
Data tokenization for government Enabling data-sharing without compromising privacy
11 minute read
21 November 2019



Data tokenization can allow government agencies to share data without compromising privacy, enabling them to pool data to gain deeper analytical insights.
We’ve all heard the stories: If only information housed in one part of government had been available to another, tragedy might have been averted. From the 9/11 terrorist attacks to fatal failures of child protective services, we are often left to wonder: What if government’s left hand knew everything it had in its right hand?
Learn more
Read the full CDO Playbook
Create a custom PDF
Learn more about the Beeck Center
Subscribe to receive related content
Download the Deloitte Insights and Dow Jones app
That’s a tough ideal to attain for many government agencies, both in the United States and around the world. Today, much of the information held in government programs is isolated in siloed databases, limiting the ability to mine the data for insights. Attempts to share this data through interagency agreements tend to be clunky at best and nightmarish at worst, with lawyers from multiple agencies often disagreeing over the meaning of obscure privacy provisions written by disparate legislative bodies. No fun at all.
This isn’t because agencies are being obstructionist. Rather, they’re acting with the best of intentions: to protect privacy. Most government programs—such as Supplemental Nutrition Assistance Program (SNAP), Medicare, Unemployment Insurance, and others—have privacy protections baked into their enabling legislation. Limiting data-sharing among agencies is one way to safeguard citizens’ sensitive data against exposure or misuse. The fewer people have access to the data, after all, the less likely it is to be abused.
The flip side, though, is that keeping the data separate can compromise agencies’ ability to extract insights from that data. Whether one is applying modern data analytics techniques or just eyeballing the numbers, it’s usually best to work with a complete view of the data, or at least the most complete view available. That can be hard when rules governing data-sharing prevent agencies from combining their individual data points into a complete picture.
What if data could be shared across agencies, without compromising privacy, in a way that could enable the sorts of insights now possible through data analytics?
That’s the promise—or the potential—of data tokenization.
How data tokenization works
Data tokenization replaces sensitive data with substitute characters in a manner similar to data masking or redaction. Unlike with the latter two approaches, however, the sender of tokenized data retains a file that matches the real and tokenized data. This “token,” or key file, does two things. First, it makes data tokenization reversible, so that any analysis conducted on the tokenized data can be reconstituted by the original agencies—with additional insights gleaned from other data sources. Second, it makes the tokenized data that leaves the agency virtually worthless to hackers, since it is devoid of identifiable information.
A simplified example can help illustrate how tokenized data can allow for personalized insights without compromising privacy. Imagine that you are a child support agency with the following information about an individual:
Name: Marvin Beals
Date of birth: September 20, 1965
Street address: 23 Airway Drive
City, state, zip: Lewiston, Idaho, 83501
Gender: Male
Highest education level: Four-year college
You might tokenize this data in a way that keeps certain elements “real” (gender and education level, for example), broadens others (such as by tokenizing the day and month of birth but keeping the real year, or tokenizing the street address but keeping the actual city and state), and fully tokenizes still other elements (such as the individual’s name). The result might look something like this:
Name: Joe Proust
Date of birth: May 1, 1965
Street address: 4 Linden Street
City, state, zip: Lewiston, Idaho, 83501
Gender: Male
Highest education level: Four-year college
You could readily share this tokenized data with a third party, as it isn’t personally identifiable. But you could also combine this tokenized data with, for example, bank data that can predict what a 54-year-old male living in that zip code is likely to earn, how likely he is to repay loans, and so forth. Or you could combine it with similarly tokenized data from a public assistance agency to learn how likely a male of that age in that geographical area is to be on public assistance. After analysis, you (and you alone!) could reverse the tokenization process to estimate—with much greater accuracy—how likely Marvin is to be able to pay his child support. Going deeper, you could work with other government agencies to tokenize some of the other personally identifiable information such as yearly income, social security number etc. in the same way, allowing you to connect the data more precisely with additional data.
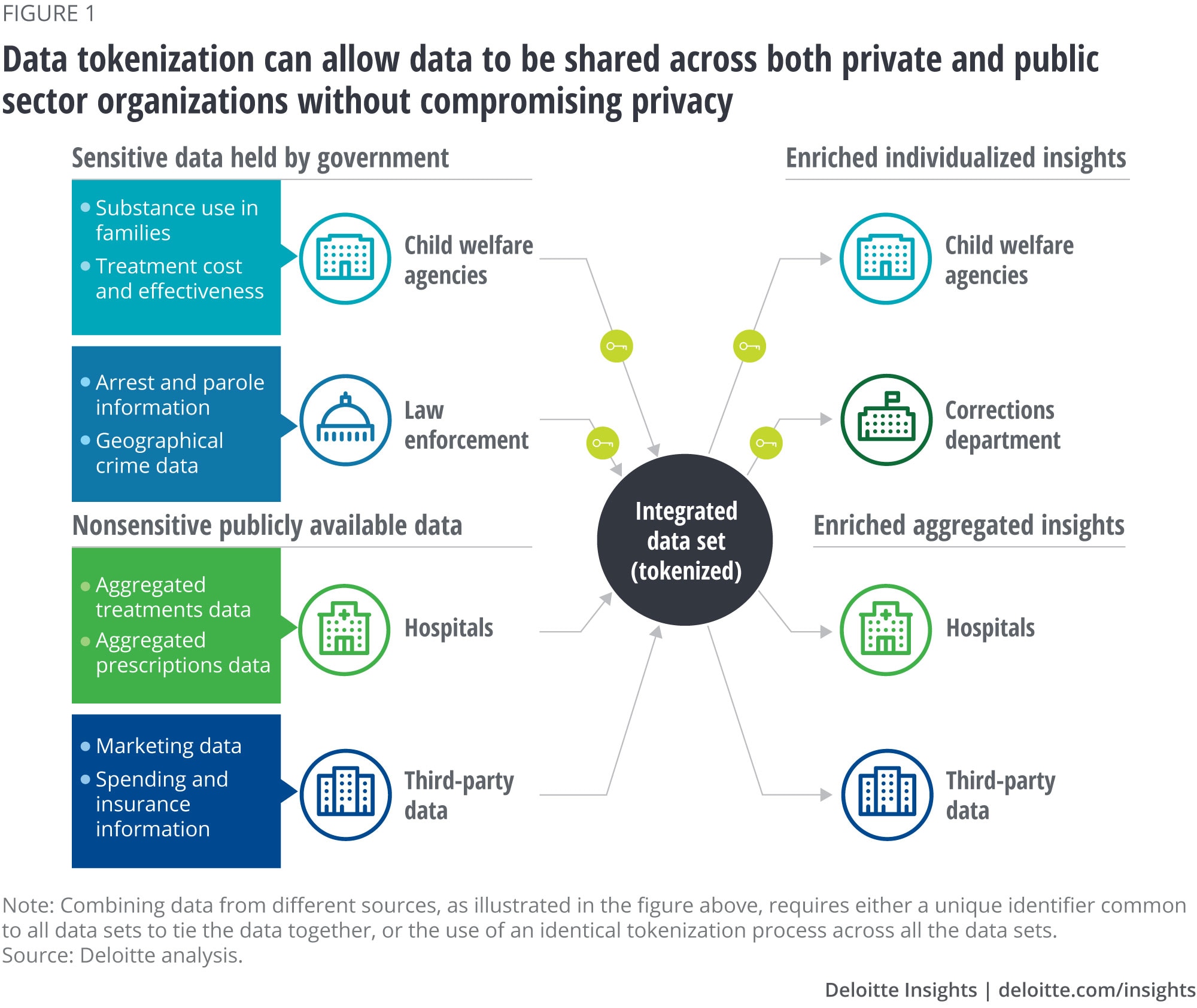
Data tokenization’s most powerful application is likely this mingling of tokenized government data with other data sources to generate powerful insights—securely and with little risk to privacy (figure 1). Apart from the ability to deidentify structured data, tokenization can even be used to deidentify and share unstructured data. As governments increasingly use such data, tokenization offers many new use cases for sharing data that resides in emails, images, text files, and other such files.
Data tokenization already helps some companies keep financial data safe
Data tokenization is already considered a proven tool by many. It is widely used in the financial services industry, particularly for credit card processing. One research firm estimates that the data tokenization market will grow from US$983 million in 2018 to US$2.6 billion by 2023, representing a compound annual growth rate of 22 percent.1
It’s not hard to understand why data tokenization appeals to those who deal with financial information. Online businesses, for instance, want to store payment card information to analyze customer purchasing patterns, develop marketing strategies, and for other purposes. To meet the Payment Card Industry Data Security Standard (PCI DSS) for storing this information securely, a company needs to put it on a system with strong data protection. This, however, can be expensive—especially if the company must maintain multiple systems to hold all the information it collects.
Storing the data in tokenized form can allow companies to meet the PCI DSS requirements at a lower cost compared to data encryption.2 (See the sidebar “The difference between encryption and tokenization” for a comparison of the two methods.)
Instead of saving the real card data, businesses send it to a tokenization server that replaces the actual card data with a tokenized version, saving the key file to a secure data vault. A company can then use the tokenized card information for a variety of purposes without needing to protect it to PCI DSS standards. All that needs this level of protection is the data vault containing the key file, which would be less expensive than working to secure multiple systems housing copies of real credit card numbers.3
The difference between encryption and tokenization4
Encryption is the process of transforming sensitive data into an unreadable form using an algorithm. A password, also known as a “key,” is generally needed to decrypt the data. Encryption is useful when sensitive information needs to be exchanged securely—although both parties will need to hold an encryption key (either a symmetric or asymmetric key). However, encrypted data can be reversed into its original form if the key is compromised. Many attackers resort to what is known as a dictionary attack—trying millions of likely passwords—in attempts to hack encrypted data.
Tokenization, on the other hand, does not use a traditional algorithm to drive the masking process. Rather, it replaces sensitive data with random data, maintaining a one-to-one mapping between each sensitive data point and its corresponding random data point. This mapping is stored securely in a “token store,” and only individuals with access to the token store can reverse the tokenization process.
Even after encryption, the sensitive data is, in its essence, still there, vulnerable to sophisticated cybercriminals who can crack the encryption algorithm. But even if bad actors were to steal tokenized data, it would be worthless to them without the corresponding token information. This is because tokenized data does not, in itself, contain any useful information, since the random replacement data points have no inherent value. And because tokenized data cannot be understood without the key, the tokenization process allows the original data to be analyzed while completely preserving the anonymity of the sensitive aspects of that information.
Another feature of tokenization not available with encryption is the ability to “forget.” It is possible to delete the token so the true values can never be reidentified, which may be useful when individuals ask for their info to be erased and “forgotten” as under the European Union privacy regulations.
Other approaches to merging data without compromising security are under development. For example, it may be possible for a number of government agencies to use the same “public” key to tokenize data while making detokenization possible only with a “private” key held by a single high-level privacy office. This would do away with the need to use a common identifier across data sets.
How data tokenization could help government address the opioid crisis
Policymakers often describe the US opioid crisis as an “ecosystem” challenge because it involves so many disparate players: doctors, hospitals, insurers, law enforcement, treatment centers, and more. As a result of this proliferation of players, information that could help tackle the problem—much of it of a sensitive nature—is held in many different places.
Government health data is difficult to share—as it should be. Various agencies house large amounts of sensitive data, including both personally identifiable information (PII) and personal health information (PHI). Given government’s significant role in public health through programs such as Medicare, Medicaid, and the Affordable Care Act, US government agencies must expend considerable resources in adhering to Health Insurance Portability and Accountability Act (HIPAA) regulations. HIPAA alone specifies 18 different types of PHI, including social security numbers, names, addresses, mental and physical health treatment history, and more.5
However, the US Department of Health and Human Services (HHS) guidelines for HIPAA note that these restrictions do not apply to de-identified health information: “There are no restrictions on the use or disclosure of de-identified health information. De-identified health information neither identifies nor provides a reasonable basis to identify an individual.”6 By tokenizing data, states may be able to share opioid-related data outside the agency or organization that collected it and combine it with other external data—either from other public agencies or third-party data sets—to gain mission-critical insights.
Data tokenization might enable states to bring together opioid-related data from various government sources—including health care, child welfare, and law enforcement agencies—and combine this data with publicly available data related to the social determinants of health and health behaviors. The goal would be to gain insights into the causes and remedies of opioid abuse disorder. By tokenizing the data’s personal information, including PII and PHI, government agencies can share sensitive but critical data on opioid use and abuse without compromising privacy. Moreover, only the government agency that owns the sensitive data in the first place would be able to reidentify (detokenize) that data, assuming that the matching key file never leaves that agency’s secure control. At no point in the entire cycle should any other agency or third party be able to see real data.
Why not simply use completely anonymized data to investigate sensitive topics like opioid use? One reason is that tokenized data, but not anonymized data, can provide insights at the individual level as well as at the aggregate level—but only to those who have access to the key file. For example, tokenization can turn the real Jane Jones into “Sally Smith,” allowing an agency to collect additional data about “Sally.” If we know that “Sally Smith” is a 45-year-old female with diabetes from a certain zip code, the agency can merge that with information from hospital records about the likelihood of middle-aged females requiring readmission, or about the likelihood of a person failing to follow his or her medication regimen. An analysis of this combined information can allow the agency to come up with a predictive score—and the agency can then detokenize “Sally Smith” to deliver customized insights for the very real Jane Jones. This ability to gain individual-level insights could be helpful both in delivering targeted services and in reducing improperly awarded benefits through fraud and abuse.
The mechanics of securely combining different data sets after tokenization can be complicated, but the potential benefits are immense.
Partial tokenization can enable complete insights
Tokenizing data can make more data available for analysis—but what if the data points that are swapped out for random information are precisely what you’re interested in analyzing? Some attributes, such as age or address, that may be valuable to the analysis could be lost if the tokenization process doesn’t take this into account. You certainly wouldn’t want to analyze data for insights on the opioid epidemic with anything other than real health information.
“Partial tokenization” offers a way around this problem. With partial tokenization, government agencies can obscure the personally identifiable attributes of the data without losing the ability to detect critical insights. This is done by tokenizing only those parts of the data that can pinpoint an individual. For example, a tokenized date of birth might tokenize the day and month but leave the year intact—which provides sufficient information to analyze patterns of behavior that may vary with age.
Tokenization can be combined with redaction or truncation. For example, fields that can identify individuals (such as name or social security number) can be completely tokenized, fields like address and date of birth partially tokenized, and other fields such as health information untokenized. Such techniques can help government detect fraud, identify patterns of use, and provide predictive insights to better serve constituents.
The opioid crisis is not government’s only ecosystem challenge. As we’ve seen in the private sector, in industries from retail to auto insurance, more information generally means better predictions. (That’s why your auto insurer wants to know about your driving patterns, and why they might offer a discount if you ride around with an app that captures telemetrics.) Many companies’ websites require an opt-in agreement to allow them to use an individual’s data. This approach is more challenging in government, however, due to the sensitive nature of data that is collected and the fact that citizens must be served whether they opt in or not. Where circumstances make it impractical to obtain consent, data tokenization can make it possible for governments to use data in ways other than the originally intended use without violating individuals’ privacy.
Taking data tokenization beyond data-sharing
Beyond allowing agencies to share data without compromising privacy, data tokenization can help governments in other ways as well. Three potential uses include developing and testing new software, supporting user training and demos, and securing archived data.
Developing and testing new software. Developers need data to build and rigorously test new applications. Government frequently relies on third-party vendors to build such systems, because it can be prohibitively expensive to require all development and testing be done in-house on government premises. But what about systems such as those relating to Unemployment Insurance or Medicaid, which contain a great deal of PII and PHI? By using format-preserving tokens to tokenize actual data while maintaining the original format—where a tokenized birth date, for example, looks like 03/11/1960 and not XY987ABC—third-party developers can work with data that “feels” real to the system, reliably mimicking the actual data without requiring all the security that would be needed if actual data was being shared. Some US states, including Colorado, have used data tokenization in this manner. Data tokenization apps are often a cost-effective way to give developers tokenized data.
User training and demos. When new employees join government agencies, they often undergo a probationary period during which they need to be trained on various applications and evaluated on their performance.7 During this time, government agencies can create training environments using tokenized data, enabling new hires to work and interact with data that looks real but does not compromise security.
Securing archived data. Data tokenization can also allow governments to archive sensitive data offsite. For US government agencies, securing sensitive data not in active use in a production environment has been a challenge due to costs and competing priorities.8 A 2018 report by the US Office of Management and Budget found that, while 73 percent of US agencies have prioritized and secured their data in transit, less than 16 percent of them were able to secure their data at rest9—an alarming statistic, considering that governments are often a prime target for cyberattacks and have been experiencing increasingly complex and sophisticated data breaches in the last few years.10
How can governments get started?
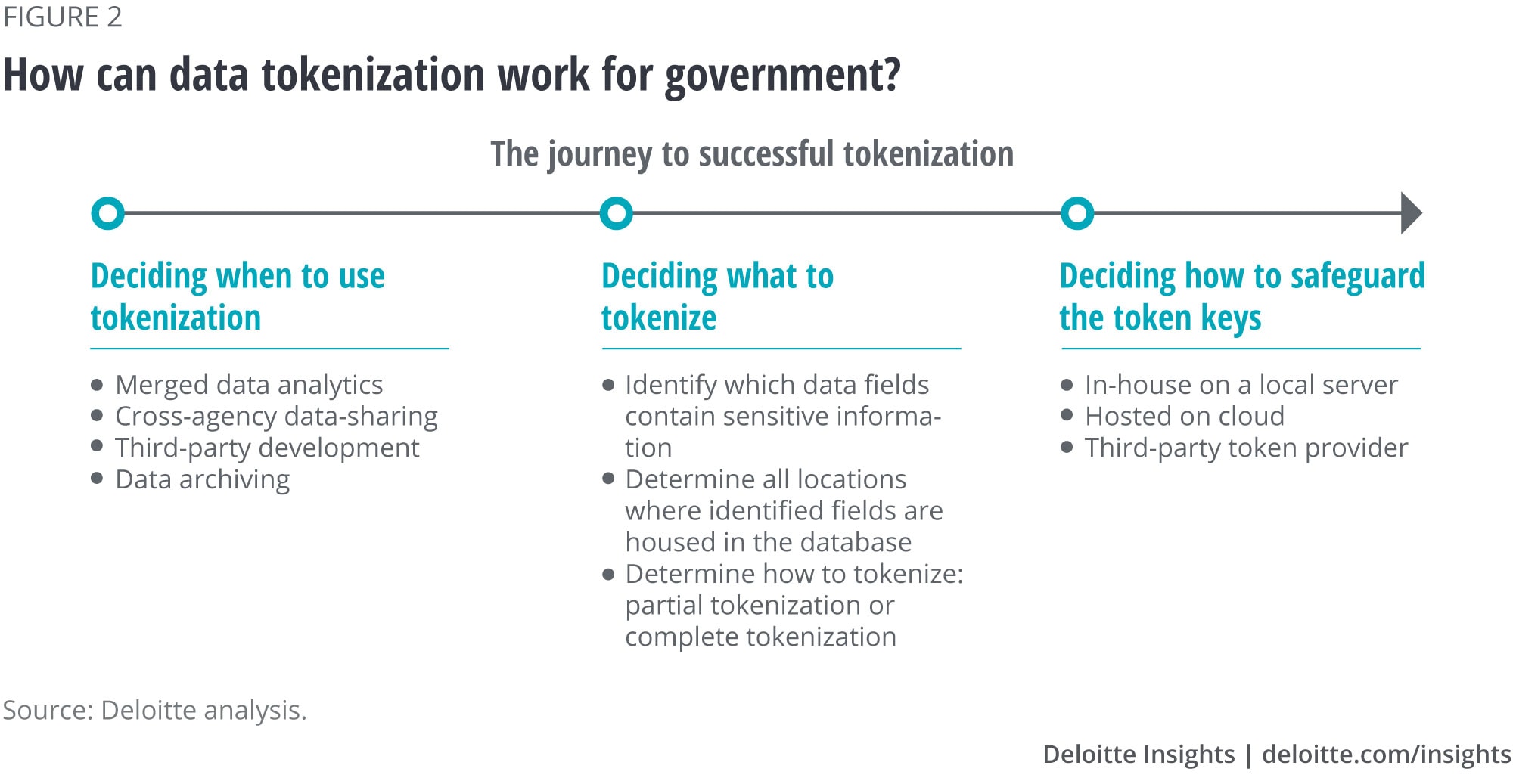
Figure 2 depicts three important decisions government departments should carefully consider to successfully implement data tokenization. First, when should they use tokenization? Second, what data should they tokenize? And third, how will they safeguard the token keys? Once the decision to use tokenization has been made, there is still much important work to be done. The team tokenizing the data must work closely with data experts to ensure that tokenization is done in a way that allows the end users to meet their intended objectives yet ensures privacy.
Public officials are often frustrated by their lack of ability to share data across organizational boundaries, even in situations where sharing the data would have a clear benefit. This lack of cross-agency sharing can mean that agencies don’t make the most of data analytics that could improve public health, limit fraud, and make better decisions. Data tokenization can be one way for government agencies to share information without compromising privacy. Though it is no magic bullet, the better insights that can come from sharing tokenized data can, in many circumstances, help governments achieve better outcomes.
Technology Consulting
Deloitte Consulting LLP’s Technology Consulting practice is dedicated to helping our clients build tomorrow by solving today’s complex business problems involving strategy, procurement, design, delivery, and assurance of technology solutions. Our service areas include analytics and information management, delivery, cyber risk services, and technical strategy and architecture, as well as the spectrum of digital strategy, design, and development services offered by Deloitte Digital.
Learn more
Get in touch

- William D. Eggers
- Executive director, Deloitte Center for Government Insights
- Deloitte Services LP
- +1 571 882 6585
- weggers@deloitte.com


