How can organizations engineer quality software in the age of generative AI?
The first in a three-part series on maintaining software quality as organizations integrate gen AI and explore common design challenges and opportunities to optimize for quality
Faruk Muratovic
Jasmeet Gill
Diana Kearns-Manolatos
Ahmed Alibage
Generative AI is changing software development. Deloitte’s third quarter State of Generative AI in the Enterprise report reveals that over a third of 2,770 organizations surveyed have achieved limited or at-scale product implementations.1 And Deloitte’s separate foresight analysis suggests that, even in the most conservative scenario, gen AI will likely be embedded into nearly every company’s digital footprint by 2027.2
Additionally, gen AI is being integrated across the software development life cycle. Many organizations have used gen AI assistants to help develop product road maps. In financial services, Goldman Sachs has used auto-coding to improve developer proficiency by 20%.3 And Google’s AI Lab Incubator reported similar results from virtual assistants for developers.4 One health insurance company used COBOL code assist to enable a junior developer with no experience in the programming language to generate an explanation file with 95% accuracy and 54% faster than an experienced mainframe developer.5 Gen AI can help product, engineering, and security teams improve design, code, testing, security, and much more.6
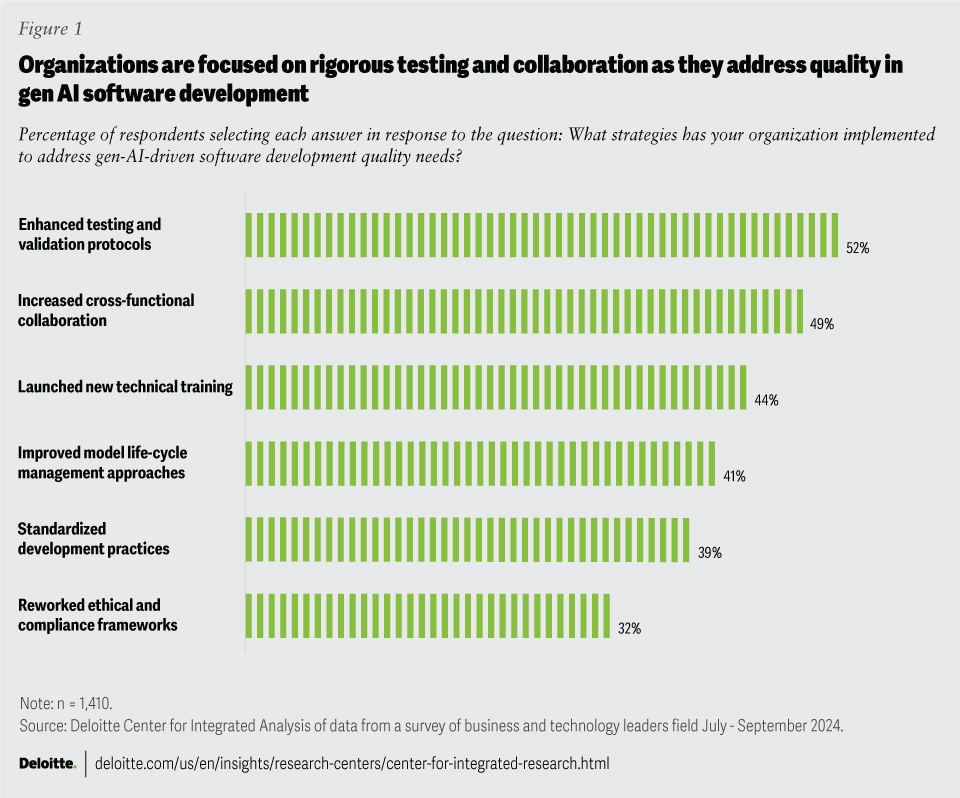
According to data from a Deloitte survey, over half of the global respondents have already prioritized enhanced testing and validation protocols to address gen AI-driven software development quality needs (figure 1). This focus on rigorous testing underscores the importance of ensuring gen AI’s reliability and accuracy. Additionally, nearly half have increased cross-functional collaboration, highlighting the necessity for diverse experience to effectively manage and improve gen AI outputs.
However, as gen AI integrates into software and the software development lifecycle (SDLC), new leading practices can emerge to safeguard and maintain quality, with different C-suite leaders playing unique roles. This three-part research series draws on an extensive literature review; more than 40 interviews of specialists related to software engineering, gen AI, and cyber security; and data analysis from Deloitte global surveys—the State of Generative AI in the Enterprise 2024 and the fourth edition of the Global Future of Cyber survey—to address how leaders can successfully integrate gen AI into digital products and across the software development lifecycle while maintaining software quality.
- Part 1 of this series examines how chief product officers, chief information officers, chief technology officers, and heads of engineering across industries can maintain the quality of digital products when integrating gen AI into the software development life cycle.
- Part 2 will guide chief data officers, chief data scientists, and CIOs to architect data environments that address gen AI software development needs for training data, public and private language learning models (LLMs), and achieving and maintaining model accuracy over time.
- Part 3 will show chief information security officers, CIOs, and CTOs how to get ahead of cyber risks such as sophisticated social engineering, prompt injection, and other pressing adversarial attacks.
Defining software quality
Our research defines software quality as the measure of a software product’s ability to satisfy specified requirements and user expectations through attributes such as robustness, reliability, efficiency, simplicity, security, and dependability. It reflects the software’s capability to perform its intended functions in a reliable manner, maintain security against unauthorized access and vulnerabilities, and operate efficiently with minimal resource waste, all while being easy to manage.7
Integral aspects of software quality include:
- Code quality: the correctness, readability/reusability, scalability, security, standardization, documentation, and overall efficiency of the code
- Model quality: the extent the model consistently and transparently achieves stated goals and outputs based on data, architecture, and training8
For all its potential benefits, gen AI also introduces new challenges to software quality, causing leaders to often act as usage scales. Product and engineering leaders, chief information and technology officers, data professionals, and cyber executives should work to proactively address new challenges and ensure the quality of their digital solutions.
Quality integration of gen AI into application design and development
Gen AI shows significant promise for product and engineering leaders. Its use in application design and development is expected to continue to gain momentum over the next three years.
Technology and engineering leaders are frequently searching user stories to help inform solution architecture and code update strategies. Automated coding assistants have shown early success.9 Additionally, developers can use gen AI to write unit tests more efficiently, enhancing code quality and accelerating outcomes.10
However, as gen AI is integrated into development, leaders should closely watch trade-offs between cost and quality11—especially risks of oversimplifying the inherent complexity across the solution architecture, code, databases, and more.12 As one specialist interviewed for this research said, “The benefit of using gen AI in engineering is that it simplifies something that is highly complex. The challenge of using gen AI in engineering is also that it simplifies something that is highly complex.”13
Below, we explore how organizations can overcome some of the challenges related to application design, address code quality concerns, and standardize practices across software engineering. Each proposed solution aims to pursue simplicity by managing complexity.
Problem 1: Application design can be opaque
Gen AI is being used by product and engineering leaders to codify business requirements, standardize design, and support knowledge transfer including transcribing calls, searching for user stories, visualizing systems through diagrams, or supporting tech architecture and code standards across hub-and-spoke development models.14 However, as usage scales, leaders should be mindful that results may be limited to known information and concepts. Product leaders may risk homogenized outcomes that lack human creativity.15
How can leaders solve for these issues?
Maintain design transparency and boundaries. When translating business requirements into actionable gen AI tasks, like unit tests, it’s important to maintain system explainability. Consider sticking to smaller search and prompt components. One technology team, for example, designed their system in small, perfected modules rather than attempting to develop it all at once. Product leaders, architects, and engineers should set clear architectural and data boundaries, to maintain functional transparency, mitigate technical debt and enable software quality across data exchanges.
Bring human-centered design practices upstream. Early gen AI programs should consider bringing human-centered design principles upstream in the development lifecycle. For example, users are engaging prompt engineers well ahead of traditional user acceptance testing steps to provide contextual input on how a user would prompt the solution. This approach moves iterative testing with real users and test scenarios from the end of the lifecycle, where they would typically be, into the first (design) stage.
Problem 2: Multi-agent solutions can bring synchronization dependencies
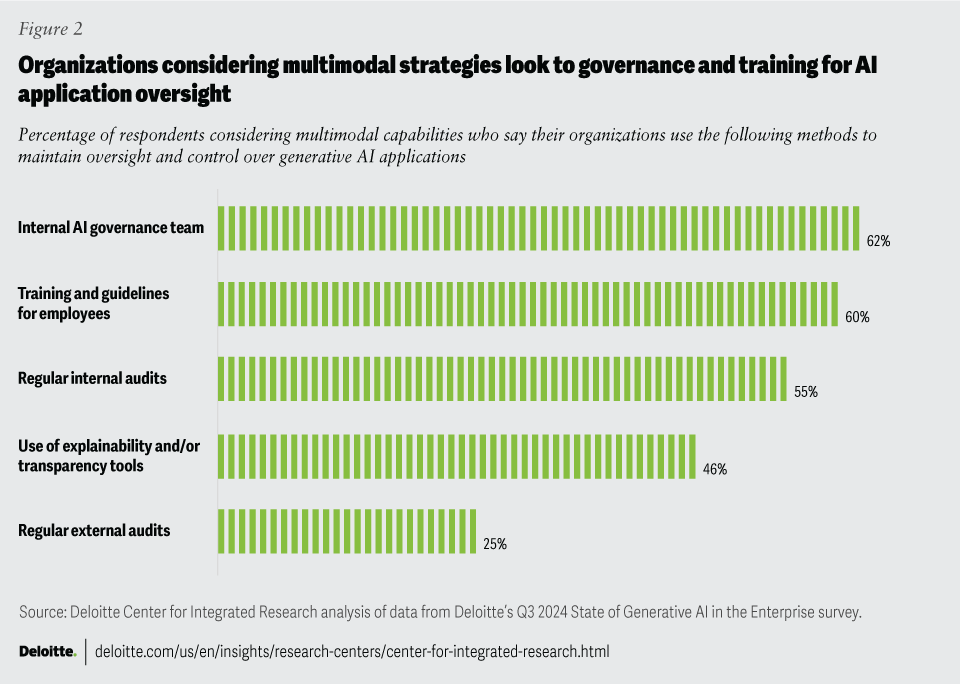
Most organizations are using publicly available LLMs which makes them more likely to require multimodal capabilities—systems that share common functions or models. Our analysis shows when respondents employ multimodal strategies, they’re also concerned about internal AI governance (62%), training (60%), and auditing and compliance (55%) (figure 2).
These multi-agent solutions can introduce synchronization problems that can directly affect software quality and reliability. For example, in a software system where agents are responsible for parts of a complex task, such as financial analysis, any information discrepancy can compound exponentially.16 An error in one agent’s output could cascade through the system.17 The complexity of managing multiple agents can make it more difficult to identify and resolve issues.
Additionally, computational resource management is paramount. One specialist said, “As the system scales, the complexity of managing and deploying these agents increases, making efficient resource allocation critical to maintaining system performance.”18 Mismanagement of tokens can lead to system throttling which not only increases costs but can also degrade performance under load. Energy spikes can raise costs and affect system reliability.19 If not effectively managed, these issues can eat into the anticipated cost savings and customer experience gains.
How can leaders address these challenges?
Contextualize architecture and build integrated platforms. It’s important to adopt the right architecture, considering the industry, ecosystem, and value chain objectives. This will have implications on the software’s velocity20 or ability to perform the required function at speed and in line with customer expectations. Given gen AI is a probabilistic model—a type of machine learning that incorporates uncertainty in its predictions21—solutions tend to perform best when they inherently require analyzing many common parameters.22
When considering the use of gen AI, it’s important to assess whether the complexity of the model matches the problem at hand. Smaller models with fewer parameters may suffice in addressing latency needs, but they may not offer the depth and flexibility required for more complex tasks. For example, one bank’s head of advanced analytics notes the company typically uses models with seven to 13 billion parameters, which is significantly smaller than the more than 73 billion parameters often found in larger models. However, when using large models, the trade-off is a deliberate choice, balancing performance needs with the computational efficiency the use case requires.
If a large model matches the problem at hand, many organizations are replatforming. One automotive company, for example, is taking a platform strategy that supports plugins and bakes in limits data governance and security, facilitating a portfolio to data services.23 Another tech company leader is implementing a centralized computing structure to support development teams across all stages.24
Leaders can also evaluate the need for single- versus multi-agent systems to choose the appropriate level of centralized or distributed authority to reduce complexity. Multi-agent syncing can be addressed in several ways. In addition to traditional orchestration tools, there are new resources that can enhance workflow cohesion across databases and applications,25 providing context for effective workflow integration. One telecommunications company’s approach emphasizes the importance of utilizing adaptable middleware, which helps prevent dependency on specific LLMs, allowing the company to stay agile as new advancements emerge.26
Optimize resource allocation for load management. As more gen AI agents are engaged, adaptive scaling mechanisms that dynamically adjust the number of agents based on real-time performance and resource utilization can help system efficiency under varying loads.27 In some scenarios, leaders are dynamically generating new agents on the fly to meet current needs and avoid system overload.28 Others are developing resource allocation models to optimize token consumption29 and dynamically allocate computational resources based on agent or task-level demands.30 Techniques such as data caching, which locally stores frequently accessed information, and load balancing, which evenly distributes tasks across agents, are often critical to preventing system overload.31
Problem 3: Code efficiency and accuracy can be hard to balance
While productivity gains from using generative coding tools can be substantial, inaccurate gen AI results32 can be especially challenging for less experienced developers to identify.33 As of November 2023, 45% of respondents in the Deloitte State of Generative AI in the Enterprise survey used gen AI for coding, but 38% lacked confidence in the results.34 Studies show that code generation quality varies significantly with prompt complexity; success rates drop from 90% for simple prompts to 42% for complex ones.35 Similarly, since 2021, the proficiency in generating functional code for “easy” coding problems has declined from 89% to 52%, and the ability to produce functional code for “hard” coding problems dropped from 40% to just 0.66% over the same period.36 Examples like this highlight the importance of assessing output accuracy.37
What are potential solutions?
Implement new code review metrics. Our research interviews identified several measures that can help discern good code from bad. One method is to evaluate the frequency with which human reviewers in a human-in-the-loop model—a system design approach where human judgment is incorporated into the decision-making process of an automated system—deem code satisfactory for repository commitment. This includes tracking both the acceptance and rejection rates of code submissions.
Organizations can also monitor application program interface (API) leakage across application connections and the number of times code is discarded or uncommitted. These metrics can help assess the overall efficiency and success rate of code integration, which can vary based on task complexity, capabilities, and standards.
Code documentation, tokenizers in LLMs, and other tools that provide code context can maintain system transparency and enhance developer understanding of standards and dependencies.38
Problem 4: Code simplicity and code complexity could be at odds
Another potential concern is generating unnecessarily complex code that is too long,39 inefficient, unstandardized, and latent with technical debt.40 While companies like Amazon41 have used gen AI tools to save thousands of developer-years and millions of dollars in costs, this efficiency may come with a caveat. Rapid code automation can introduce risk and complexity that could burden the codebase in the long term. The exponential growth of codebases could impact how solutions perform under stress, leading to financial losses.42
Conversely, oversimplification is a risk that might not become apparent until the system faces real-world stress, where missing elements could lead to real problems. Code that works well on local machines might not perform the same in production environments with high user volumes and API calls, which could lead to unexpected failures.
Users should be cautious when using gen AI to address unfamiliar problems. MIT’s Computer Science and Artificial Intelligence Laboratory conducted a study showing that LLMs might struggle with reasoning in the face of unfamiliar problems and diverse situations. In the future, junior programmers may depend on LLMs without fully understanding the underlying code, risking a decline in code comprehension skills.43
What can tech leaders do?
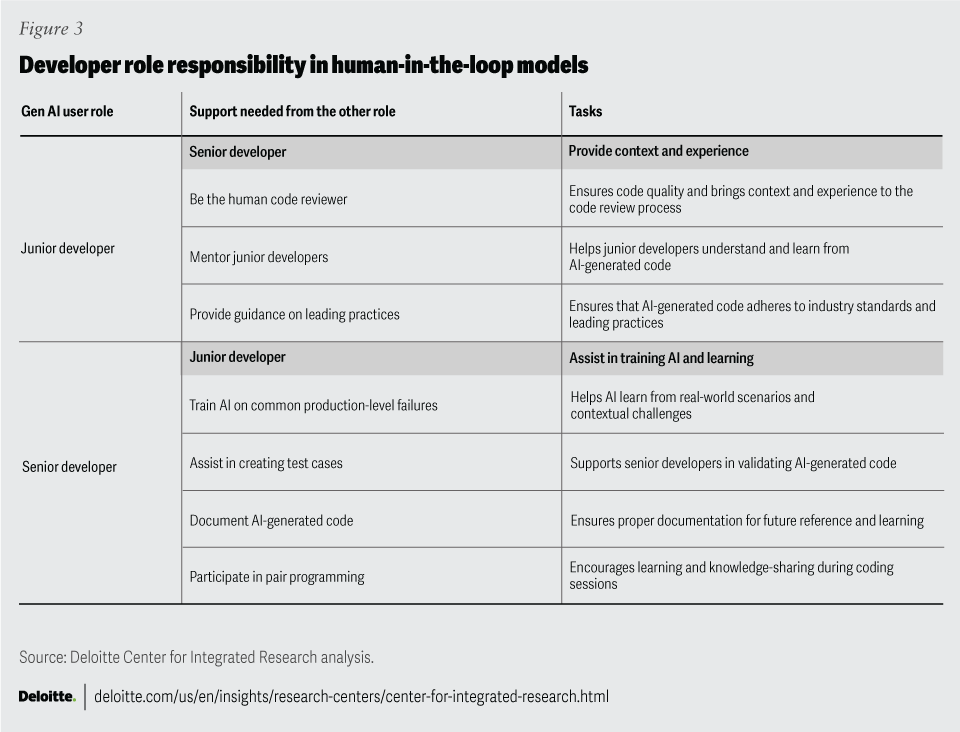
Evolve code review to account for human-in-the-loop as the new standard. With gen AI, the developer's role can shift from writing code to defining architecture,44 reviewing code, and orchestrating functionality through contextualized prompt engineering.45
Human-in-the-loop code review is expected to be the standard for gen AI automated coding tools for the next two to three years. Leaders can simulate how gen AI integration will impact code reviews across multiple roles—for a senior developer versus a junior developer, for example—to ensure responsibility and accountability remain with human overseers (figure 3).
Problem 5: Non-standardized inputs and outputs can make testing challenging
While gen AI is often being used successfully to create standardized output in situations where a set of requirements have been defined for the model,46 there is still a risk of non-standardized responses. A gen AI prompt, for example, might generate 20 different replies or images for the same command. This can pose unique challenges when testing gen AI solutions, given there is an element of randomness.47
Gen AI’s effectiveness depends heavily on the quality of the prompts provided by humans. While there are expert prompt engineers, the supply hasn’t yet caught up with the growing demand across various types of LLMs—speech, audio, text, and code.48 What’s more, many non-expert users will also be engaging with prompts without knowledge of their known (and unknown) universe. This underscores a critical limitation: gen AI operates strictly within the confines of a prompt and can’t independently adjust.
How can we fix this problem?
Create a prompt engineering center of excellence with test libraries and personas. A prompt testing Center of Excellence (COE) that specializes in prompt engineering can be important for maintaining a centralized library of reusable prompts and personas, enhancing scalability, and consistency. This COE can help refine prompts and assess their accuracy.49 For complex projects, contextualizing prompts by breaking down issues into manageable subcomponents, akin to a microservices architecture, can help integrate independent components50 and guardrails (figure 4).
Given prompt engineering is a new field, there is a significant need for targeted training for anyone interacting with the model to understand the parameters and scope of its training. While business leaders may not require deep technical knowledge of prompt engineering, they should still understand its strategic implications, such as its impact on operational efficiency and product development. Some advanced companies are employing a hub and spoke model to adapt prompts to specific business needs more effectively, centralizing expertise in a hub team of prompt engineers, while business units serve as spokes to consistently customize prompts as solutions scale.
Problem 6: DevSecOps has not yet adjusted to account for automated agents
Gen AI used to accelerate software development fundamentally impacts operations,51 especially in sectors with stringent security and compliance requirements, such as health care and finance.52 One major hurdle is retrofitting gen AI into established development, security, and operations working and governance processes.53
Given most companies have worked toward agile development, there may be new hurdles related to accountability if gen AI fails. For example, if gen AI pulls bad code from a library into a product, who is accountable? Engineers, business leaders, and customers each experience the impact of gen AI on software quality differently. Senior engineers are typically the most involved in assessing the technical quality and ensuring integration aligns with development standards. However, business leaders and customers may feel a broader range of impacts, as they are ultimately accountable for the strategic and financial outcomes.
Organizations can consider several key steps to optimize their processes.
Revamp development operations. Product engineering teams should have a clear, structured process with consistent standards to improve handoffs between designers, developers, and testers.54 Most modern engineering teams have moved to agile processes. For them, continuous integration and continuous delivery approaches may need to compress to account for integrated prompt engineering. In select cases, like critical infrastructure, a waterfall methodology may help maintain inherent checks and balances, with built-in accountability.55
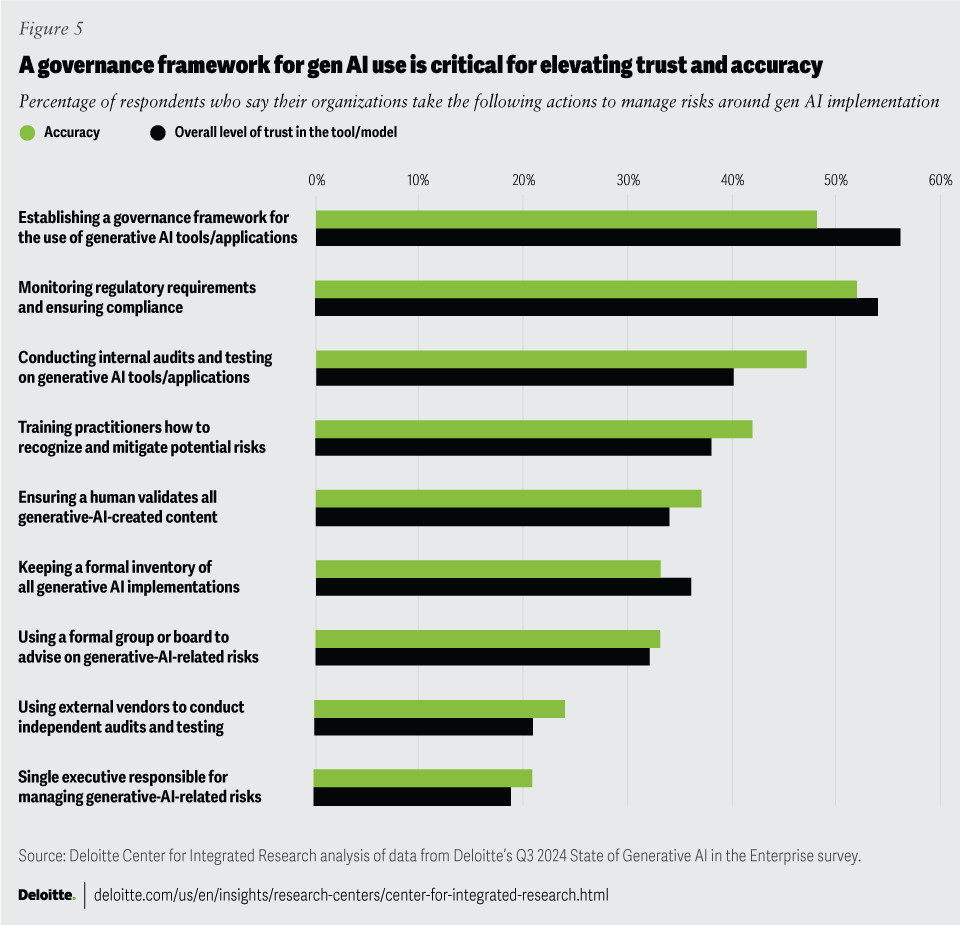
According to Deloitte’s third quarter 2024 State of Generative AI in the Enterprise report, 56% of surveyed organizations say that establishing a governance framework for the use of gen AI is key to mitigating risk related to trust in the tool.56 The data signals a trend toward formalized, structured approaches to managing the risks associated with gen AI (figure 5).57
Deloitte’s survey data further reveals the importance of training,58 with 38% of respondents seeking a high level of trust in AI tools implementing training and guidelines for employees and 42% of respondents focused on accuracy emphasizing its importance for recognizing and mitigating potential risks.
Define gaps in human accountability for gen AI outputs. Traditionally, in the pod model, accountability is shared among cross-functional teams, which are collectively responsible for successes and failures. This approach is proving effective for gen AI implementations where each team member needs to perform various roles, fostering a resilient and versatile team dynamic.59 A conversational mindset, rather than a typical problem-solving approach, can establish a culture of responsibility, transparency and accountability.60 Issues can be redirected based on the nature of the problem. For code-related issues, the tech lead or architect of the pod is responsible, whereas a user acceptance subtask issue falls to the product owner.61
Modernize DevSecOps from a relay-style workflow to a synchronized approach. Gen AI is transforming traditional software development processes by automating tasks and blurring the lines between roles such as design, development, and testing. Historically, development functions were segmented across sprints based on personas, but gen AI enables a more integrated approach. By fetching data automatically and suggesting next steps, gen AI can reduce the time and effort engineers spend gathering information from multiple sources. This shift suggests an evolution of DevSecOps processes, moving from a relay-style workflow to a synchronized approach where tasks can be shared horizontally. Additionally, a feedback loop can be important to maintain continuous integration and delivery.62
Problem 7: Innovation limitations
Gen AI, by design, relies on historical data to generate images, text, audio, and other mediums. Its creations are bounded by the constraints of the information used to program it.
Additionally, when code is generated by AI, it raises questions about the ownership of the code and intellectual property rights.63 Copyright ownership can become ambiguous—does it belong to the developer, the company, or the AI?
Open-source license tainting becomes a bigger issue for companies to manage when they copy licenses from open-source code,64 which could make protecting software IP rights more challenging in the future.65 This overlaps with an organization’s ability to copyright, own, or transform ownership of AI-generated or even AI-modified code66 and what is covered under technology provider indemnifications. Gen AI introduces code ownership ambiguities.
What steps can be taken?
Account for AI-innovation ownership in the short-term and AI-reasoning advancements in the long-term. Over the past year, many companies have started to streamline contract processes by clarifying that any code, whether created by humans or gen AI tools, belongs to the client. This policy can simplify contracts and speed up negotiations, reducing delays in project initiation. By explicitly stating code ownership in contracts, companies can expedite the early stages of collaboration.67
As leaders contemplate future strategies for fostering innovation, integrating everyday language for contextual understanding68 and incorporating organization-specific terminology can help expand the universe of contextual comprehension. For example, one bank has tailored its gen AI models to include specific organizational terminology and grammatical structures to boost model precision and functionality. In essence, if gen AI operates within certain limitations, expanding the box of its capabilities can broaden its contextual understanding and layering outputs with human ingenuity.69
Enhance innovation through hybrid human-AI collaboration, continuous learning, and cross-disciplinary integration. Combining human creativity with AI’s computational power in hybrid human-AI collaborations can enhance innovation, as humans provide creative insights while AI processes scenarios efficiently. Continuous learning mechanisms help keep AI models relevant by adapting to new data and trends. Improved data management practices, including data augmentation and bias mitigation, help ensure high-quality datasets, expanding gen AI’s potential. Cross-disciplinary integration fosters innovative solutions by incorporating diverse domain insights. Incentivizing innovation through challenges and rewards can motivate teams to push gen AI boundaries, encouraging experimentation and breakthrough innovations.70
Achieving the promise of gen AI solutions in software development
As with any innovative technology, implementation challenges are to be expected. It’s how organizations address them as they adopt and scale gen AI that will likely differentiate those who succeed. Software development is a complex function, but the challenges are surmountable. This research underscores that leaders can navigate them effectively by implementing a robust set of emerging gen AI strategies. Modular approaches, continuous learning, and contextual approaches are important for quality control over gen AI implementations. These actions together can help product leaders and engineers ensure a high standard of software quality and performance, minimizing the accrual of technical debt and enabling long-term sustainability in software development.
As the space evolves, technology vendors will likely develop tools to address many of these challenges, so organizations should focus on the integration of the whole lifecycle to operationalize the change and achieve efficiencies with a clear strategy, integrated platform, and value-led mindset.
In the next part of this research series, we’ll explore the emerging challenges and solutions facing data architects, engineers, and scientists in the data environment and across the model lifecycle as they enable organizations to achieve gen AI’s promise.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}