Service Mesh en arquitecturas de microservicios Ha sido salvado

Artículo
Service Mesh en arquitecturas de microservicios
Desde que comenzó la explosión del uso de los microservicios, allá por el año 2015, la arquitectura ha ido evolucionando y madurando en función de las necesidades que se han ido descubriendo con su uso.
La mayoría de estas necesidades se han ido convirtiendo en componentes que han pasado a formar parte de la arquitectura como tal. Un claro ejemplo podrían ser los componentes del primer stack de microservicios que se conoce, Spring Cloud Netflix. Todos los componentes de este stack responden a una necesidad concreta, Eureka es el servicio de registro de metadatos y microservicios, Ribbon sirve de balanceador de peticiones en cliente, Hystrix se utiliza para la gestión de errores, etc. Más allá incluso de los propios componentes básicos de la arquitectura, se comenzaron a definir nuevos stacks, o utilizar stacks ya existentes, para conseguir otro tipo de funcionalidades complementarias, como por ejemplo el stack EL(F)K (ElasticSearch – Logstash o FluentD – Kibana) para el logging.
Posteriormente al establecimiento de la arquitectura, para solventar las dificultades de orquestación y despliegues, surgieron soluciones basadas en contenedores que facilitaron el uso de este tipo de tecnologías. Algunos ejemplos de estas soluciones son Kubernetes, Openshift, Docker Swarm o Mesos. Actualmente, ya se cuenta incluso con multitud de soluciones gestionadas en los diferentes clouds a modo de PaaS, como puede ser la solución de Google basada en Kubernetes, el EKS de Amazon o el AKS de Azure.
Como se puede observar, el concepto de microservicios ha ido evolucionando en función de las necesidades y los problemas que han ido surgiendo con el uso de la arquitectura. Esto, nos lleva a uno de los mayores problemas a los que se enfrenta actualmente este tipo de arquitecturas, que es la gestión de la interacción entre los microservicios y de las funciones de red asociadas a estas interacciones.
Inicialmente estas interacciones se realizaban directamente entre los microservicios y era responsabilidad del desarrollador dotar al microservicio de un plus de inteligencia para gestionar elementos de la comunicación tales como la tolerancia a fallos, el descubrimiento de servicios, la seguridad, etc…
Tener que desarrollar de manera explícita estas funcionalidades comunes no sólo supone un esfuerzo mayor por parte de los equipos de desarrollo, sino que además resulta complejo mantener cierta uniformidad en todos los microservicios, sobre todo si no se implementan todos con las mismas tecnologías y arquitecturas. Gran parte del esfuerzo de trabajo se dedica a crear estas funciones que permiten la comunicación entre los microservicios.
Más allá incluso del desarrollo de estas capacidades, con el aumento del tamaño y la complejidad de las arquitecturas de microservicios, se hace imprescindible controlar de manera más detallada lo que sucede dentro del ecosistema y cómo sucede. Esto incluye métricas de monitorización, trazabilidad, seguridad, etc. Este tipo de control añade un grado mayor de complejidad a la arquitectura.
Como hemos comentado antes, esta funcionalidad es genérica y común a todos los microservicios. Esto, directamente nos lleva a pensar que tiene sentido moverla a una capa donde poder gestionarla de una manera independiente, eliminándola de la implementación de cada microservicio individual. Es justo aquí donde encaja la idea de Service Mesh, gracias a la cual, se transfieren a la infraestructura las necesidades de los microservicios.
El Service Mesh es la infraestructura software a través de la cual se gestionará la comunicación entre los microservicios. Esto incluye, disponibilidad de la comunicación entre los servicios (patrones de reintentos, circuit breaking, balanceo de carga, gestión de errores, etc.), descubrimiento de servicios, enrutamiento, trazabilidad, monitorización y seguridad (autenticación y autorización). Este tipo de funcionalidades resulta crítico si se tiene en cuenta que, típicamente, en este tipo de entornos de despliegue (openshift, kubernetes, etc.), las instancias de los microservicios se levantan y eliminan en función de las necesidades de cómputo a lo largo del tiempo.
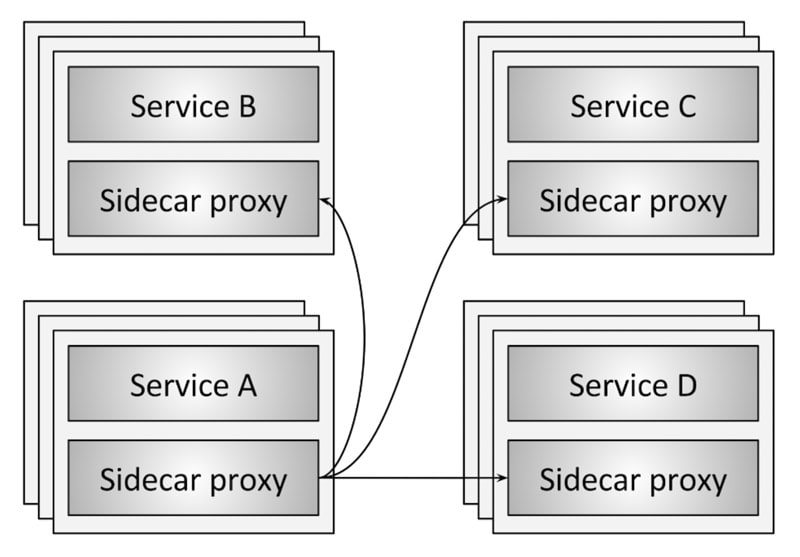
La implementación de un Service Mesh se basa en la aplicación de algunos de los patrones de diseño de aplicaciones distribuidas más conocidos, pero con una diferencia. En este caso, en lugar de aplicarse sobre el código, se aplican sobre la propia infraestructura. El más relevante de los patrones implementados es el patrón sidecar. Este patrón se basa en que un servicio considerado como principal es extendido por otro servicio paralelo, pero de una manera prácticamente transparente para el servicio principal, es decir, con un nivel de acoplamiento muy bajo. En el caso de un Service Mesh, el servicio sidecar funciona a modo de proxy dando soporte al servicio principal y proporcionándole servicios de la infraestructura.

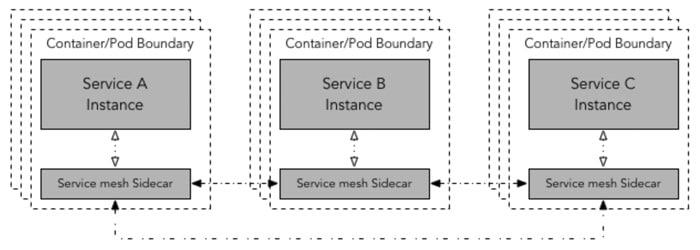
Además, este patrón es especialmente útil en plataformas de orquestación en las que se utilizan elementos que están compuestos por uno o más contenedores de aplicaciones. Un claro ejemplo de esto son los pods de kubernetes.
Los Service Mesh se dividen habitualmente en dos planos, el plano de datos y el plano de control. El plano de datos está representado por los proxy sidecar y se ocupa de las siguientes tareas: descubrimiento de servicios, health checks, enrutamiento, balanceo de carga, captura de trazas y monitorización y la seguridad. Básicamente se ocupa de traducir, redirigir y comprobar cada paquete de red que entra o sale de la instancia del servicio principal. Las instancias de los servicios principales sólo se comunican con los proxy sidecar y son estos mismos los que se comunican entre sí.
Por otro lado, el plano de control es el responsable de gestionar y controlar todas las instancias de proxy sidecar del sistema. Es la pieza en la que se implementan las políticas de seguridad, se recogen las métricas y se establece la configuración del plano de datos. En resumen, las tareas que corresponden al plano de datos son las siguientes: enrutamiento, balanceo de carga, políticas de gestión de errores (reintentos, timeouts, etc.), descubrimiento de servicios y despliegues.
Existen dos patrones de despliegue para los Service Mesh, el despliegue de un proxy sidecar por host o el despliegue directo de los proxy sidecar. En el despliegue por host, se despliega una instancia de proxy sidecar por host. Este host podría ser una máquina virtual, un servidor físico o un nodo worker de kubernetes. Todos los servicios alojados en el host envían el tráfico a través del proxy sidecar.

En el otro tipo de patrón de despliegue, se despliega un proxy sidecar por cada instancia de servicio. Este tipo de despliegue es especialmente útil en entornos de contenedores o kubernetes. En el caso de kubernetes, se desplegaría un contenedor con la instancia del proxy sidecar junto con el contenedor del servicio, en el mismo pod. Obviamente el número de proxy sidecar desplegados con este patrón es mucho mayor.
Dos de los ejemplos más populares de Service Mesh son Istio y Linkerd. Ambas son opensource y tiene una arquitectura similar, de hecho, los servicios que ofrecen son muy similares (enrutamiento dinámico, descubrimiento de servicios, balanceo de carga, gestión de políticas, etc.). En cambio, tienen diferentes mecanismos de implementación. Istio se sirve del proxy Envoy de Lyft como proxy sidecar y Linkerd se basa en Netty y Finagle.
En resumen, los Service Mesh son la respuesta a uno de los mayores problemas de los que adolecen hoy en día las arquitecturas de microservicios, que es la gestión de la comunicación entre los servicios. Obviamente no todo son ventajas con los Service Mesh, se debe estudiar en cada caso concreto si merece la pena o no dedicar tiempo a la aplicación de la solución. La tecnología en sí aún tiene mucho recorrido por delante, pero ya es una realidad (Envoy o Linkerd ya forman parte de la Cloud Native Computing Foundation).
Álvaro Rodríguez
Álvaro es Specialist Lead en el área de Systems Engineering de Consultoría Tecnológica de Deloitte. Con más de 14 años de experiencia en Ingeniería Software, ha ido evolucionando desde el desarrollo de aplicaciones hasta el diseño de infraestructuras software. Su práctica actual combina la gestión de equipos y la colaboración en distintos proyectos como asesor técnico y para la definición de infraestructuras cloud, principalmente AWS.
