How to train your consultants: Reinforcement Learning in a multiagent game environment has been saved

Article
How to train your consultants: Reinforcement Learning in a multiagent game environment
8 min read
Reinforcement Learning (RL) has recently allowed the development of Machine Learning (ML) models that surpass human ability in areas previously not thought possible. Libraries like TensorFlow Agents (TF-Agents) make powerful RL algorithms accessible. This article will show how developers can use this library to train RL models. In particular, this article will illustrate how code can be extended to a multiagent training scenario, teaching two models to play a simple game simultaneously.
So, what is Reinforcement Learning?
RL is a growing area of research which involves Artificial Intelligence (AI) ‘agents’ learning strategies by interacting directly with an environment. These techniques have recently gained press attention with examples like AlphaZero Go’s victory over the world champion in the game of Goi and the unparalleled Chess strength of AlphaZeroii. What is particularly interesting about these cases is that the models started with no prior knowledge other than the rules of the game they played and finished performing better than human-made models. These models use repeated self-play to iteratively improve and develop their own strategies from scratch, with other interesting examples including Atari gamesiii DOTA 2iv
An important extension of RL is Multiagent RL (MARL), where more than one agent is training in the same environment simultaneously. After all, AI may need to be able to account for other agents, such as other cars in the case of autonomous drivingv. Interestingly, there’s also evidence it can improve performance as found for the game Starcraft vi. When I first started using RL for an Android mobile game I created called Touchdown Tactics, I needed to use MARL to train computer players.
Touchdown tactics
For this, I adapted the only similar approach I could find using TF-Agents from PhD Researcher Dylan Cope . I cover the details of how to get a similar RL or MARL set up below.
Reinforcement Learning and TF-Agents
The basics of RL are quite straightforward, and can be understand with three key foundations, seen in Figure 1 (below)
Figure 1. Foundational Elements of RL

To illustrate the use of RL, the rest of this article will describe how agents learn to play a simple grid style game I’ve created (full code available on github) as shown in Figure 2 (below). In the top left we see our Senior Consultant (SC), and in the bottom right our Analyst (A).
Figure 2. Simple grid style game

They will be racing to a randomly placed ‘goal’ in the grid to secure a new contract and be rewarded with a hearty handshake (restrictions allowing). The agents will see the current grid, and then select an action by simply producing an integer: 1 to move up, 2 to move right, 3 to move down, 4 to move left, a 0 will mean staying still.
TF-Agents classes
Defining a custom class for our agents, MARLAgent
Figure 3: Defining an agent class
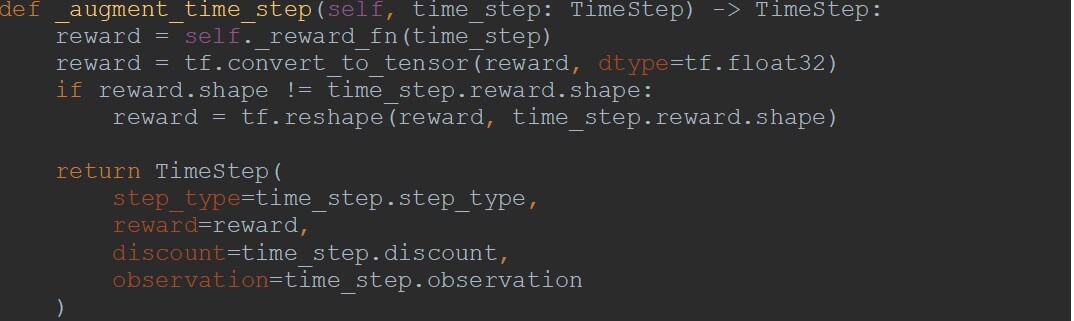
The class inherits from a TF-Agents class DqnAgent, which is used for an RL algorithm called Q learning, which works well in an environment with a discrete action space. This class handles all the key features for our RL agent. I defined the observations it can expect to see from the environment and how it handles the actions it can produce, its neural network, and its replay buffer. I also defined how the agent handles TimeSteps- as mentioned in Figure 1, TimeSteps contain important information and are passed between the environment and agents, for instance the observation of the current state of the game, the outcome of the last move and rewards for an action. The agent class is described in more detail in Figure 4 (below).
Figure 4. Key details of the MARLAgent class

Defining a custom class for the environment
Figure 5. Defining an environment class
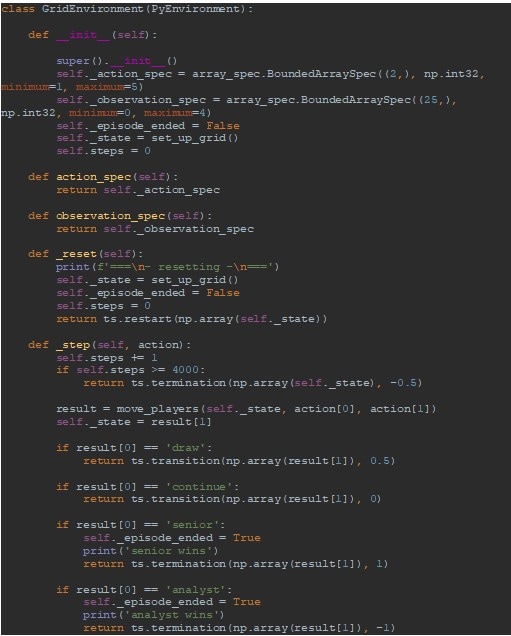
This class, GridEnvironment, sets outs the key features of the environment the agents are playing in. I also defined the shape of observations it will pass to the agents, the actions the environment can expect to receive and crucially what to do with those actions. In this case it calculates the results of those moves in the game and handles that outcome, as described in Figure 6 (below).
Figure 6: Key details of the GridEnvironment class

Note that only one reward per outcome can be defined in this class, as TF-Agents environments are really orientated towards a single agent. Here I will give the rewards we would give to the Senior Consultant (SC) based on the result and define a new reward function to translate those rewards for the Analyst (A).
Defining a custom reward function for the Analyst
Figure 7. Defining a custom reward function for the Analyst

Here I want the reward given to the SC times -1 unless it is 0.5 or -0.5: SC wins A gets -1, if SC loses A gets 1. If they draw, both SC and A get 0.5, if they take too long to reach the goal, they get -0.5.
Initialising our environments and agents
Figure 8. Initialising our environment and two agents
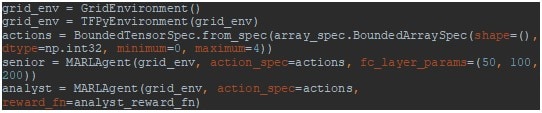
A new environment is created, grid_env, which is then wrapped in a TensorFlow environment. I define an action spec, actions, which tells the agents to return an integer between 0 and 4, and pass this to our agents, SC and A. To get the agents to behave differently you can do so by defining different action specs at this point. Please note that the reward_fn parameter for A is the custom function defined above. I also took the opportunity to customise the agents with slightly different neural nets. Assuming that A is still a few layers short of a deep net when it comes to consulting, I leave it with the default 200 parameters defined in the class and consider SC to have the slightly more sophisticated layers of (50, 100, 200). (Although please note there is no reason to suppose this will actually translate to an advantage in the game!)
Writing a loop to collect data and train agents
I can now write a loop to collect data and train our agents.
Figure 9: Creating a loop to play the grid game
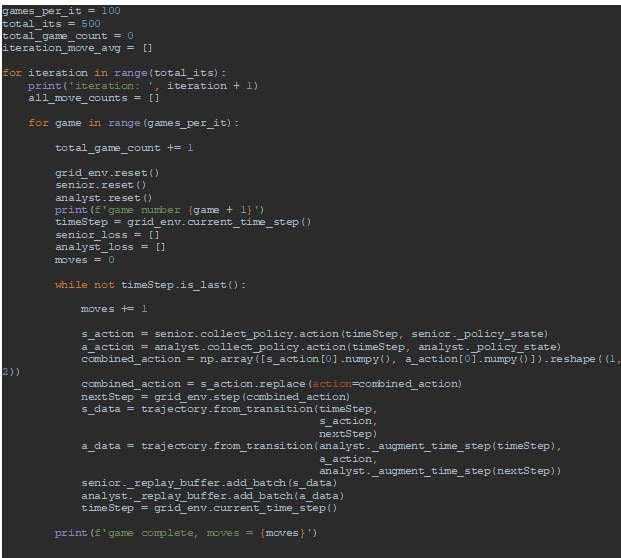
A set number of games are played over a set number of iterations, in this case 500 rounds of 100 games, to get metrics on different iterations and to see how the models progress. At the start of a game I reset the environment and agents and get the current TimeStep from the environment. This holds information about what stage of the game we are at. In the while loop, as long as the TimeStep does not tell us the game has finished, we get an action from our agents. Please note that I am using the collect policy here, which tells the agents I am looking to learn new strategies and collect data. In normal RL you would usually get a single action and pass that straight to the environment, as this is MARL, I will first combine the actions into an array and replace SC’s action with that. This is passed to the environments _step() method and captured the next observation and reward from that action in a new TimeStep, nextStep. For each agent I capture the initial TimeStep, the action taken, and the resulting TimeStep in a single trajectory and add it to the respective replay buffer. At this point I use the _augment_time_step() method for A, to ensure the agent transforms the rewards appropriately. We then update the current TimeStep, and repeat the loop, checking if the game finished. Once it has, we’ll run a quick training loop.
Creating the training loop
Figure 10: Creating the training loop
At the end of each game, for each move made, the agents retrieve the next trajectory from their replay buffer and use the train() method on that data. This contains information about the move made, the impact that had on the game and the reward for that action.
After a game I capture the number of moves it took in a list and store the average number of games for each iteration. If the agents are improving as they train, I will hopefully see the average number of games decrease.
Let’s see what they learned!
Assessing the trained agents
For an example metric, let’s look at the average game length over the 500 iterations.
Figure 11: Average game length over 500 iterations
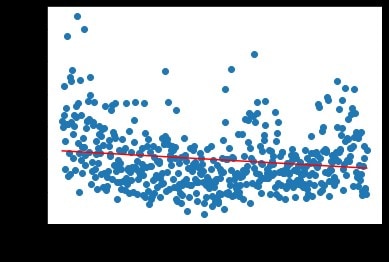
At first the scatter plot may appear confused, but the line of best fit shows a downward slope (-0.106), indicating that the average game length decreases and that the agents were learning a policy to get to the goal more quickly.
To illustrated this further here are three gifs of the agents performing (again gif code on the repo)
Untrained agents playing the grid game
Agents playing after 25000 games
Agents playing after 40000 games
The first gif is the agents without any training, which shows them wandering randomly without knowledge of the goal.
The next two are after 25k and 40k games respectively, and whilst they are yet to learn to beeline straight for it, it is clear that the random moves become more of a stumble in the direction of the goal. Performance could be improved with more training and tweaks to the set up but it looks like the models are slowly learning useful policies here.
For a more complicated example you can see the code I used to train agents for my mobile game here- this makes use of a Soft Actor Critic network for leaning in a continuous action space, and involved agents giving actions of different specs.
So, what did we learn?
Here the concept of RL has been introduced along with some of the basic ingredients needed to develop RL models. I’ve covered how one can quickly set up TF-Agents to use RL algorithms and develop AI for custom problems, as well as how to write classes and functions which to extend TF-Agents to interesting MARL scenarios. Finally I covered an example of training some AI consultants to seek out lucrative contracts in a grid style game – whilst there is some way to go before these AI counterparts compete with any human practitioners, we can see the approach allowed the agents to start to learn policies and improve their performance as they repeatedly played and trained.
References:
1. David Silver et al, Mastering the Game of Go without Human Knowledge, (UCL, 2017), agz_unformatted_nature.pdf (ucl.ac.uk)
2. David Silver et al, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm, (Nature 550, 2017), agz_unformatted_nature.pdf (ucl.ac.uk)
3 Volodymyr Mnih et al, Playing Atari with Deep Reinforcement Learning, (CS Toronto, 2013), dqn.pdf (cs.toronto.edu)
4 Christopher Berner et al, Dota 2 with Large Scale Deep Reinforcement Learning, (arXiv, 2019), 1912.06680.pdf (arxiv.org)
5 B. Ravi Kiran et all, Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems, (IEEE, 2021), Deep_Reinforcement_Learning_for_Autonomous_Driving_A_Survey (researchgate.net)
6 Oriol Vinyals et al, Grandmaster level in Starcraft II using multi-agent reinforcement learning, (Nature 575, 2019), s41586-019-1724-z (nature.com)
7 Dylan R. Cope, Multi-Agent Reinforcement Learning with TF-Agents, (2020), Multiagent-RL-with-TFAgents (github.io)
