




A conversational journey has been saved

A conversational journey How the three Ts of conversational AI build better voice assistants
8 minute read
22 November 2019
 Vatatmaja United States
Vatatmaja United States Jyotirmay Gadewadikar United States
Jyotirmay Gadewadikar United States Sherry Comes United States
Sherry Comes United States Timothy Murphy United States
Timothy Murphy United States
The popularity of voice assistants is on the rise, but learning to design an intuitive and effective model is still a work in progress. How can organizations use the three Ts—training, testing, and tuning—to create more human-like voice assistants?
In the first article of our conversational AI series, we explored how the proliferation of voice assistants and messaging platforms are giving way to a new era of user interfaces (see the sidebar, “A five-part series on conversational AI”). Whether it’s in the car, a phone, or a smart home device, nearly 112 million US consumers rely on their voice assistants at least once a month—and that number continues to grow.1
Learn more
Explore the AI and cognitive technologies collection
Download the Deloitte Insights and Dow Jones app
Subscribe to receive more related content
Yet the popularity of voice assistants isn’t without its growing pains. These can range from the mundane, such as misinterpreting a request for ordering a roll of paper towel, to the more troubling error of providing a harmful health recommendation (or conversely, providing an accurate, but difficult to interpret recommendation).2 Despite the uptick in adoption of voice-enabled virtual assistants, designing effective products is a nontrivial endeavor. Virtual assistants often deal with multiple, sometimes complex scenarios that require understanding a range of queries to which users expect a quick, accurate, and easily interpretable response.
In our experience, designing an intuitive and effective voice assistant is not as straightforward as combining structured and unstructured data with powerful AI capabilities such as natural language processing (NLP) and machine learning. Instead, virtual voice assistants require designers to match their technical capabilities and resources with human intuition and oversight. Voice assistant design is both art and science. This means incorporating sociological and geographical factors (such as accounting for regional accents), and simultaneously ensuring these voice assistants are properly calibrated to deliver messages in a conversational manner (e.g., proper tone and tenor). In this article, we explore “three Ts” of designing dynamic and flexible voice assistants: training, testing, and tuning.
A five-part series on conversational AI
Over the next year, we will discuss the implications and use cases of conversational AI. In this chapter, we discuss three Ts to developing effective voice assistants. In our remaining chapters, we leverage secondary research and case studies to explore the following topics:
Conversational AI makes its business case: The initial chapter of this series breaks down what constitutes conversational AI and the myriad ways companies can leverage its capabilities.
Acoustic authentication: Explains how conversational systems can enhance security protocols by integrating voice into the multiauthentication process.
Industry use cases: Highlights how virtual assistants appear to be changing the face of customer service in banking, technology, and health care.
The liability of conversational systems: Explores how the more we integrate conversational bots into our work and lives, the more we should take steps to understand their liability in terms of insurance, training, auditing, and the ethical implications.
Training the voice assistant: Matching human need with AI capabilities
There’s a paradox to designing voice assistants. While these assistants are underpinned by advanced AI and NLP capabilities, AI is only “smart” in a very narrow sense—that is, it is most effective at solving well-defined problems.3 But consider the nature of a conversation: It’s free-flowing, words and turns of phrase can take on multiple meanings based on context and tone, and at a moment’s notice, we can jump from one topic to another. So how do designers marry an expansive need, conversational interaction, with a traditionally narrow solution?
Human-assisted trainers. Perhaps, a common misperception is that voice assistants need to be everything to everyone. Instead, most are usually asked to perform relatively specific tasks such as responding to routine call center issues or helping people select an artist from their music library. With this in mind, designers can benefit from working directly with stakeholders to identify requirements and goals. At its core, this means solving well-defined problems that are easily tied to productivity measures (e.g., an airport voice assistant can measure how quickly and accurately it resolves customer queries).
In some of our earlier research, we found some of the best systems are designed directly with the communities that will interact with the AI solutions.4 That is, they benefit from making the human the focal point of the design process (also referred to as keeping the “human in the middle”). In the call center example, this means working with and observing how call center employees interact with customers. What are the routine inquiries? Are there more complex asks that trip employees up? When does confusion arise between employees and customers?
Understanding these common challenges empowers designers to map a high-level process flow of the call fulfillment process. As demonstrated in figure 1, these mappings create the underlying foundation for recording and organizing calls into a manageable data set populated with keywords and phrases.
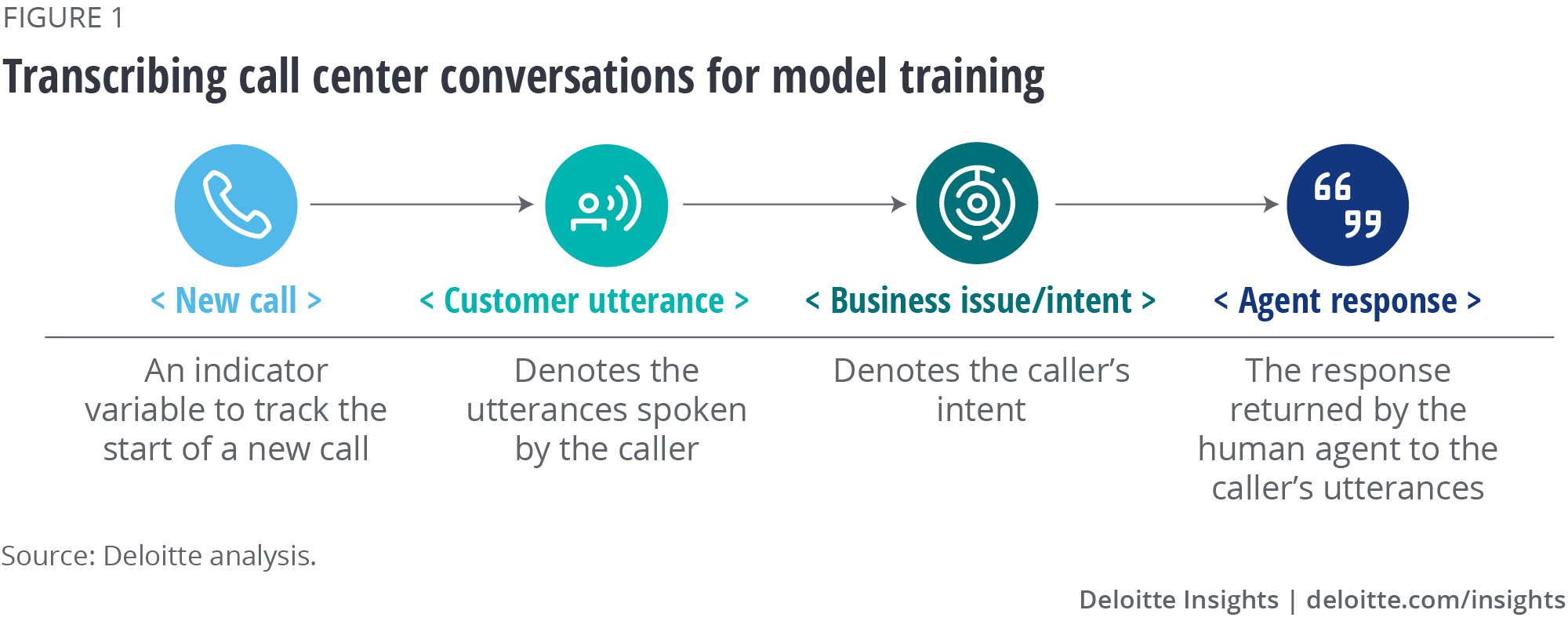
Indeed, figure 1 is a simplification of the data structure, but after the designers are able to properly categorize these conversations, millions of recorded conversations can be translated into text and processed through mappings similar to this example.
Training the right data for your AI solution. After designers map the high-level process flow, numerous data sources are processed to train the voice assistants. This starts with transcribing voice data to text and parsing it into “human utterances.” These utterances consist of speech broken up by pauses in conversation. These range from single words to clauses to complete sentences. As seen in figure 1, utterances could be structured into business issues and resolutions.
After transforming the unstructured text into structured utterances, machine learning techniques, such as clustering analysis, create incredibly granular groupings within the data to uncover common patterns in the conversation. At this point, more supervised algorithms provide confidence scores that subject matter experts can validate and, when appropriate, use to correct machine learning conclusions. Taken together, putting humans in the middle, coupled with machine learning, creates foundational insights that inform these prospective voice assistants.
Testing the voice assistant: Uncovering the many dimensions of “accuracy”
Testing a conversational system, such as a voice assistant, is more than ensuring that business issues are correctly mapped to resolutions. As many of us know from our own experiences, one-to-one conversations can easily be misinterpreted. If we aren’t familiar with an accent, we may misunderstand a question or if we are speaking to someone from a different geographical location, words can take on different meanings (for instance, “chaps” can mean a good friend or something a cowboy wears). Conversational systems are no different—except, unlike us, they lack the ability to understand context.
For these reasons, designers should build quality assurance metrics that stress-test their models across a number of user personas, including:
- Variations in geography. Like our above examples, this consists of validating that the system can accurately interpret accents and contextually understand keyword meanings across groups. Taking this further, it may mean testing the model across multiple languages.
- Historical contexts. The models typically work best when they incorporate past conversations. If a prior resolution didn’t properly address an issue, then it can come off as tone-deaf if the model recommends the same solution again.
- Adaptable to real-life situations. Voice assistants benefit from testing in real-world situations. For instance, can the voice assistant cut through the background noise of the morning commute on the subway?
- Behavioral modeling. How we say something impacts action—that is, conversational systems don’t naturally have good bedside manners (e.g., telling someone they have a low balance on their checking account can probably benefit from a delicate delivery). Instead, it’s on the designer to ensure the responses are said in a natural and pleasant manner that users will be open to accepting.
All four dimensions show the importance of uncovering and accounting for implicit bias. If the algorithm doesn’t understand a specific accent, then it could be trained on a biased data set. In this case, the designers should work back to the training data to create a more inclusive design. Fortunately, the testing process can help bring these issues to light.
Tuning for humans: Making conversations flow naturally
Voice assistants do not have to pass as humans, but they should be able to communicate in a pleasant and interpretable manner. In this spirit, designers can improve upon their voice assistants by tuning their models with a more natural delivery. Tuning a voice assistant includes:
- Pronunciation. Designers should build a pronunciation dictionary that standardizes the speech of reoccurring words.5 This reinforces the importance of focusing the goal of each voice assistant design to ensure a more manageable universe of words.
- Pauses. How pauses are deployed, both in their placement and duration, influence how natural a conversation sounds.6
- Pitch and pace. Since many languages, such as English, are atonal, the pitch and pace of words and sentences often convey a speaker’s feelings.7 For instance, rising intonations in the middle of a sentence indicate a speaker isn’t done talking, even if it’s followed by a pause. Further, a fast speaking pace can represent excitement, while a slower pace may indicate a more relaxed feel.
These natural changes in prosody work in concert to make conversations more natural and inviting. And with the help of virtual assistants, designers can deliver helpful conversations at scale.
The ever-improving assistant
Building an accurate and natural voice assistant is an iterative process. While we start with training, it doesn’t end with testing, and then tuning. Instead, each part of the process builds and iterates on the other. Implicit biases can occur during training, but testing can help designers uncover and address these biases; and if pauses are inappropriate, then the training data should be restructured to properly account for these natural breaks in conversation.
When designing your own voice assistants, remember:
- The business objective should dictate the design.
- Training, testing, and tuning are a dynamic process, with each step informing the other.
- The work is never done. This is an iterative process, where the former version continually informs and improves upon future releases.
By establishing a well-articulated goal, designers can continually improve upon their voice assistants to sound a bit more human with each iteration.
Deloitte Analytics and AI
Achieving your business outcomes, whether a small-scale program or an enterprise-wide initiative, demands ever-smarter insights—delivered faster than ever before. Doing that in today's complex, connected world requires the ability to combine a high-performance blend of humans with machines, automation with intelligence, and business analytics with data science. Welcome to the Age of With, where Deloitte translates the science of analytics—through our services, solutions, and capabilities—into reality for your business.
Learn more
Get on touch
- Sherry Comes
- Managing director, Applied AI practice, Conversational AI leader
- Deloitte Consulting LLP
- scomes@deloitte.com
- +1 720 325 3757
© 2021. See Terms of Use for more information.
Related content
Explore more on AI and cognitive technologies
-
 Conversation starters Article5 years ago
Conversation starters Article5 years ago -
 Intelligent interfaces Article6 years ago
Intelligent interfaces Article6 years ago -
 Smart speakers: Growth at a discount Article6 years ago
Smart speakers: Growth at a discount Article6 years ago -
 Beyond marketing: Experience reimagined Article6 years ago
Beyond marketing: Experience reimagined Article6 years ago -
 Artificial intelligence: From expert-only to everywhere Article6 years ago
Artificial intelligence: From expert-only to everywhere Article6 years ago -
 Automation with intelligence Article5 years ago
Automation with intelligence Article5 years ago
