
Artículo
Recolección automática de datos abiertos
Harvesting Unizar - Aragón Open Data
Federación de datos abiertos mediante la utilización de un plugin de CKAN en un caso real de Aragón Open Data.
Aragón Open Data es el portal de datos abiertos del Gobierno de Aragón. El portal está administrado por la Dirección General de Administración Electrónica y Sociedad de la Información y tiene como misión ser el catálogo a partir del cual los ciudadanos y las empresas puedan acceder al conjunto de datos abiertos que publiquen tanto el Gobierno de Aragón, como el resto de instituciones del territorio aragonés que se quieran unir a la iniciativa.
La Universidad de Zaragoza (Unizar) quiso colaborar ofreciendo sus conjuntos de datos para ser publicados en el portal de datos del Gobierno de Aragón. Desde un primer momento se decidió que se partiría de un conjunto reducido de datasets de prueba que se intentarían recoger de su plataforma: Zaguan (https://zaguan.unizar.es).
Estos conjuntos de datos debían ofrecerse de manera pública a través de Aragón Open Data y debían ser actualizados periódicamente según se fueran actualizando desde la Universidad de Zaragoza. Los datos de Aragón Open Data están almacenados o referenciados en CKAN.
Aragón Opendata está basada en distintas piezas software en diferentes tecnologías, pero todas se articulan entorno a una pieza central que se considera el corazón del proyecto. Esta pieza central es un portal de gestión de datos abiertos basado en el software Opensource CKAN.
CKAN (https://ckan.org/) es una herramienta para crear portales de datos abiertos, que permite administrar y publicar conjuntos de datos. Se utiliza en gobiernos nacionales y locales, instituciones de investigación y otras organizaciones que recopilan muchos datos.
Una vez que se publican los datos, los usuarios pueden usar sus funciones de búsqueda por etiquetas, categorías o publicadores para navegar y encontrar los datos que necesitan, y obtener una vista previa usando mapas, gráficos y tablas, ya sean desarrolladores, periodistas, investigadores, ONG, ciudadanos o incluso su propio personal.
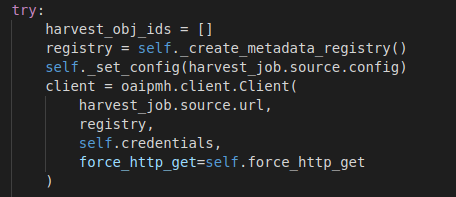
Como alternativa se valoró la conexión a través de OAI-PMH. El protocolo OAI para la recolección de metadatos (OAI-PMH), define un mecanismo para la recolección de registros que contienen los metadados de los repositorios. El OAI-PMH ofrece a los proveedores de datos una opción técnica sencilla para poner sus metadatos a disposición de servicios basados en los estándares abiertos HTTP y XML.
A esta técnica se le llama federación de datos, que es una técnica de integración de datos que permite acceder a diferentes entornos de origen de datos con una visión común, como si en la práctica fuese una sola base de datos. Un elemento clave por tanto es el catálogo de datos común, que se mantiene para poder localizar los datos entre diferentes fuentes.
La federación de datos permite otra funcionalidad muy importante y es que los distintos metadatos y colecciones de un portal pueden ser integrados en otros portales mediante procesos automáticos. En este caso concreto Aragón Opendata es el encargado de incorporar distintos conjuntos de datos desde distintas fuentes: Federación de otros portales/sistemas como el caso de Unizar, integración de datos mediante referencias a urls, integración mediante APIs, ingestión de datos, ficheros locales, entre otras.
A su vez, el portal datos.gob.es es el portal a nivel nacional que aglutina toda la información de los portales opendata de las distintas comunidad autónomas e instituciones públicas nacionales. Este portal mediante federación de datos se interconecta con Aragón Opendata de forma que cualquier conjunto publicado (por cualquier medio) se incorpora de manera automática al portal datos.gob.es. Del mismo modo data.europa.eu federa este portal nacional y lo integra en un portal de ámbito europea que agrupa información de distintos países.
Mediante este mecanismo de federación es posible generar una estructura jerárquica y permitir que los datos generados en sus orígenes automáticamente se propaguen por toda la red de datos abiertos.
Volviendo al caso concreto de Unizar, mediante la federación de datos por el protocolo OAI-PMH se incorporan los datos de Unizar al portal Aragón Open Data con la capacidad automática de incorporar nuevos conjuntos de datos que sean publicados en el origen.
Del mismo modo, cuando esta información es recolectada se incorpora como parte del conjunto de datos manejado por Aragón Opendata que será propagado al nivel superior de datos.gob.es mediante la federación existente junto con otros datos publicados.
Una vez recolectados, debían estar disponibles para que, a su vez, otros portales de datos abiertos (datos.gob.es y data.europa.eu). Para que esto sea posible es necesario generar un fichero de metadatos DCAT/RDF.
Para que esta federación sea posible es necesaria la publicación de un fichero de metadatos en un formato previamente acordado, y que es un estándar de facto en este escenario, denominado DCAT/RDF.
Este fichero contiene, de manera estructurada, el contenido de los datasets almacenados o referenciados en CKAN. Gracias a DCAT, esta entidad puede proporcionar descripciones (en RDF) identificando esos ficheros como un catálogo (dcat:Catalogue), en el que se describe cada dataset en particular (dcat:Dataset) cuya temática se identifica a través de elementos (skos:Concept) de un vocabulario controlado, una taxonomía, etc…
Al final, estos ficheros RDF, se utilizan como endpoint para ser consumidos por otros portales de datos abiertos. En el caso de Aragón Open Data, se expone el catálogo de datos abiertos en RDF para que Datos Gob lo consuma, y a su vez, Data Europa apunta al RDF del anterior.
CKAN es un software de código abierto, con una comunidad activa que desarrollan y mantienen el core de la tecnología. CKAN es modificado y extendido por una comunidad aún mayor de desarrolladores que contribuyen a una creciente biblioteca de extensiones de CKAN.
Una de las extensiones más utilizadas y demandadas dentro de la comunidad es una llamada ckanext-harvest, que permite añadir fuentes de datos externas a CKAN, de tal modo que periódicamente la plataforma se conectará a dichas fuentes de datos para extraer las descripciones de los recursos que contienen y almacenarlas en el propio CKAN. De este modo, la información base reside en la fuente de datos original y el portal de datos abiertos únicamente mantiene una copia automática de los recursos, evitando así duplicidades y costes de mantenimiento de la información.
En nuestro caso, utilizamos este plugin como base de un desarrollo personalizado que se conectaría periódicamente, mediante OAI-PMH, a los conjuntos de datos de Unizar. Así, junto con la herramienta interna del sistema operativo, CRON, podríamos ejecutar tareas de recolección planificadas.
Por lo tanto, la solución tecnológica que se propuso fue desarrollar una evolución del plugin ckanext-harvest, oficial de la comunidad de CKAN, y realizar la integración oportuna con Zaguan de la Universidad de Zaragoza. Este plugin lo tuvimos que adaptar y añadir al proceso de datos abiertos del portal de Aragón Open Data.
Para ello se propuso la siguiente arquitectura:
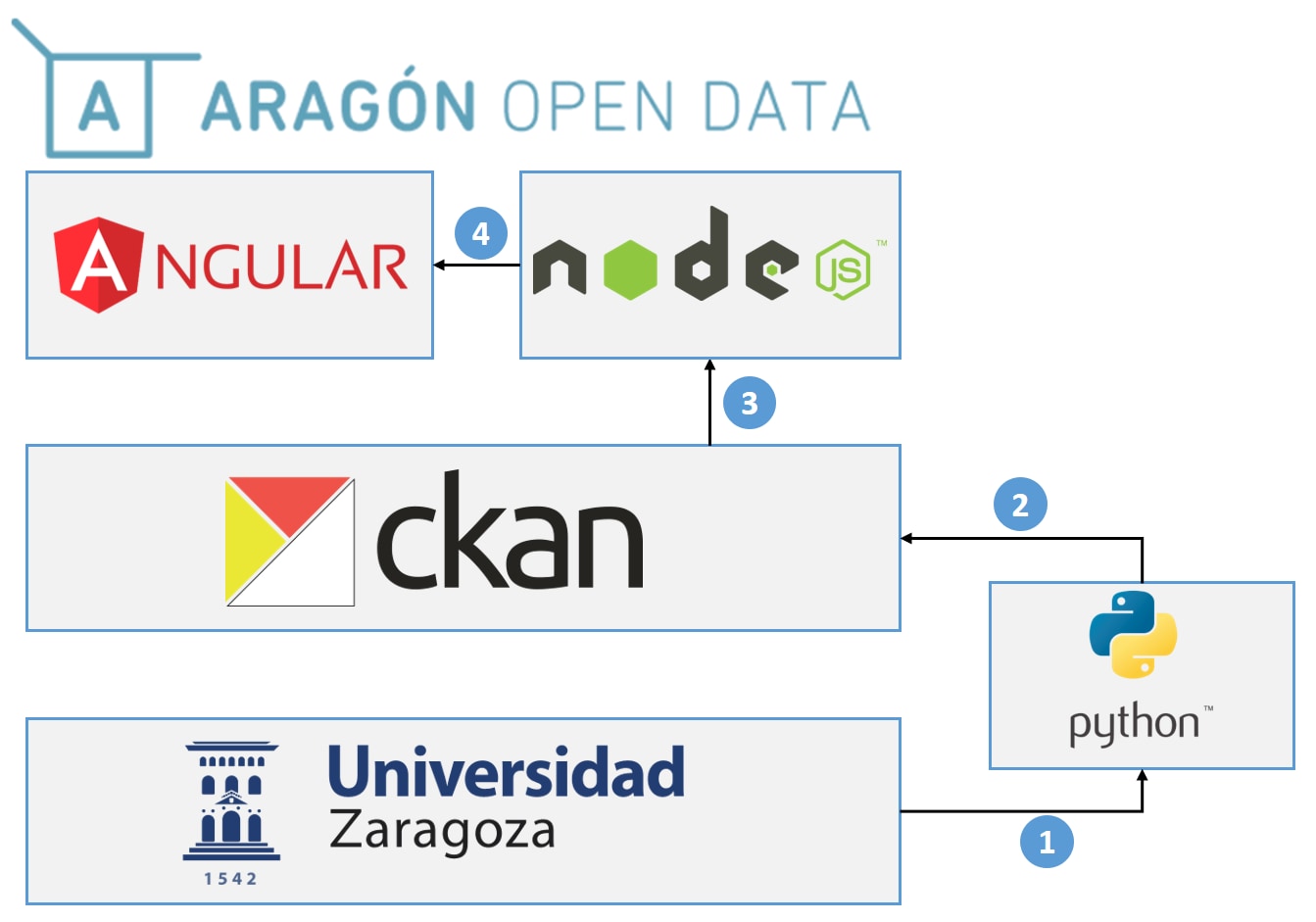
- En un primer paso se desarrolló, en tecnología Python, una extensión de harvesting para CKAN. La base era la mencionada anteriormente en este mismo post: ckanext-harvest, y se tuvo que adaptar la extensión con la nueva conexión de OAI-PMH y modificar la estructura que venía definida por el DCAT y Unizar. En este paso se consumen los datos de Unizar y se homogeneizan.
2. Una vez que el plugin genera los metadatos bajo la estructura definida, se cargan los datos en CKAN. Los recursos no se almacenan en la infraestructura de Aragón Open Data, sino que se guardan las referencias a los ficheros origen
3. Con los datos disponibles en CKAN, se modificó la generación del catálogo de datos en RDF, para que Aragón Open Data pudiera ofrecer los datos de Unizar con el publicador correspondiente, en este caso Universidad de Zaragoza, en vez de Gobierno de Aragón. Este RDF es publicado y consumido por cualquier usuario o servicio de harvesting.

Además, la capa backend de NodeJS, a través de la API de CKAN, consume los datos y los facilita a la capa de visualización.
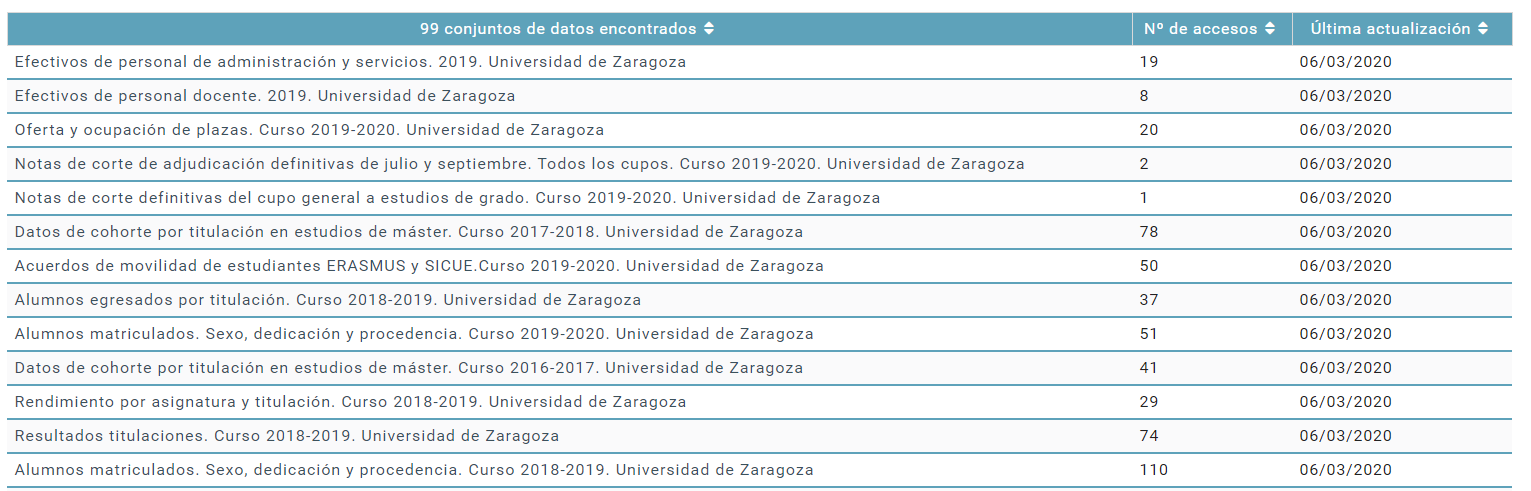
4. Desde el frontend, Angular se conecta con la API de NodeJS, y muestra los datos accesibles a todos los usuarios a través del portal de Aragón Open Data (https://opendata.aragon.es/). Desde el menú del portal, en el apartado de publicadores, se puede acceder a los conjuntos de datos de Universidad de Zaragoza de una manera visual.

Al hacer click sobre el publicador de Universidad de Zaragoza, el usuario que navegue por el portal, tendrá acceso a todos los conjuntos de datos en formato tabla. Tendrá la opción de acceder a cualquier dataset, descargar sus recursos, informarse sobre los metadatos o, por ejemplo, ver la última vez que los datos fueron actualizados, entre otras cosas.
En resumen, mediante el uso de extensiones de la comunidad oficial de CKAN, se propuso una solución a uno de los retos más comunes dentro del mundo de los datos abiertos. Gracias al plugin ckanext-harvest se planteó una arquitectura de federación sencilla, mantenible y que no requiere de un esfuerzo importante como desarrollar un proceso ETL de cero, con lo que ello conlleva.
Si el proyecto es de datos abiertos, y como plataforma base se está utilizando CKAN es una buena decisión trabajar con las extensiones que ofrece la comunidad, en vez de modificar el core del producto o desarrollar nuevos servicios independientes. Los resultados obtenidos al implementar esta arquitectura fueron exitosos, ya que ofrece la posibilidad de escalar y añadir nuevas federaciones a futuro y también garantiza la capacidad de modificación de la estructura demandada.

Gabriel Alcober Fuertes
Jefe de Equipo en DXD
Gabriel inició su carrera profesional en 2011, y durante este tiempo ha participado en proyectos con gran diversidad de tecnologías. Ha trabajado en proyectos Salesforce y Java, y en los últimos tres años ha trabajado en desarrollos enfocados a datos abiertos y web semántica.

