatowane adresy klientów;
- Dodatkowe Linki potrzebne do połączenia wyliczonych Hubów z resztą modelu lub np. Linki reprezentujące relacje nieistniejące explicite w systemie źródłowym, ale np. wykryte przez algorytmy eksploracyjne – np. połączenie klientów z produktami, które wg algorytmu byłyby interesujące dla nich;
- Obiekty techniczne przyspieszające wykonywanie zapytań (np. tabele Point-in-Time / PIT czy Bridge
Łatwo zauważyć, że będziemy tu mieli do czynienia z procesami typu ELT (Extract-Load-Transform), ponieważ najpierw ładujemy dane i robimy ich historyzację w Raw Data Vault a dopiero potem aplikujemy wszelkie „miękkie” reguły biznesowe (tzw. soft rules). Zaletą takiego podejścia jest stosunkowo łatwa implementacja wszelkich zmian logiki biznesowej – zmiany dotykają bowiem warstwy Business Vault, która może być łatwo przebudowana i przeliczona „wstecz” wraz z całą historią danych, ponieważ opiera się o Raw Data Vault, który nie jest dotknięty przez tego typu zmiany.
Poniższy rysunek ilustruje wysokopoziomową architekturę systemu DV i zadania poszczególnych obszarów.
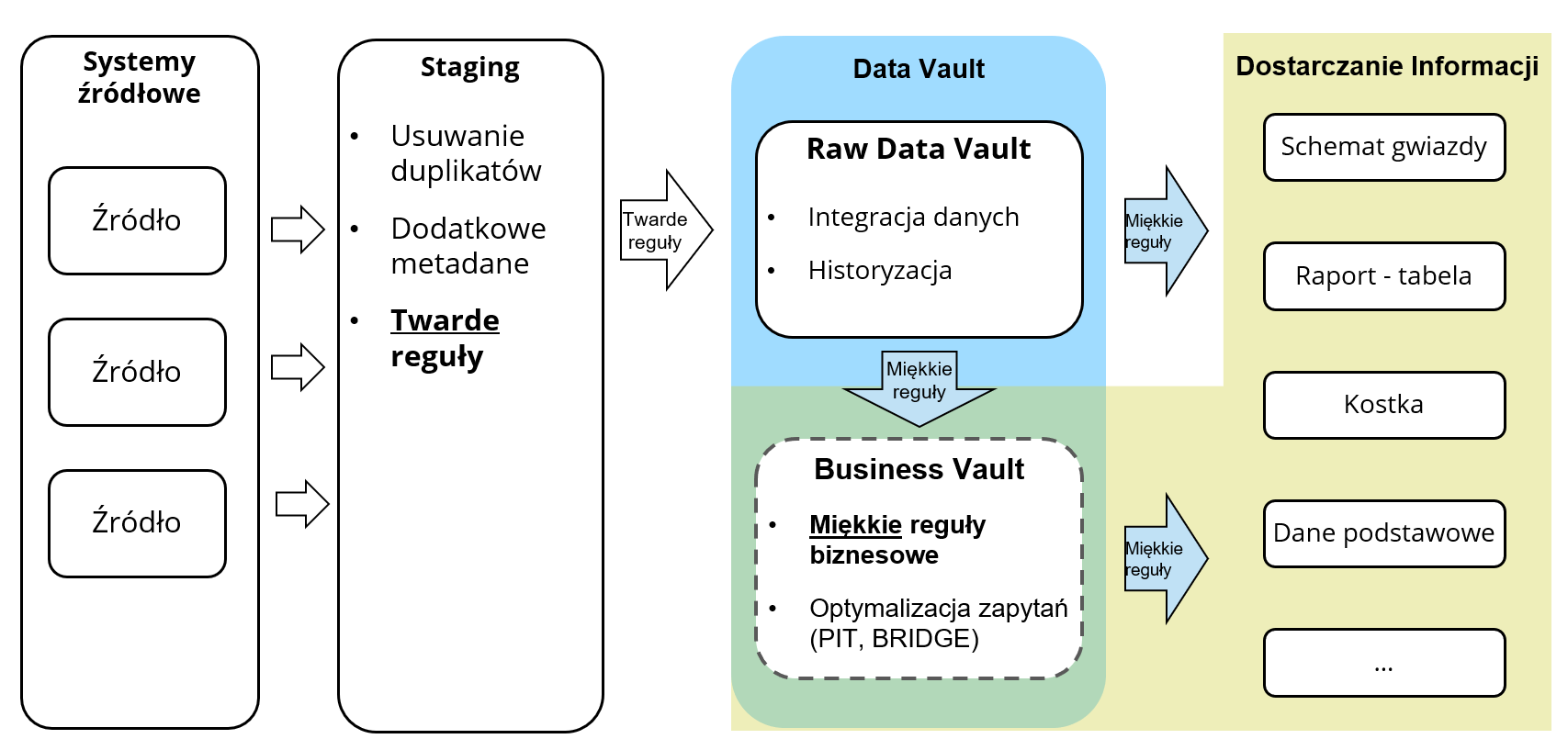
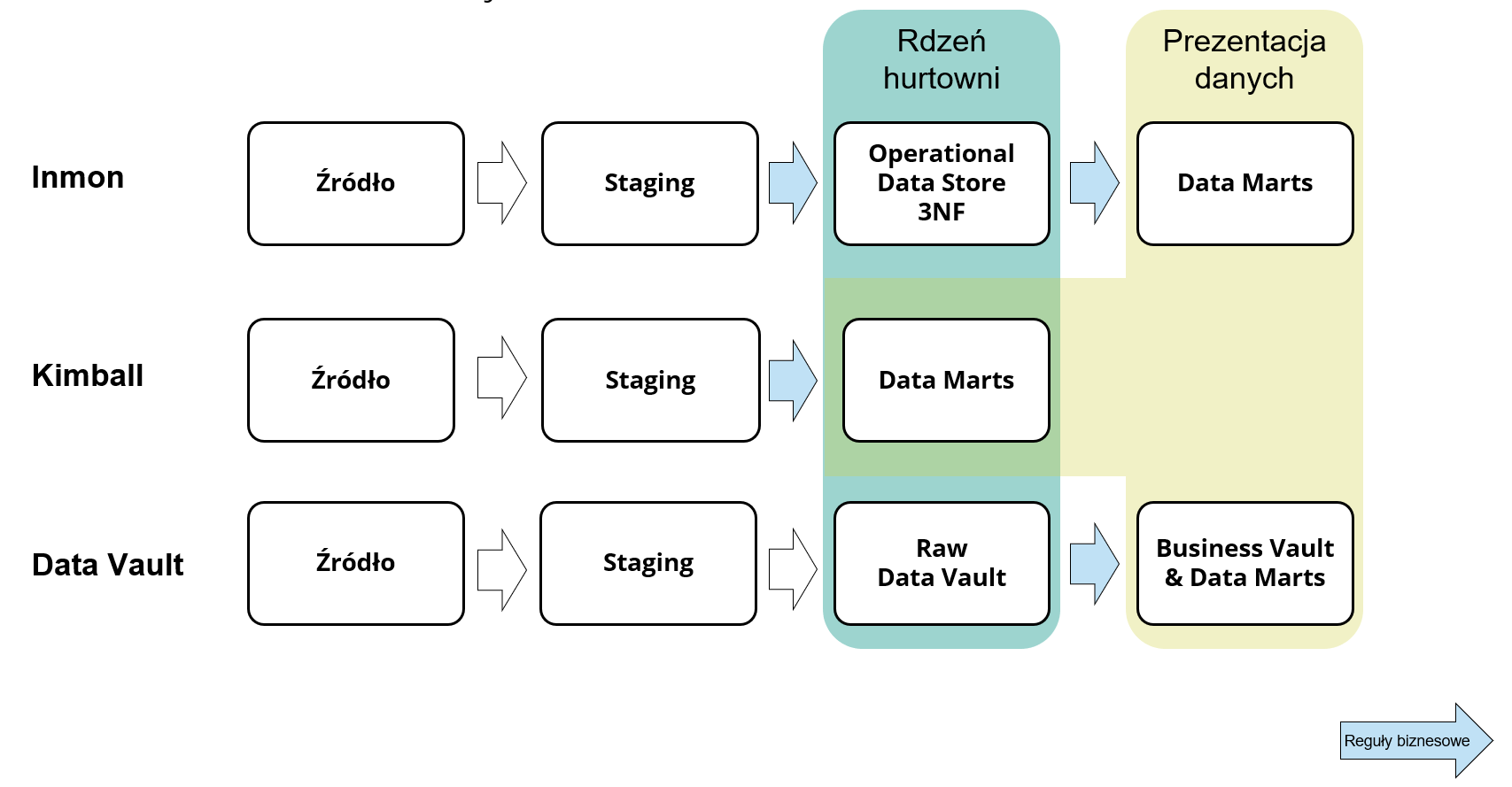
Jeśli porównalibyśmy to podejście z najbardziej popularnymi tj. architekturą Inmona i Kimballa, to właśnie inne podejście do aplikowania reguł biznesowych jest według mnie najistotniejszą różnicą i jedną z głównych zalet Data Vaulta. Różnicę między architekturami ilustruje poniższy rysunek - z szacunku dla języka polskiego nie tłumaczę wszystkich użytych pojęć : )
Potrzebuję przykładu!
Posłużę się prostym przykładem, żeby zobrazować, jak działa Data Vault. Załóżmy, że projektujemy małą hurtownię danych dla szkoły, w której na początku będzie przechowywana informacja o uczniach, nauczycielach i przedmiotach. Dla uproszczenia i ustalenia uwagi załóżmy, że nauczyciele i uczniowie traktowani są jako „osobne byty” (a nie np. jedna encja „osoba”) a szkolna baza danych nadaje im identyfikatory (ID), które będziemy traktować jako klucze biznesowe. Przedmioty natomiast identyfikowane są przez kod i mają przypisaną nazwę i opis. Przedmioty nie oznaczają konkretnych wykładów a jedynie pewien zakres materiału – tj. każdy z nich może być wykładany równolegle przez wielu nauczycieli dla różnych grup uczniów.
Powyższe założenia sugerują, że w naszym przykładzie na pewno będziemy mieć trzy Huby, jako że mamy trzy klucze biznesowe: uczeń – id ucznia, nauczyciel – id nauczyciela, przedmiot – kod przedmiotu

Każdy z tych kluczy ma atrybuty, które dostarczają informacji kontekstowej. Osoby będą miały imię i nazwisko, datę urodzenia, datę zatrudnienia lub startu edukacji, a przedmiot będzie miał atrybuty wymienione przed chwilą – załóżmy, że te dane dostarcza system źródłowy (baza danych szkoły) w poniższym formacie:



Informacje opisujące klucze biznesowe trafią do Satelitów*.
*Przy okazji zabawny fakt – „satelita” jest w języku polskim rodzaju męskiego, natomiast wiele osób mówi o satelitach w rodzaju żeńskim i ja sam nieraz popełniam ten błąd – jednak tutaj będę trzymać się reguł!
Oto nasz model rozwinięty o dane opisowe:
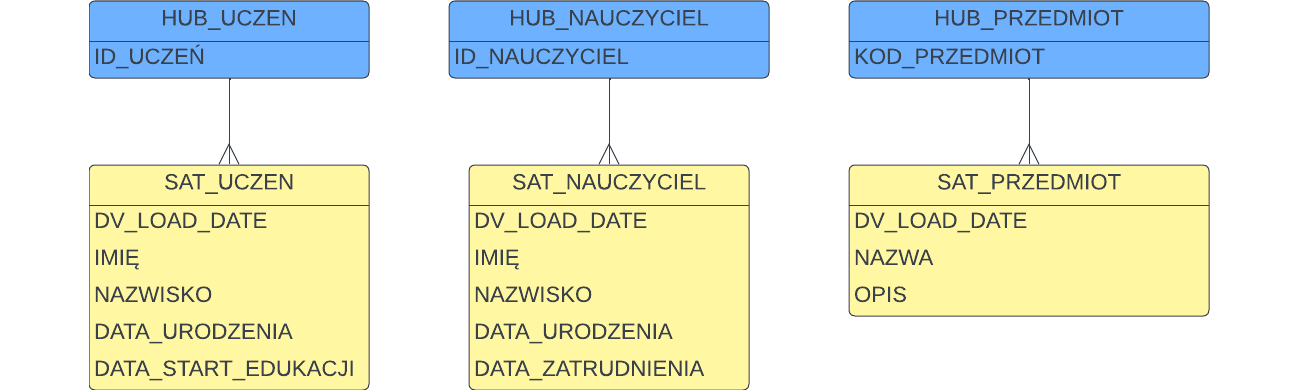
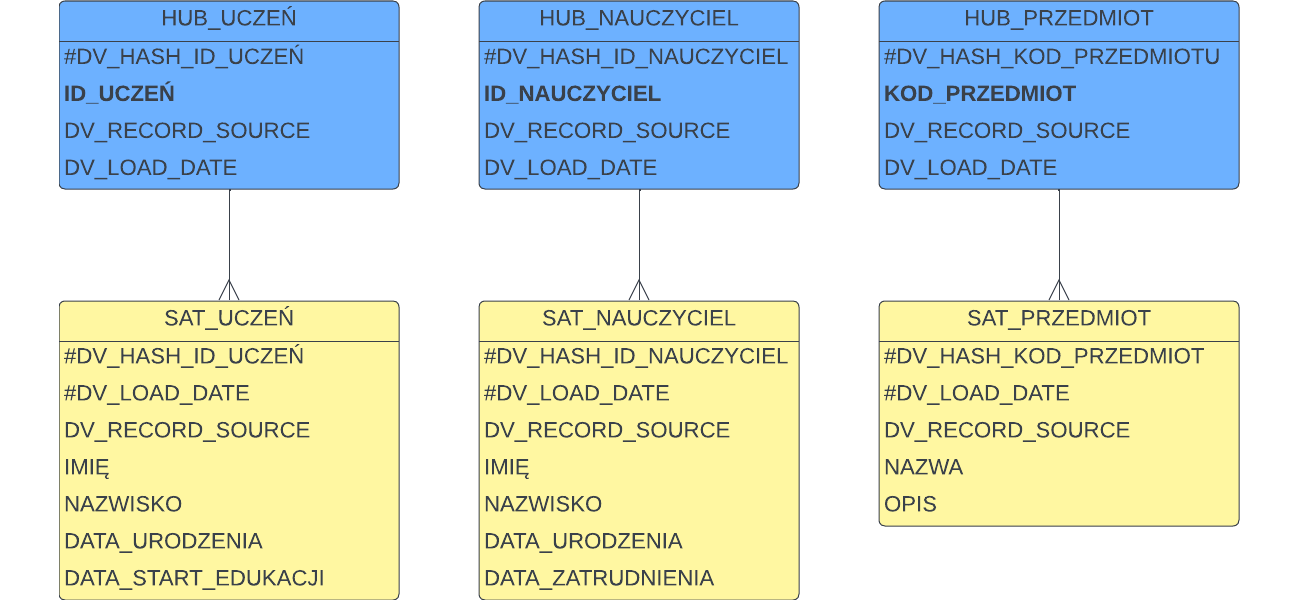
Uważne oko zauważy, że czegoś tu brakuje. Satelity przechowują historię zmian, więc muszą zawierać jakiś znacznik, który rozróżni wszystkie historycznie ładowane rekordy od siebie. Tym brakującym elementem jest data ładowania. Do tego dochodzą inne pola techniczne definiowane przez standard Data Vault 2.0, a przede wszystkim:
- Każdy obiekt ma klucz techniczny lub element klucza, który powstaje przez użycie funkcji skrótu (hash function) na kluczu biznesowym. Tak więc technicznym kluczem w Hubie będzie hash klucza biznesowego (hash key), w Satelicie hash key z Huba + data ładowania a w Linku hash wszystkich kluczy biznesowych z Hubów, które łączy dany link.
- Każdy obiekt ma datę ładowania (load date)
- Każdy obiekt ma źródło ładowania rekordu (record source), które ułatwia analizę problemu w przypadku wystąpienia błędów.
- W satelitach jest hash diff – pole używane do wykrywania zmian -> zamiast porównywać atrybut po atrybucie, wyliczany jest skrót wszystkich atrybutów i porównywany ze skrótem atrybutów z nowego rekordu, który przyszedł ze źródła – nowy rekord jest ładowany tylko w przypadku wykrycia różnicy.
Są też inne pola techniczne jak też dowolność w dodawaniu własnych metadanych – standard nie jest sztywny pod tym względem i można go dostosować do własnych potrzeb. Jednak wyżej wymienione pola są kluczowe.
Załóżmy, że ustalamy konwencję, w której wszystkie pola techniczne mają przedrostek „DV_” a w modelu klucze biznesowe będziemy wytłuszczać, natomiast pola wchodzące do klucza technicznego (primary key) oznaczać będziemy znakiem # dla wyróżnienia. Nasz model będzie wyglądać tak:
Pozostało nam dodać powiązania Hubów między sobą. Załóżmy też, że system źródłowy wystawia dane o ocenach końcowych z przedmiotów w poniższym formacie:

To sugeruje, że w modelu powinniśmy zrobić jeden link pomiędzy uczniem, nauczycielem i przedmiotem a dodatkową ocenę z przedmiotu zapiszemy w satelicie do Linku.
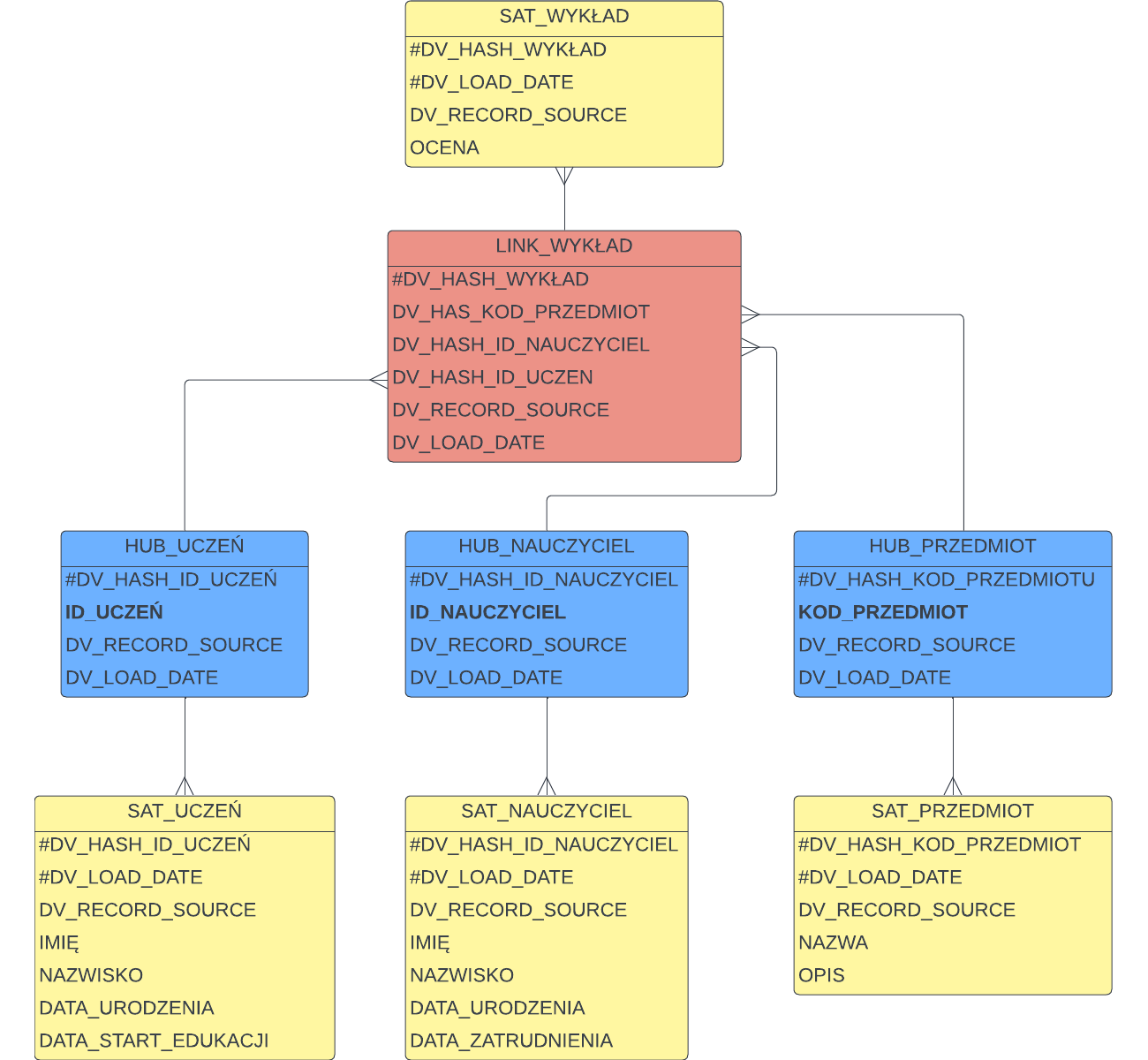
Powyższy model jest zgodny z naszą aktualną wiedzą biznesową – wyróżniamy koncepty które mają nadane klucze biznesowe - i kompatybilny z formatem danych wystawianych przez system źródłowy. Dodatkowo model przechowa całą historię zmian. Na przykład, jeśli w kolejnym ładowaniu któremuś nauczycielowi zmieni się nazwisko, to fakt ten zostanie odnotowany w satelicie SAT_NAUCZYCIEL – pojawi się rekord z nową datą załadowania. Tak samo w przypadku poprawki ocen z przedmiotów – trafią one do satelity SAT_WYKŁAD. Pisząc natomiast zapytanie do hurtowni będziemy musieli określić na który punkt w czasie potrzebne nam dane – np. pytając o najnowszy stan rzeczy będziemy wybierać z Satelitów rekordy z „najświeższą” datą ładowania.
A co z danymi wrażliwymi?
Data Vault umożliwia łatwe oddzielenie danych wrażliwych od pozostałych. Wyobraźmy sobie, że chcemy fizycznie odseparować dane osobowe w naszym przykładzie. Wystarczy, że umieścimy je w oddzielnych satelitach:

Dzięki temu łatwo możemy takie dane fizycznie zidentyfikować (wszyscy Satelici z końcówką „_RODO”), oddzielić, zabezpieczyć i osobno przetwarzać. Natomiast od tego momentu zapytania dotyczące atrybutów chronionych i zwykłych będą musiały wykonać dodatkowe złączenie z Satelitą RODO.
A co gdybyśmy chcieli rozszerzyć model?
Aby pokazać jak łatwo można rozbudowywać model załóżmy, że w kolejnej iteracji projektu dochodzi nam nowy obszar do obsłużenia – będziemy ładować informację o przypisaniu uczniów do klas. Załóżmy, że informacja o uczniach otrzymywana z systemu źródłowego rozszerzona zostanie o informację o klasie do której należy uczeń, klasy identyfikowane będą kodami i będziemy również otrzymywać informacje o klasach takie jak aktualna nazwa, data utworzenia, profil itp. Nie wnikając w szczegóły, nasz model zostałby rozszerzony w następujący sposób:
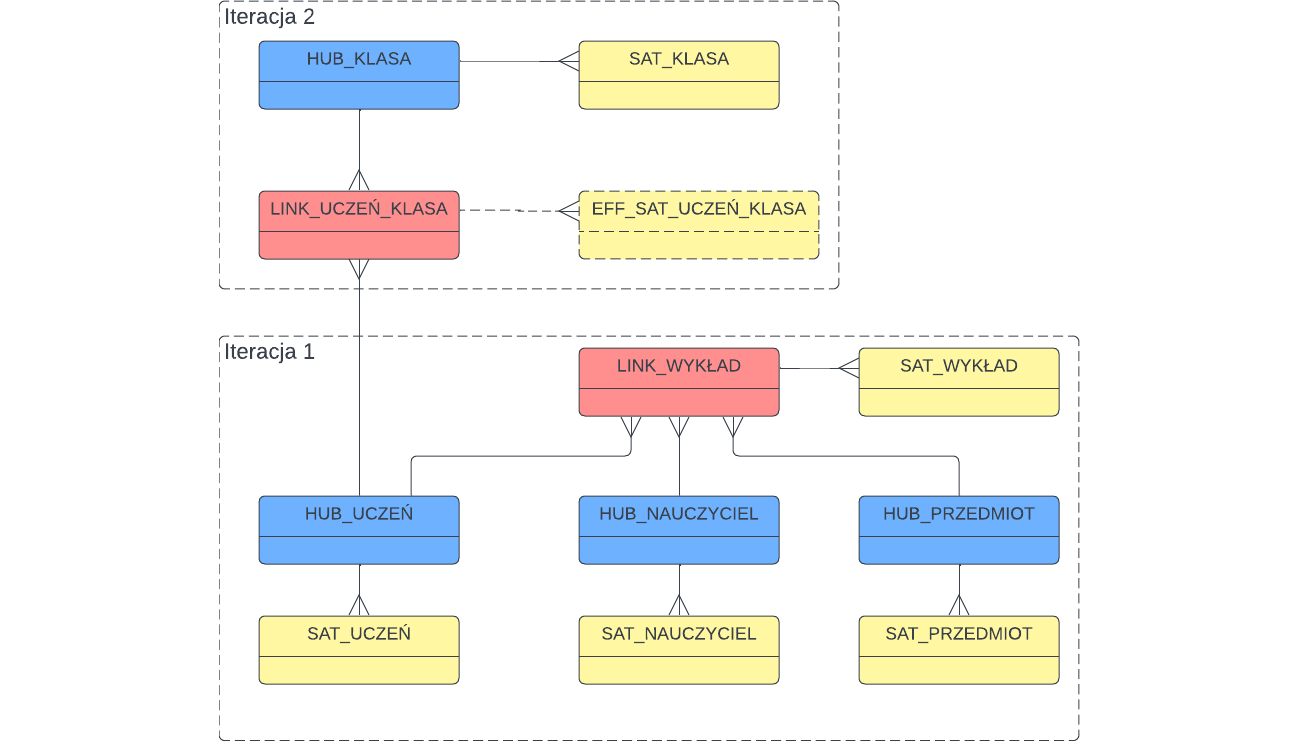
Piękno tego podejścia polega na tym, że iteracja 2 może zostać zaimplementowana bez jakiegokolwiek wpływu na to, co zostało zrobione w iteracji 1. Po prostu dodaliśmy nowe obiekty. Poprzednie procedury ładujące, czy zapytania SQL do obiektów z iteracji 1 nadal działają i nie wymagają jakichkolwiek zmian!
Przy okazji – zauważmy na diagramie dodatkowego Satelitę EFF_SAT_UCZEŃ_KLASA (tzw. effectivity satellite) – służy on temu, żeby śledzić które przypisanie ucznia do klasy jest aktualne – jest to ważne, ponieważ musimy obsługiwać sytuacje, w których uczeń zostaje przeniesiony do innej klasy. Jest to jeden z podtypów obiektów opisywanych przez standard – ale o tym innym razem.
Załóżmy teraz jeszcze jeden increment – dodajemy przypisanie nauczyciela do klasy, czyli informację o wychowawcy – nic prostszego!
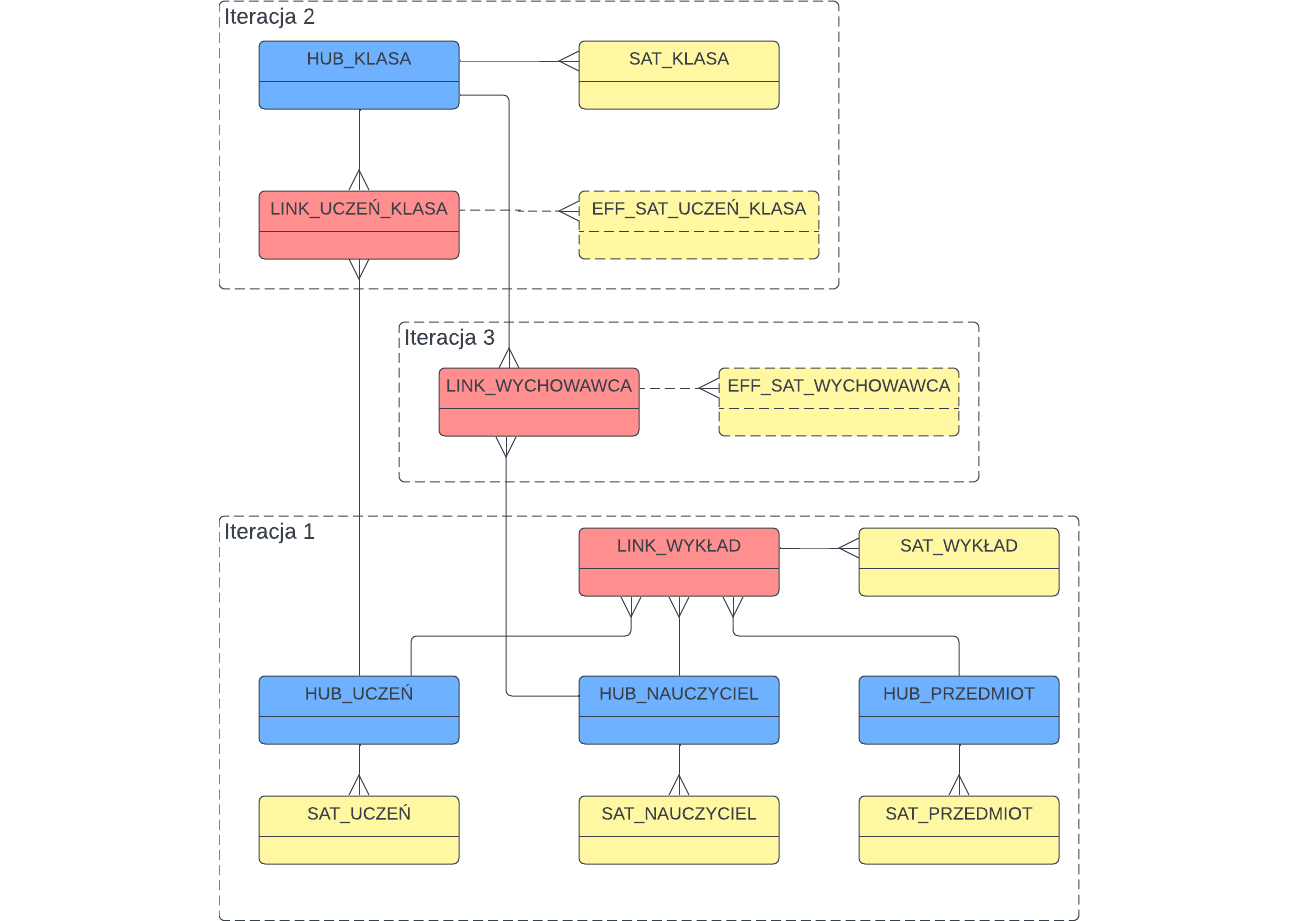
Czy to już wszystko?
..nie. To są tylko podstawy modelowania Data Vault. Trzy wspomniane typy obiektów mają pewne wyspecjalizowane odmiany zoptymalizowane to obsługi szczególnych sytuacji – na przykład Linki transakcyjne, Effectivity Satellites wspomniane wyżej, Satelity multi-active, czy dependent child keys w Linkach obsługujące wymiary zdegenerowane (np. numery pozycji na fakturze). Jest też kwestia obsługi danych referencyjnych, które mogą być utrzymywane w formie „płaskich”, zdenormalizowanych struktur i referowane przez kody biznesowe (np. lista krajów identyfikowanych przez kody ISO, ze standardowymi atrybutami) – ale tutaj mamy dowolność, standard nie wymusza traktowania danych referencyjnych w taki sposób, natomiast jest to bardzo często wygodne.
Jak zatem implementować Data Vault?
Jeśli nie mamy doświadczenia a chcemy zabrać się za implementację samemu - musimy uzbroić się w cierpliwość. Na pewno będzie potrzebny czas na wielokrotne próby i porażki. Wymagane będzie wypracowanie naszych własnych, wewnętrznych standardów definiujących takie aspekty jak:
- Konwencje nazewnicze
- Metadane techniczne, które chcemy utrzymywać
- Podtypy obiektów, które planujemy używać i wszelkie konwencje związane z nimi (np. sposób ładowania Satelitów typu multi-active – bo są tu pewne opcje)
- Podejście do danych referencyjnych
- Obsługę błędnych danych (np. brakujących kluczy biznesowych)
- Szablony do tworzenia obiektów (przydatne do późniejszej automatyzacji)
- Szablony ładowania wszystkich typów obiektów (jak wyżej)
- Sposób implementacji staging area
- Sposób implementacji Business Vault
- Sposoby optymalizacji zapytań (tabele PIT i Bridge)
- ..i wiele innych
..bez tego nasz Data Vault szybko zamieni się w niezarządzalny bałagan.
Druga opcja to skorzystanie z usług doświadczonych (najlepiej certyfikowanych) konsultantów. Będą oni w stanie bardzo przyspieszyć fazę ustalania standardów i zaproponować najlepsze podejście do pierwszych iteracji. Zaletą Data Vault jest fakt, że łatwo jest zaimplementować testowy, mały wycinek całego zakresu projektu i przetestować system end-to-end sprawdzając, czy spełnia założenia i oddając pierwszy, działający kawałek hurtowni klientowi.
Kontakt:

Kontakt marketingowy:

Rekomendowane strony

Cykl materiałów „Wyzwania Chief Data Officerów”
Cykl dedykowany Chief Data Oficerom, w którym opisujemy wyzwania, z którymi CDO mogą się mierzyć oraz przybliżamy sposoby radzenia sobie z nimi