
Artículo
Arquitectura ELK como herramienta de datos abiertos para Aragón Open Data
Open Analytics Data
Arquitectura ELK como herramienta de datos abiertos
ElasticSearch, Logstash y Kibana como arquitectura para la publicación de datos abiertos en un caso real para el portal Aragón Open Data
Aragón Open Data es el portal de datos abiertos del Gobierno de Aragón. El portal está administrado por la Dirección General de Administración Electrónica y Sociedad de la Información y tiene como misión ser el catálogo a partir del cual los ciudadanos y las empresas puedan acceder al conjunto de datos abiertos que publiquen tanto el Gobierno de Aragón, como el resto de instituciones del territorio aragonés que se quieran unir a la iniciativa.
Dentro de este proyecto, nos encontramos con el reto de ofrecer algunas estadísticas de uso de los portales más importantes del Gobierno de Aragón del año en curso. En aquel momento se debía desarrollar un servicio que integrara los datos estadísticos y exponerlos a través de Aragón Open Data como un nuevo servicio.
Para poder dar solución a este reto se aplicó una arquitectura basada en el stack tecnológico ELK (Elasticsearch, Logstash y Kibana). Estos componentes son habitualmente utilizados para la ingestión de información y posteriormente su explotación. Aunque si bien es cierto que estos elementos se utilizan ampliamente en escenario de monitorización, como puede ser la explotación de logs de aplicaciones, también pueden aplicarse a otros tipos de escenarios como el que describiremos a continuación.
Este servicio debía ofrecer de manera pública los datos más útiles en cuanto a la interacción de la ciudadanía con las páginas webs institucionales del Gobierno de Aragón y debía aportar de manera sencilla su uso, acceso e impacto, además, estos datos debían estar disponibles mediante el potencial y la filosofía de los datos abiertos.
Una de las primeras dificultades que nos encontramos fue que en ese momento existían dos fuentes de información posible: algunos portales recogían las estadísticas con Urchin y otros trabajaban con Google Analytics.
Urchin es un software de análisis de estadísticas web desarrollado por Urchin Sofware Corporation. Su cometido es analizar el contenido de los ficheros de log de un servidor web y mostrar la información del tráfico en un portal web. Este proyecto fue adquirido por Google en abril de 2005, naciendo así Google Analytics. Google siguió evolucionando Urchin hasta anunciar la versión 6 tres años después de su compra, y la versión 6.5 en febrero de 2009, cuando integró AdWords.
Urchin 7 fue lanzado en septiembre de 2010 incluyendo soporte para 64bits, una nueva interfaz gráfica y una gran cantidad de nuevas características. El 21 de enero de 2020, Google lanza su última release y deja de dar soporte. Se queda obsoleto y se queda como producto único Google Analytics.
¿Y qué pasa con aquellas instancias de Urchin que siguen ejecutándose? Se quedan sin soporte.
Con la llegada de Google Analytics se eliminó la necesidad de una infraestructura como base de ejecución, lo que conlleva su mantenimiento y soporte, que a partir de ese momento corre a cuenta de Google.
Por otro lado, Google Analytics ofrece información agrupada del tráfico que llega a los sitios web según la audiencia, la adquisición, el comportamiento y las conversiones que se llevan a cabo en el sitio web.
Se pueden obtener informes como el seguimiento de usuarios exclusivos, el rendimiento del segmento de usuarios, los resultados de las diferentes campañas de marketing online, las sesiones por fuentes de tráfico, tasas de rebote, duración de las sesiones, contenidos visitados, etc...
Los datos procedentes de Urchin y Google Analytics poseen distinta estructura. Y eso supuso un problema a la hora de analizar y proponer una solución técnica. En ese punto el objetivo se marcó en integrar información de datos métricos con diferente procedencia y ser capaces de homogeneizarlos.
Uno de los problemas que se tuvieron que afrontar fue la inestabilidad del producto Urchin ejecutado en entornos on-premise. Esta inestabilidad podía producir, y produjo, la inexistencia de información durante ciertas franjas temporales.
Otro requisito de esta integración fue la necesidad de explotar los datos estadísticos, esto significaba exponer los mismos datos, en un estado lo más puro posible, para que se consideraran datos abiertos y pudieran ser consumidos por terceros (ciudadanos, empresas, etc…).
El objetivo estaba fijado, pero la idea del cliente era que además él mismo pudiera gestionar estos portales y añadir nuevos a futuro, o desactivar los que ya no fueran necesarios.
Ante esta situación tuvimos que proponer una solución tecnológica a la altura de las circunstancias, y como no es difícil adivinar con el tema de este artículo, la solución escogida fue el stack ELK (ElasticSearch, Logstash y Kibana), un pack de tres herramientas Open Source.
Logstash es un pipeline de procesamiento de datos del lado del servidor que ingesta datos de una multitud de fuentes simultáneamente, los transforma y luego los envía a un “escondite”, como ElasticSearch.
Tuvimos que utilizar Logstash para homogeneizar los datos procedentes de Urchin y Google Analytics antes de ser indexados, y en un futuro poder añadir más fuentes de datos si fuera necesario, bajo una misma estructura.
ElasticSearch es un motor de búsqueda y analítica. Debido al volumen de datos que generan las métricas procedentes del tráfico web, de varios portales y que se tenía previsto que se fueran incorporando más, era obligatorio utilizar una herramienta de indexación para “ordenar” los datos.
Kibana permite a los usuarios a visualizar los datos en cuadros y gráficos con ElasticSearch. Con los datos almacenados en índices y disponibles para ser consultados en tiempo real, Kibana ofrecía una manera fácil y rápida de convertir estos datos en gráficas.
Para completar el objetivo de explotación de datos en formato abierto y facilitar la comunicación entre Google Analytics y Logstash, se pensó en desarrollar una API en Python para consumir y exponer estos datos.
El proceso de incorporar los datos, y mostrarlos mediante un dashboard comienza en la homogeneización de los datos, lo que conlleva una transformación para conseguir un resultado común y legible, independientemente del origen, y poder exponerlo en el portal de Aragón Open Data a través del servicio de Open Analytics Data (https://opendata.aragon.es/servicios/analytics).
Para ello se propuso la siguiente arquitectura:

- En un primer paso se definieron una serie de pipelines en Logstash para transformar los logs de Urchin a una estructura común. A día de hoy este elemento se ha eliminado debido a que todos los portales se han migrado o van a migrar a Google Analytics.
- Para extraer los datos de Google Analytics se desarrolló una API en Python. Así, a través de esta capa, se pudo controlar cualquier modificación o evolución en estos servicios.
- Actualmente, en las pipelines de Logstash, se está utilizando los servicios expuestos a través de la API. Estas pipelines no dejan de ser unos ficheros de configuración, donde se utiliza un lenguaje similar a bloques de código de programación simplificado.Estos bloques definen filtros o plugins para ser aplicados sobre los datos. Por ejemplo, para las llamadas a la API se tuvo que configurar un plugin llamado Http_poller.
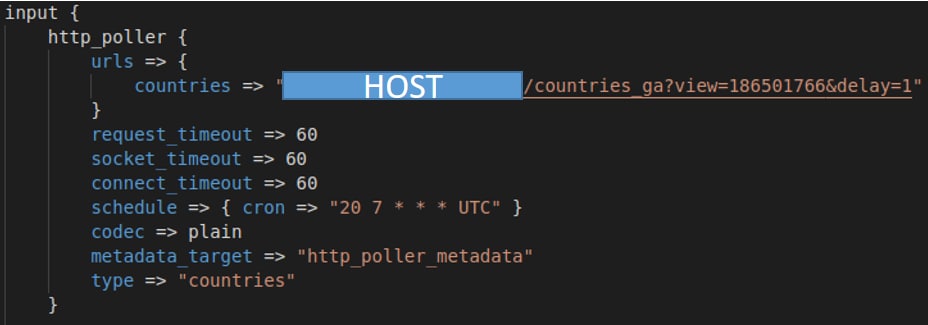
Además, se fijaron unas constantes de petición, del tipo request_timeout, socket_timeout, connect_timeout y se planificó para que se ejecutara en un horario fijado.
A parte de esto, en las pipelines se definieron distintos filtros, mutaciones, cambios de tipo de dato, etc., a modo de proceso ETL (Extract-Transform-Load), para dar forma al dato resultado.
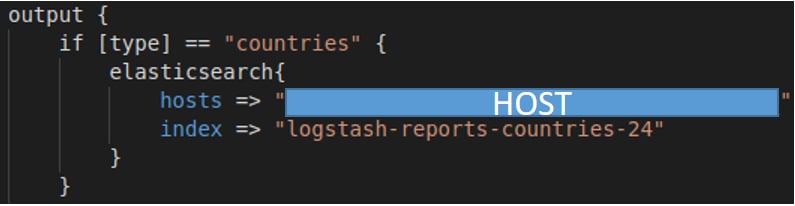
4. En el mismo fichero de configuración se definieron unos output, para cada uno de los tipos de estadística. En este elemento se detalla la instancia y el índice de ElasticSearch, donde almacenar el dato final:
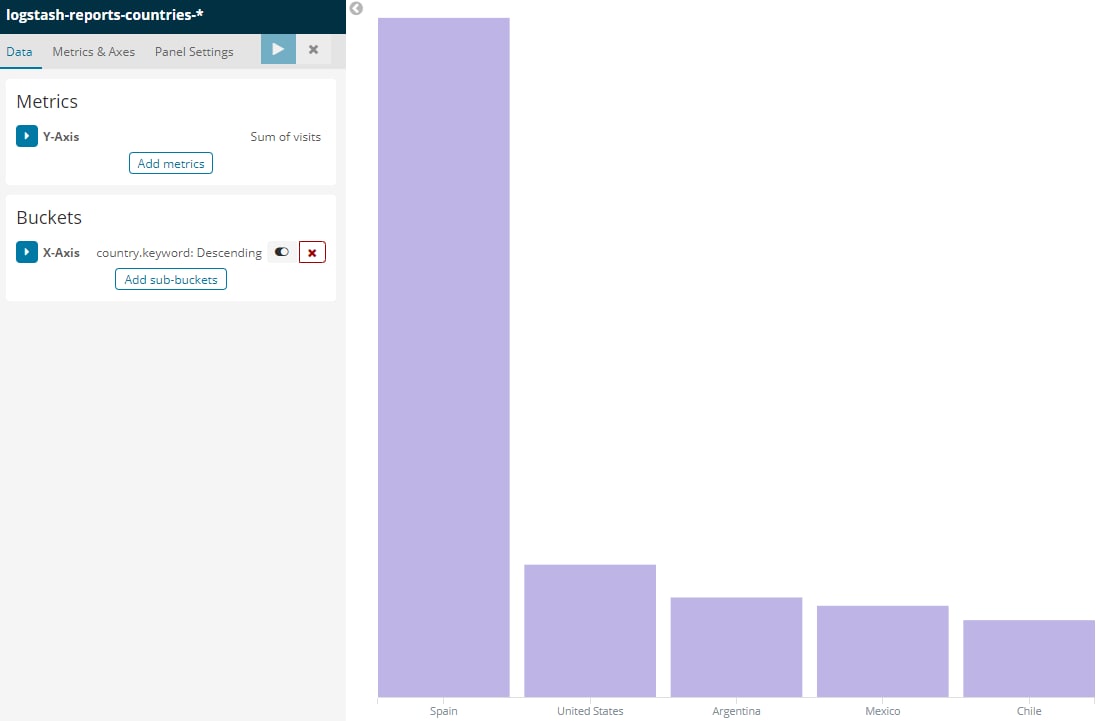
5. Cuando los datos fueron indexados en ElasticSearch, desde el dashboard de la instancia implementada de Kibana, se consumieron estos índices y se crearon las gráficas que se necesitaban como requisito del proyecto:
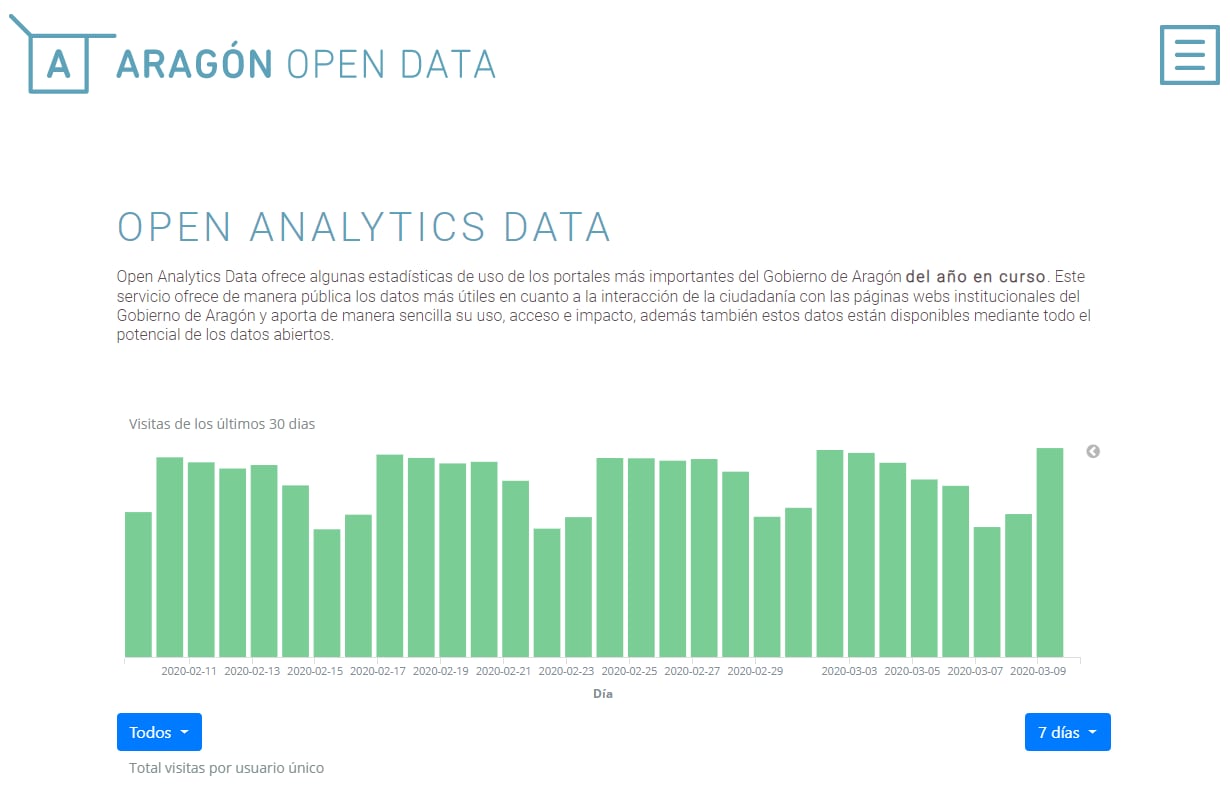
Una vez que se crearon todas las visualizaciones solicitadas, se desarrolló un componente en Angular para embeber estas gráficas de Kibana y que se pudiera visualizar desde el servicio de Analytics Data (https://opendata.aragon.es/servicios/analytics), dentro del portal de datos abiertos del Gobierno de Aragón:

En resumen, el stack ElasticSearch, Logstash y Kibana se utiliza para el desarrollo de soluciones de monitorización por logs, pero encaja perfectamente como solución a uno de los problemas que puede surgir en arquitecturas en las que se desea gestionar datos estadísticos.
La implementación del stack es sencilla, escalable y no requiere de un esfuerzo importante como utilizar otras herramientas como Kafka o similar.
Si el proyecto es de datos abiertos es una buena decisión trabajar con el stack entero. Con los resultados obtenidos de la arquitectura es una buena aproximación, aunque solo se tenga una fuente de origen, ya que ofrece la posibilidad de escalar y ampliar las fuentes y también garantiza la capacidad de modificación de la estructura.

Gabriel Alcober Fuertes
Jefe de Equipo en DXD
Gabriel inició su carrera profesional en 2011, y durante este tiempo ha participado en proyectos con gran diversidad de tecnologías. Ha trabajado en proyectos Salesforce y Java, y en los últimos tres años ha trabajado en desarrollos enfocados a datos abiertos y web semántica.

