
Looping in your new sidekick The role of machine learning in qualitative data analysis
14 minute read
06 February 2020
 Monika Mahto United States
Monika Mahto United States Susan K. Hogan United States
Susan K. Hogan United States Dr. Michela Coppola Germany
Dr. Michela Coppola Germany Abha Kulkarni India
Abha Kulkarni India
Given the increasing sophistication of artificial intelligence and machine algorithms, using machines to analyze data could yield time and cost efficiencies and enhance the value of insights derived from the data.
Qualitative research analysis: Is there a better way?
Most organizations use a variety of data collection and analysis methods to understand their stakeholders, whether through customer satisfaction surveys, product reviews, or employee pulse surveys. These ways of gaining insights fall into two broad categories: quantitative and qualitative data collection and analysis. Quantitative responses can be tallied and analyzed quickly, efficiently, and accurately with the help of mathematical logic formulas, algorithms, and, now, machines. Analyzing qualitative data is typically trickier, and it largely remains the province of human analysts, given that it requires a high degree of contextual understanding and social intelligence.
Learn more
Explore the AI & cognitive technologies collection
Explore the future of work collection
Learn about Deloitte’s services
Go straight to smart. Get the Deloitte Insights app
For qualitative analysis insights to be considered valid—and taken seriously—the old-school method generally involves two or more people separately analyzing (for example, coding or categorizing) the data collected. Their results are then compared and synthesized. While this process helps validate the findings by limiting individual bias and subjectivity, it also makes these types of studies much more resource-intensive.
Can machines be the answer?
Given the increasing sophistication of artificial intelligence and machine algorithms available to possibly assist with both quantitative and qualitative analysis, it seems only logical—and prudent—for enterprise leaders to explore how they might capitalize on and incorporate technology to either replace or augment the current process. Using machines to analyze qualitative data could yield time and cost efficiencies as well as enhance the value of the insights derived from the data.
To understand the extent to which technology can be used to perform qualitative data analysis, we compared a team of three analysts with a machine (or, rather, a machine algorithm designed specifically for data analysis) in the analysis of the qualitative data we gathered from a recent Deloitte survey.1 This article uses the findings from this “bake-off,” as well as existing human-machine and collective intelligence research and literature, to understand what value humans and machines can provide at each step of the qualitative analysis. Building on existing research on human capabilities, we recommend ways to potentially integrate machines into the qualitative research analysis process and identify how human contributions can guide business leaders to gain actionable insights from qualitative research.2
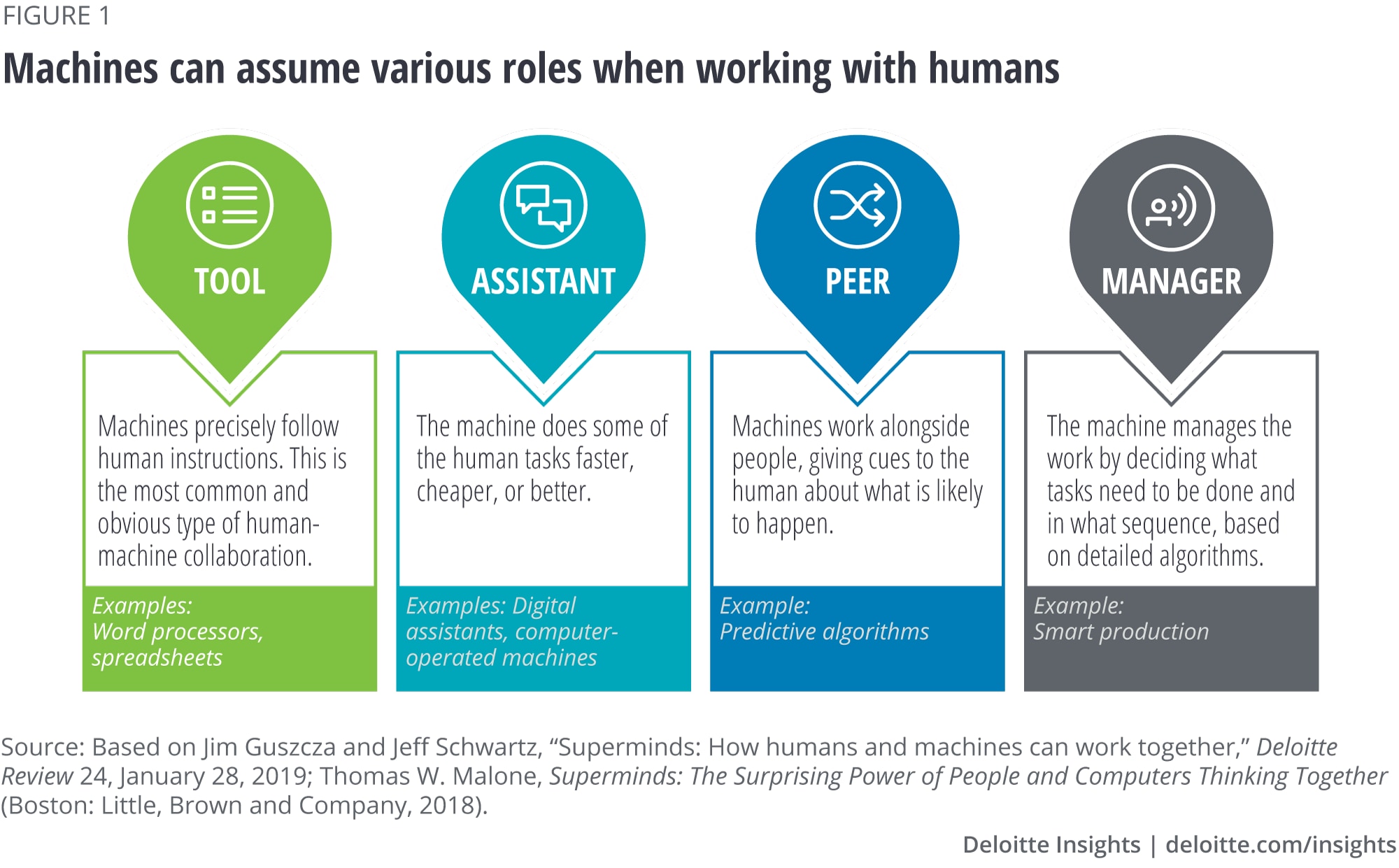
Study methodology
Deloitte’s European Workforce survey, polled more than 15,000 people in 10 European countries to understand the expectations of the labor force (read a detailed analysis of the results in Voice of the workforce in Europe).3 For the current report, we focused on analyzing the qualitative question: “Please provide any additional comments you feel are relevantly linked to what keeps you motivated in the workplace and/or what you believe needs to change moving forward.” An in-house team of three analysts and an algorithm managed by a data science team analyzed the free-text English responses. After cleaning the data for irrelevant and invalid responses, we considered 372 responses for this analysis. These responses were then categorized into relevant themes for sentiment analysis.
Dissecting the process: Screening, sorting, and sensing
To analyze and gain meaningful insights from qualitative (open-ended) questions, most analysts generally follow three main steps: data screening, sorting (or categorizing), and finally, sensing (describing the respondent’s emotions).
Step one: Screening (cleaning out the slackers and misbehavers)
The first step is pretty much what the name suggests—screening the data for either illegible, nonsensical, or indecipherable responses, as well as legible but irrelevant responses.
While our algorithm was faster at screening, taking only 17 percent of the time the analysts needed to screen out the unusable responses, the algorithm’s output quality was inferior: It failed to fully screen the data to a level fit for the next step. Specifically, while manual screening yielded just 35 percent valid responses, the algorithm considered 73 percent of the responses to be valid. While it was good at identifying indecipherable responses (such as “$%^& ()” or “hoihoihoih”), the machine was not so good at identifying legible responses that added no value, such as “no additional comments,” “not applicable,” “not sure,” “don’t know, can’t think,” and “excellent survey.”
Thus, while machines can do a good first pass, human oversight and review is still often necessary in the screening step. Machines in their present state typically play the role of “tools” in the screening process.
Step two: Sorting and synthesizing (making sense of the madness)
The next step is generally to sort or categorize the data into buckets or recurring themes to identify respondents’ key insights and feedback. This part of the exercise was particularly challenging, as the survey question was not only broad but also “double-barreled,”4 asking respondents two different questions at once. Specifically, respondents were asked for their views on what keeps them motivated in the workplace and/or what needs to change moving forward. Because of this, the human analysts and the algorithm had to not only categorize the responses, but also discern which aspect—or aspects—of the question people were responding to. The analysts and the machine tackled this task using completely different strategies.
Word clouds: Love them or hate them, you shouldn’t ignore them
Since the map of landmarks in Paris, one of the earliest word clouds, was created in 1976, word clouds have become increasingly popular for their ability to provide a quick snapshot of data.5 Simple algorithms can quickly create word clouds based on the relative frequency of words in a data set. However, it’s important to recognize some of their key limitations before using word clouds for insight generation and decision-making.

The machine’s take: A word cloud tells you everything you need to know … or does it?
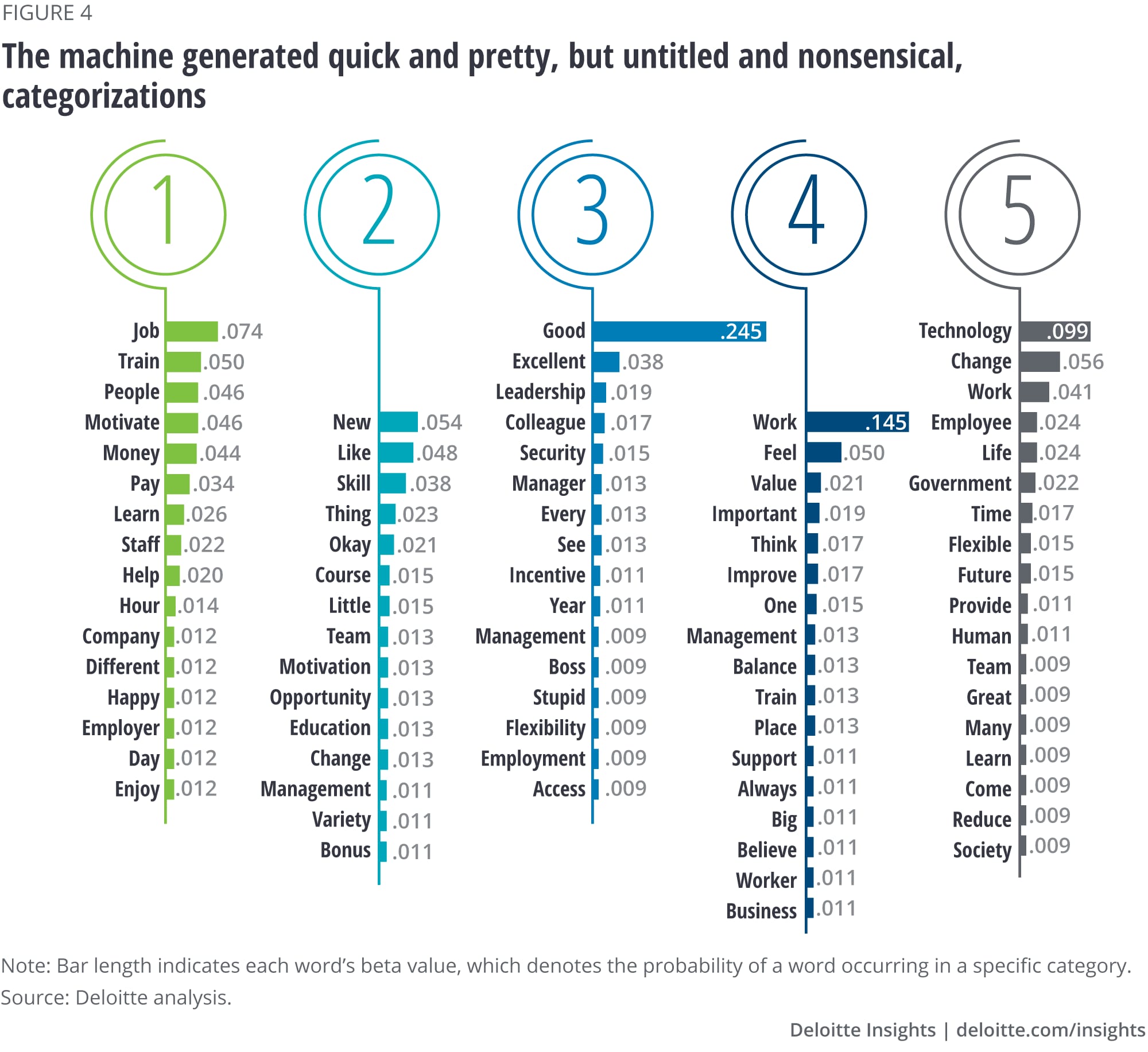
Our algorithm approached the sorting task in a manner similar to the strategy followed by most highly regarded qualitative software products currently on the market. It took all the qualitative phrases, identified the frequency with which various words were mentioned, and used the frequency information to generate a word cloud: A succinct graphical depiction of word frequencies, placing the words most often mentioned in larger and bolder fonts toward the center of the graphic and the words less often mentioned in smaller text toward the edges (figure 3), thus presenting a thumbnail view of the findings. The word cloud highlights key themes relevant to the analysis: technology, work, training, and so on.

To test the algorithm’s ability to identify what concepts fell under each of these themes, we asked it to classify concepts using topic modeling, yielding the categories shown in figure 4. The machine did not label these categories, but simply numbered them arbitrarily. On inspection, the machine-generated categories were difficult to relate to a specific theme. For instance, while category 5 appears to be associated with compensation, it also contains a few unrelated terms (such as “technology” and “change”) that fit in statistically but not contextually. Also, since the machine categorization was driven by words, not phrases, it is impossible to be sure if the algorithm’s categorization took respondents’ comprehensive and accurate meaning into account.
As seen, the machine-generated categorization does not seem to make sense, and hence needs manual intervention to build meaningful insights.
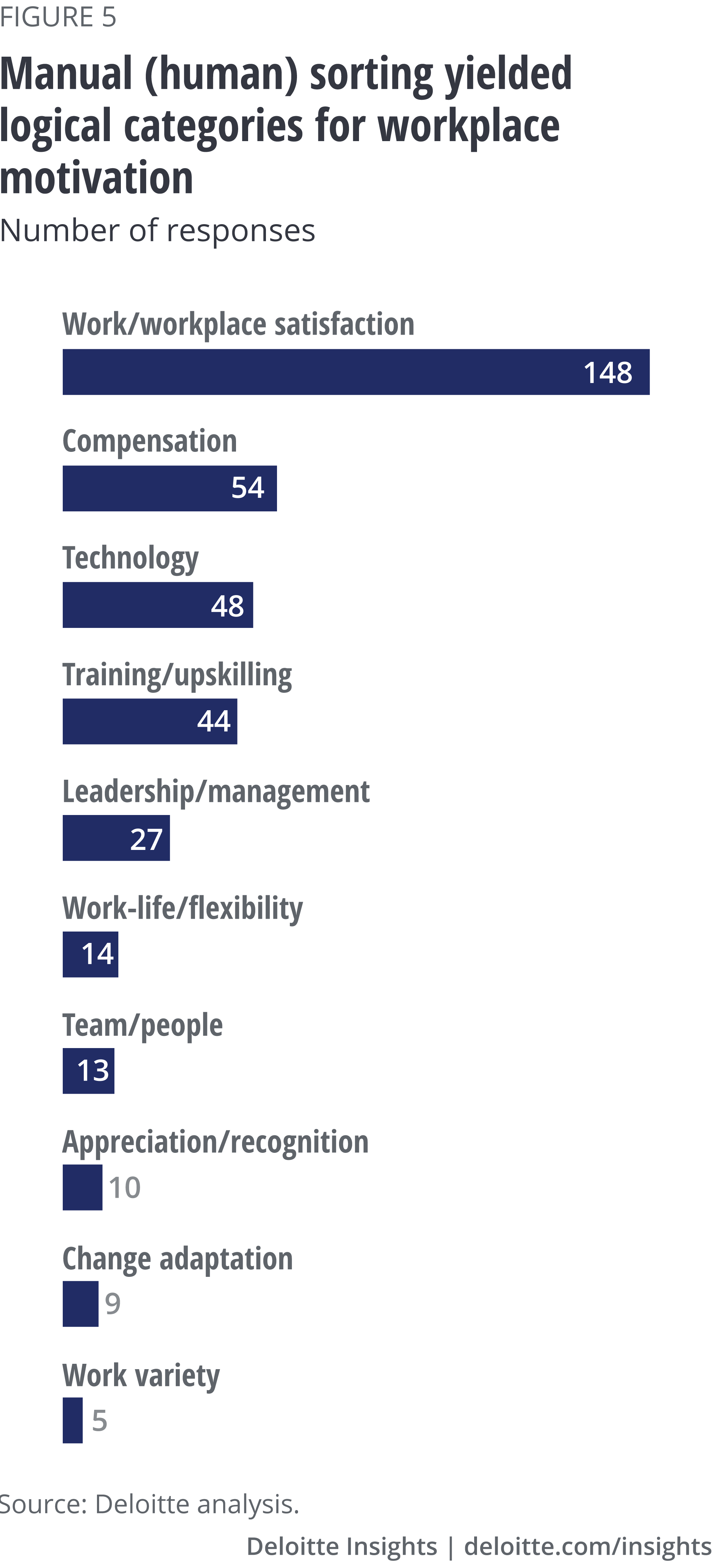
The human take: Synthetic thinking—Divide, categorize (phrases), then compare
The same task of categorization was then performed by our human analysts. The sorting and synthesizing of unstructured data typically requires both time and cognitive effort, involving concentration, focus, intuition, and synthetic and integrative thinking. While the machine merely counted the frequency of words mentioned, the analysts plodded through the responses, sorted them into what they intuitively perceived to be common recurring themes, and created labels for the categories (figure 5).
Based on the human analysis, some 40 percent of the responses had to do with the respondent’s job, work, or work satisfaction. Sample answers in this category included, “I enjoy my job and what I do; that is motivation enough” and “I love the work I am doing.” The next three most popular categories, each representing 10–15 percent of the open-ended responses analyzed, were compensation, technology, and training/upskilling. Next came leadership/management, representing about 7 percent of the responses.
Step three: Sensing (moving from statements to feelings)
While sorting and synthesizing is about understanding what workers are saying, sensing (also known as sentiment analysis) is about understanding what people are feeling. It’s important to know, for instance, whether people feel positively or negatively about the topics they mention. Moreover, in the case of our two-part question, neither the human nor the machine categories indicated which part of the question (“what keeps you motivated” or “what needs to change”) respondents were referring to. The goal of the next step, sensing, was to decipher respondents’ underlying emotions, interests, or concerns, as well as which part(s) of the two-part question the respondents have answered. Armed with this information, analysts could start a conversation with business leaders about what insights the data helped identify.7
“While sorting and synthesizing is about understanding what workers are saying, sensing (also known as sentiment analysis) is about understanding what people are feeling.”
The machine’s take: Look at phrases, but anchor on words
In our study, the human analysts and the algorithm both worked first on sentiment analysis—classifying each response as either primarily positive or primarily negative.8
We instructed the algorithm to consider the phrases associated with the human-created categories and assign them a positive or negative value. While the algorithm was once again quicker, completing the task in one-fifth of the time the humans took, it missed the mark in some cases. For instance, it classified “I feel extremely motivated” as a negative sentiment. Examination of the machine’s software revealed that this was due to its data dictionary package, which had assigned a negative value to the word “extremely.”
Once again, the challenge for the machine was digesting a phrase in its entirety—that is, intuiting the contextual meaning as opposed to the definitions of individual words. Focusing on single words to identify emotions, as we all know, is not always reliable. Imagine, for example, a manager using a machine to interpret a phrase such as, “It would be terrible to lose Mary as a colleague.” Focusing on just the words, the machine would likely classify this feedback as negative, given the use of the word “terrible.”
Not only did our algorithm do a poor job of assigning emotions to phrases, it also provided no value in teasing apart which answers pertained to “what keeps you motivated” and which to “what needs to change.”
The human take: Tease apart the answers and identify emotions based on context
To perform sentiment analysis, our human analysts first assigned a valence—positive or negative—to each phrase (not word) based on the underlying dominant emotion of each of the responses (figure 6).9 Such emotional labels are invaluable to enterprise decision-makers such as marketers and recruiters, particularly when it comes to measuring the attractiveness of a product, service, or job position.
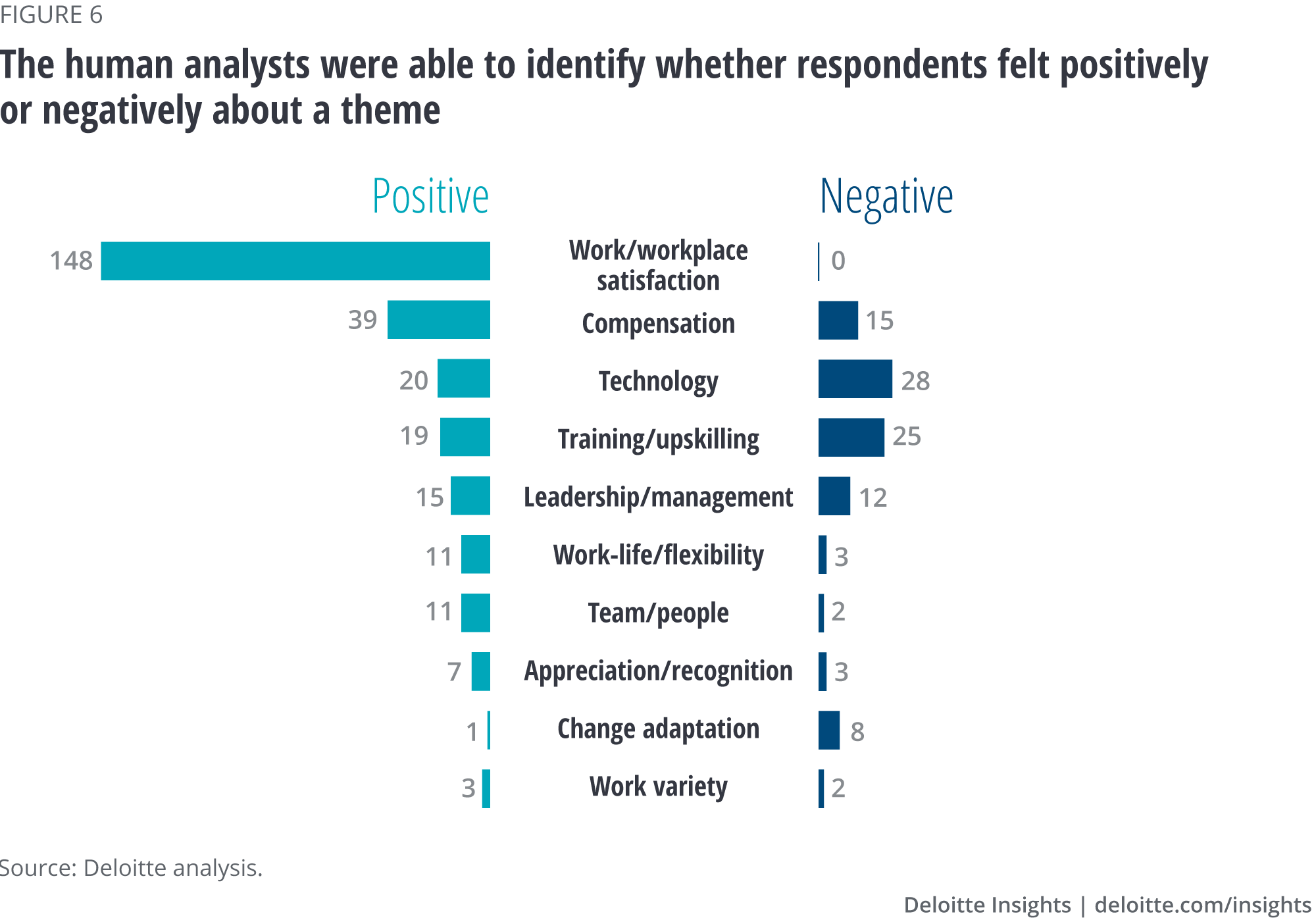
The analysts then tackled separating which phrases were relevant to “what keeps you motivated” and the ones relevant to “what needs to change.” In real life, this would perhaps be the most important information for leaders and managers to act upon.
After overall work satisfaction, compensation was the most important theme to respondents, so the analysts sorted all of the phrases related to compensation into those related to “keeps me motivated” and those related to “needs to change.” This analysis showed that respondents identified money as their main motivator—specifically, monetary and non-monetary incentives and the ability to pay their bills. In terms of what “needs to change,” respondents were most likely to cite an increase in overall pay and monetary incentives. The work environment and the number of working hours in line with the compensation offered were also top factors suggested for change.
As evident from our comparison of humans with the algorithm, machines are limited in their ability to perform a thorough and accurate sentiment analysis. Sentiments are nuanced, and machines find it difficult to read them right for several reasons: the use of a rigid data dictionary, reading words and not phrases, and the need to parse the sentiment into subcategories for double-barreled questions. These are serious limitations that researchers should consider when leaning upon algorithmic analysis. Humans have a key role to play in this final step to ensure that the right insights drive decision-making.
“Sentiments are nuanced, and machines find it difficult to read them right for several reasons: the use of a rigid data dictionary, reading words and not phrases, and the need to parse the sentiment into subcategories for double-barreled questions.”
From insights to action: Suggesting, supposing, and steering
Thus far, our machine-human “bake-off” has demonstrated the important role humans play in data analysis and what value they bring to the activity. Every step of the way—in screening, sorting, and sensing—there is a need for not only human involvement but also human know-how to ensure the analysis’s accuracy and completeness. And the human’s job doesn’t typically end there. The whole point of data analysis is to provide not only insights, but also actionable recommendations—which our algorithm showed only limited capacity to do. In addition, research and insight collection are typically not one-off activities but components of a bigger ongoing research effort or portfolio. Human analysts, with their in-depth knowledge of the data, can help drive the company’s research agenda and sift through and prioritize various implementation plans, communications, and research strategy recommendations. An ideal human-machine research team drives the process by suggesting which data sets are usable and meaningful, moves on to supposing considerations based on contextual understanding to finally steering informed actions to meet key business objectives.
Practical implications
Considering the capabilities of the humans and machines detailed above, below are some thoughts for leaders to consider as they determine how to approach qualitative data analysis:
- Context is king. When it comes to word clouds, the machine knows no equal. But while these are helpful for messaging and gaining a general understanding of what’s on stakeholders’ minds, machines perform poorly in reading between the lines, understanding nuances, and accounting for the conditions surrounding a statement. That said, not all machines are alike—and they are still learning and evolving. We anticipate that with machine learning, dictionaries will change and improve over time, but so could human language. Human capabilities should continue to be necessary to keep things in context.
- The only constant is change—and with change comes unpredictability. It is difficult to envision a research instrument containing no suboptimally worded questions due to human error, the need to include legacy questions, or a stakeholder’s last-minute ask. Thus, researchers—just like a plumber climbing under a sink for a first or hundredth time—never know exactly what they are going to find.10 While computers can eventually be programmed to deal with one-off ambiguities, humans should always be there to deal with and sort out the unpredictable. With their better contextual understanding, humans could often stumble upon serendipitous connections that a machine might miss.
- “Slow” thinking and subjectivity are strengths, not limitations. Human subjectivity and “slow” thinking (that is, deliberate, effortful, analytic cognition), often considered limitations, can actually be strengths that help organizations make the best use of human-machine collaboration.11 As machines become ever faster, humans should slow down to do their best work in two ways: (1) by connecting disconnected elements to draw nuanced inferences, and (2) by separating out the aggregated elements if they are lumped together statistically but not logically. As humans feel rushed to keep up with technology, corporate incentives and culture should evolve to encourage slow thinking.
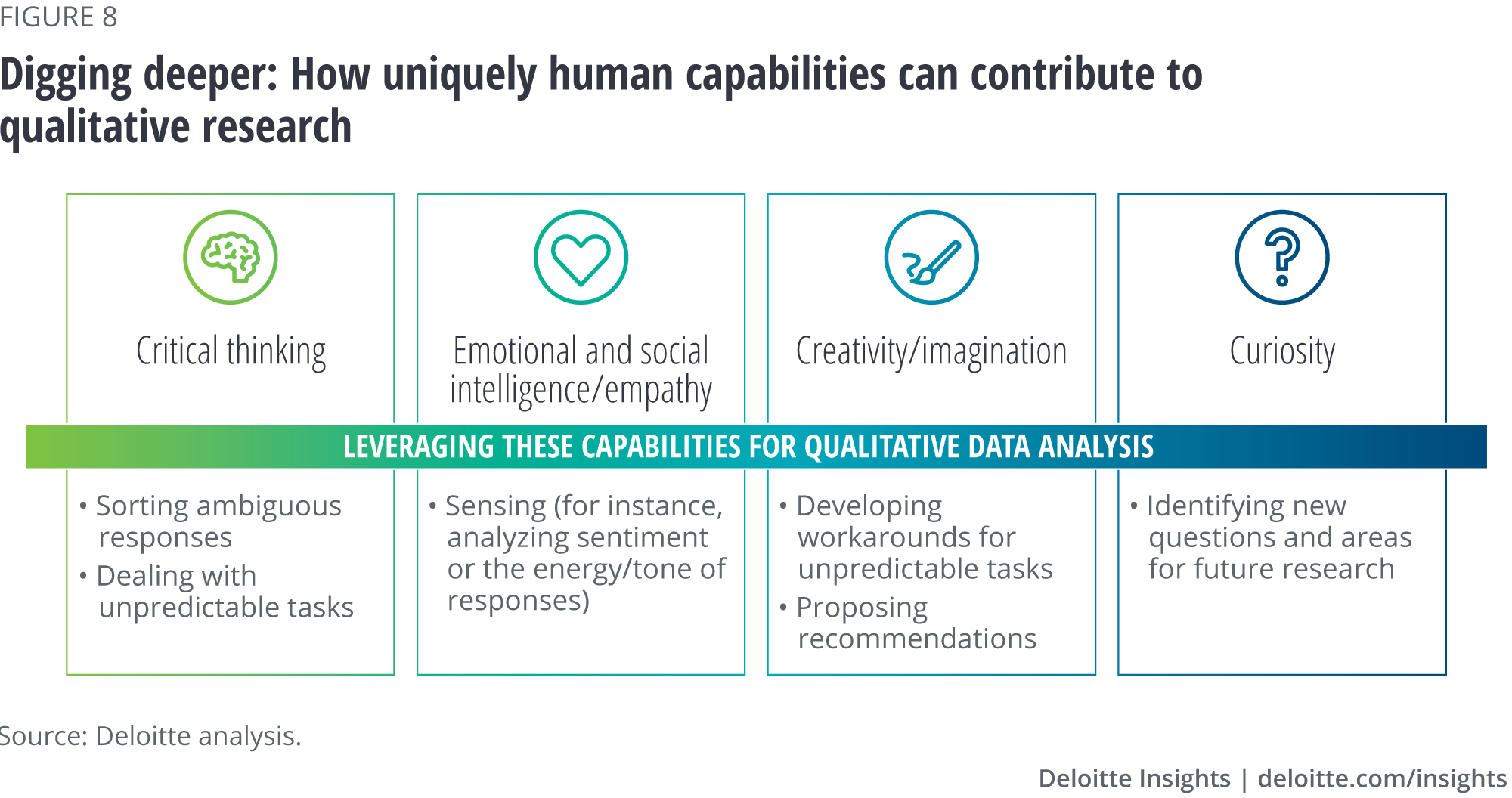
- Savvy firms should not only celebrate but nurture human capabilities. Recent research into skills and capabilities has identified enduring human qualities, such as curiosity, imagination, and empathy, that savvy firms will likely learn to capitalize on (figure 7).12 In figure 8, we identified how these capabilities can and should pay out in qualitative analysis.
“As humans feel rushed to keep up with technology, corporate incentives and culture should evolve to encourage slow thinking.”
With the synergistic power of man and machine, qualitative research can be done more efficiently. By letting our human analysts and researchers slow down and be “more human,” the insights, recommendations, and value derived from qualitative research may exceed what has been achieved so far. We value and encourage firms to embrace their new technological sidekicks, but it is apparent that for data analysis we still need team human for their unique capabilities.
Human Capital
Deloitte’s Human Capital professionals leverage research, analytics, and industry insights to help design and execute the HR, talent, leadership, organization, and change programs that enable business performance through people performance.
Learn more
Get in touch

- Steven W. Hatfield
- Principal
- Deloitte Consulting LLP
- sthatfield@deloitte.com
- +1 212 618 4046




Explore more on future of work
-
 Charting new pathways Article4 years ago
Charting new pathways Article4 years ago -
 The digital-ready worker Article4 years ago
The digital-ready worker Article4 years ago -
 A pragmatic pathway for redefining work Article4 years ago
A pragmatic pathway for redefining work Article4 years ago -
 Laying the foundation for the future of work in India Article4 years ago
Laying the foundation for the future of work in India Article4 years ago -
 Government jobs of the future Collection
Government jobs of the future Collection








