




Machine learning and the five vectors of progress has been saved

Machine learning and the five vectors of progress
29 November 2017
What’s keeping leaders from adopting machine learning? Well, tools are still evolving, practitioners are scarce, and the technology is a bit inscrutable for comfort. But five vectors of progress are making it easier, faster, and cheaper to deploy machine learning and could bring it into the mainstream.
Learn more
Explore the Signals for Strategists Collection
Though nearly every industry is finding applications for machine learning—the artificial intelligence technology that feeds on data to automatically discover patterns and anomalies and make predictions—most companies are not yet taking advantage. However, five vectors of progress are making it easier, faster, and cheaper to deploy machine learning and could eventually help to bring the technology into the mainstream. With barriers to use beginning to fall, every enterprise can begin exploring applications of this transformative technology.
Signals
- Tech vendors claim they can reduce the need for training data by several orders of magnitude, using a technique called transfer learning1
- Specialized chips dramatically accelerate the training of machine learning models; at Microsoft, they cut the time to develop a speech recognition system by 80 percent2
- Researchers at MIT have demonstrated a method of training a neural network that delivered both accurate predictions and the rationales for those predictions3
- Major technology vendors are finding ways to cram powerful machine learning models onto mobile devices4
- New tools aim to automate tasks that occupy up to 80 percent of data scientists’ time5
Use of machine learning faces obstacles
Machine learning is one of the most powerful and versatile information technologies available today.6 But most companies have not begun to put it to use. One recent survey of 3,100 executives in small, medium, and large companies across 17 countries found that fewer than 10 percent were investing in machine learning.7
A number of factors are restraining the adoption of machine learning. Qualified practitioners are in short supply.8 Tools and frameworks for doing machine learning work are immature and still evolving.9 It can be difficult, time-consuming, and costly to obtain the large datasets that some machine learning model-development techniques require.10
Then there is the black-box problem. Even when machine learning models appear to generate valuable information, many executives seem reluctant to deploy them in production. Why? In part, because their inner workings are inscrutable, and some people are uncomfortable with the idea of running their operations on logic they don’t understand and can’t clearly describe. Others may be constrained by regulations that require businesses to offer explanations for their decisions or to prove that decisions do not discriminate against protected classes of people.11 In such situations, it’s hard to deploy black-box models, no matter how accurate or useful their outputs.
Progress in five areas can help overcome barriers to adoption
These barriers are beginning to fall. Deloitte has identified five key vectors of progress that should help foster significantly greater adoption of machine learning in the enterprise. Three of these advancements—automation, data reduction, and training acceleration—make machine learning easier, cheaper, and/or faster. The others—model interpretability and local machine learning—open up applications in new areas.
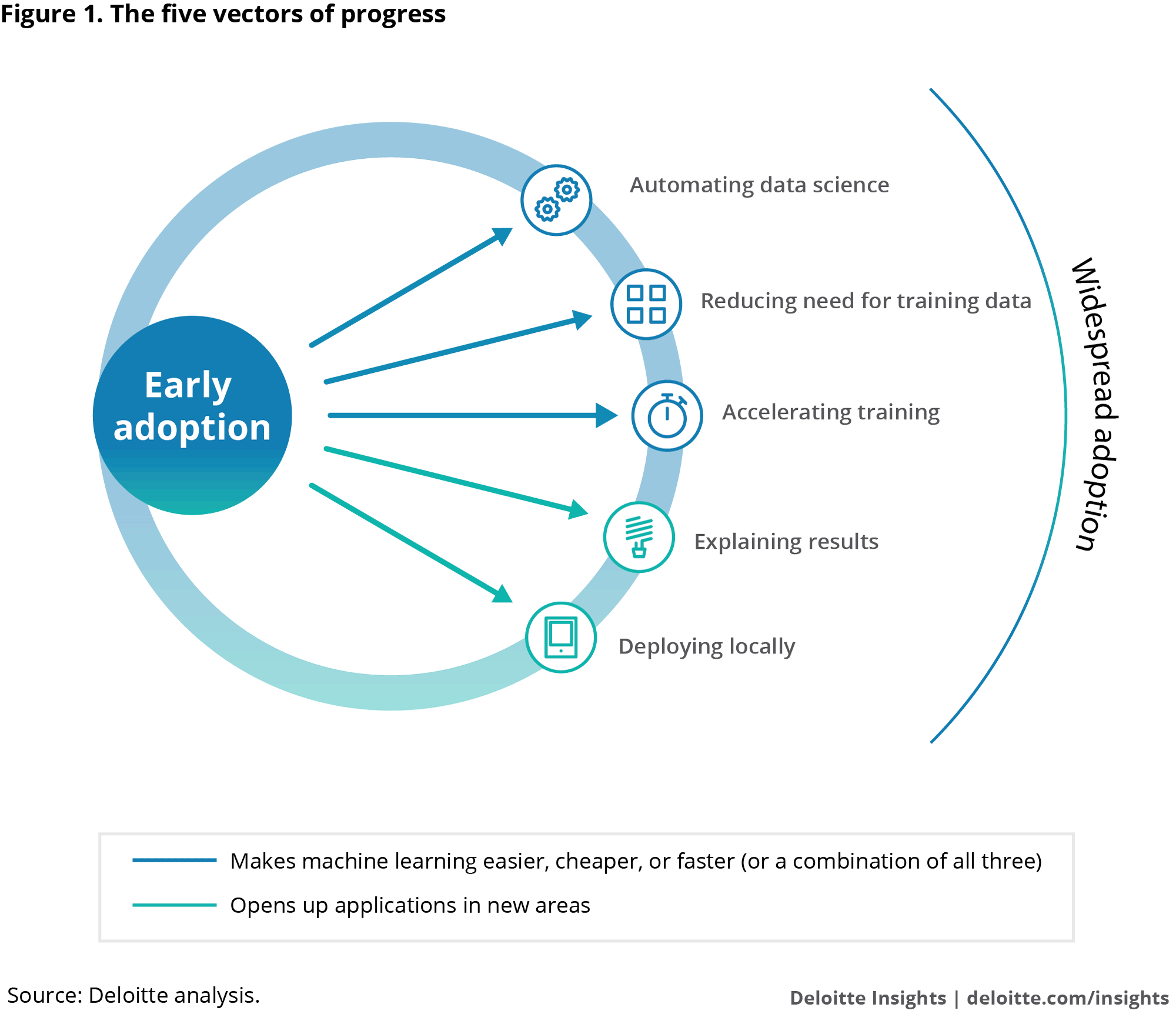
The five vectors of progress, ordered by breadth of application, with the widest first:
Automating data science. Developing machine learning solutions requires skills from the discipline of data science, an often-misunderstood field practiced by specialists in high demand but short supply. Data science is a mix of art and science—and digital grunt work. The reality is that as much as 80 percent of the work on which data scientists spend their time can be fully or partially automated.12 This work might include data wrangling—preprocessing and normalizing data, filling in missing values, for instance, or determining whether to interpret the data in a column as a number or a date; exploratory data analysis—seeking to understand the broad characteristics of the data to help formulate hypotheses about it; feature engineering and selection—selecting the variables in the data that are most likely correlated with what the model is supposed to predict; and algorithm selection and evaluation—testing potentially thousands of algorithms in order to choose those that produce the most accurate results.
Automating these tasks can make data scientists not only more productive but more effective. For instance, while building customer lifetime value models for guests and hosts, data scientists at Airbnb used an automation platform to test multiple algorithms and design approaches, which they would not have otherwise had the time to do. This enabled them to discover changes they could make to their algorithm that increased its accuracy by more than 5 percent, resulting in a material impact.13
A growing number of tools and techniques for data science automation, some offered by established companies and others by venture-backed start-ups, can help reduce the time required to execute a machine learning proof of concept from months to days.14 And automating data science means augmenting data scientists’ productivity, so even in the face of severe talent shortages, enterprises that employ data science automation technologies should be able to significantly expand their machine learning activities.
Reducing need for training data. Training a machine learning model might require up to millions of data elements. This can be a major barrier: Acquiring and labeling data can be time-consuming and costly. Consider, as an example, a medical diagnosis project that requires MRI images labeled with a diagnosis. It might cost over $30,000 to hire a radiologist to review and label 1,000 images at six images an hour. Privacy and confidentiality concerns can also make it difficult to obtain data to work with.
A number of promising techniques for reducing the amount of training data required for machine learning are emerging. One involves the use of synthetic data, generated algorithmically to mimic the characteristics of the real data.15 This can work surprisingly well. A Deloitte LLP team tested a tool that made it possible to build an accurate model with only a fifth of the training data previously required, by synthesizing the remaining 80 percent.
Synthetic data can not only make it easier to get training data—it may make it easier for organizations to tap into outside data science talent. A number of organizations have successfully engaged third parties, or used crowdsourcing, to devise machine learning models, posting their datasets online for outside data scientists to work with.16 But this may not be an option if the datasets are proprietary. Researchers at MIT demonstrated a workaround to this conundrum, using synthetic data: They used a real dataset to create a synthetic alternative that they shared with an external data science community. Data scientists within the community created machine learning models using this synthetic data. In 11 out of 15 tests, the models developed from the synthetic data performed as well as those trained on real data.17
Another technique that could reduce the need for training data is transfer learning. With this approach, a machine learning model is pre-trained on one dataset as a shortcut to learning a new dataset in a similar domain such as language translation or image recognition. Some vendors offering machine learning tools claim their use of transfer learning can cut the number of training examples that customers need to provide by several orders of magnitude.18
Accelerating training. Because of the large volumes of data and complex algorithms involved, the computational process of training a machine learning model can take a long time: hours, days, even weeks to run.19 Only then can the model be tested and refined. But now, semiconductor and computer manufacturers—both established companies and start-ups—are developing specialized processors such as graphics processing units (GPUs), field-programmable gate arrays, and application-specific integrated circuit to slash the time required to train machine learning models by accelerating the calculations and by speeding the transfer of data within the chip.
These dedicated processors help companies speed up machine learning training and execution multifold, which in turn brings down the associated costs. For instance, a Microsoft research team—in one year, using GPUs—completed a system to recognize conversational speech as capably as humans. Had the team used only CPUs instead, according to one of the researchers, it would have taken five years.20 Google stated that its own AI chip, the Tensor Processing Unit (TPU), incorporated into a computing system that also includes CPUs and GPUs, provided such a performance boost that it helped avoid the cost of building of a dozen extra data centers.21
Early adopters of these specialized AI chips include major technology vendors and research institutions in data science and machine learning, but adoption is spreading to sectors such as retail, financial services, and telecom. With every major cloud provider—including IBM, Microsoft, Google, and Amazon Web Services—offering GPU cloud computing, accelerated training will become available to data science teams in any organization, making it possible to increase their productivity and multiplying the number of applications enterprises choose to undertake.22
Explaining results. Machine learning models often suffer from a critical weakness: Many are black boxes, meaning it is impossible to explain with confidence how they made their decisions. This can make them unsuitable or unpalatable for many applications. Physicians and business leaders, for instance, may not accept a medical diagnosis or investment decision without a credible explanation for the decision. In some cases, regulations mandate such explanations. For example, the US banking industry adheres to SR 11-7, guidance published by the Federal Reserve, which among other things requires that model behavior be explained.23
But techniques are emerging that help shine light inside the black box of certain machine learning models, making them more interpretable and accurate. MIT researchers, for instance, have demonstrated a method of training a neural network that delivers both accurate predictions and the rationales for those predictions.24 Some of these techniques are already appearing in commercial data science products.25
As it becomes possible to build interpretable machine learning models, companies in highly regulated industries such as financial services, life sciences, and health care will find attractive opportunities to use machine learning. Some of the potential application areas include credit scoring, recommendation engines, customer churn management, fraud detection, and disease diagnosis and treatment.26
Deploying locally. The adoption of machine learning will grow along with the ability to deploy the technology where it can improve efficiency and outcomes. Advances in both software and hardware are making it increasingly viable to use the technology on mobile devices and smart sensors.27 On the software side, technology vendors such as Apple Inc., Facebook, Google, and Microsoft are creating compact machine learning models that require relatively little memory but can still handle tasks such as image recognition and language translation on mobile devices.28 Microsoft Research Lab’s compression efforts resulted in models that were 10 to 100 times smaller.29
On the hardware end, semiconductor vendors such as Intel, Nvidia, and Qualcomm, as well as Google and Microsoft, have developed or are developing their own power-efficient AI chips to bring machine learning to mobile devices.30
The emergence of mobile devices as a machine learning platform is expanding the number of potential applications of the technology and inducing companies to develop applications in areas such as smart homes and cities, autonomous vehicles, wearable technology, and the industrial Internet of Things.
Prepare for the mainstreaming of machine learning
Collectively, the five vectors of machine learning progress can help reduce the friction that is preventing some companies from investing in machine learning. And they can help those already using the technology to intensify their use of it. These advancements can also enable new applications across industries and help overcome the constraints of limited resources including talent, infrastructure, or data to train the models.
Companies should look for opportunities to automate some of the work of their oversubscribed data scientists—and ask consultants how they use data science automation. They should keep an eye on emerging techniques such as data synthesis and transfer learning that could ease the challenge of acquiring training data. They should learn what computing resources optimized for machine learning their cloud providers offer. If they are running workloads in their own data centers, they may want to investigate adding specialized hardware into the mix.
Though interpretability of machine learning is still in its early days, companies contemplating high-value applications may want to explore state-of-the-art techniques for improving interpretability. Finally, organizations considering mobile- or device-based machine learning applications should track the performance benchmarks being reported by makers of next-generation chips so they are ready when on-device deployment becomes feasible.
Machine learning has already shown itself to be a valuable technology in many applications. Progress along the five vectors can help overcome some of the obstacles to mainstream adoption.