The Future of Extract, Transform & Load tools | Part I has been saved

Article
The Future of Extract, Transform & Load tools | Part I
A view on the changing ETL landscape within big data
The volume, size and speed of data is increasing. While data integration remains to be a fundamental component of a (big) data analytics platform, the tools of data integration are changing.
Traditional ETL was a key component of the data warehousing environment. The main goal of ETL was to extract data from multiple data sources, transform the data according to business rules and load it to the target database. A traditional ETL process can take anything from a couple of hours or a day to complete. The ETL jobs are primarily batch driven and relational, developed and executed with a mature ETL tool.
However, the world of data is constantly evolving. Internet of Things (IoT) can be seen as one of the drivers of the evolving data size and speed of data, considering the IoT datasets which include sensor data, video feeds, mobile geolocation data, product usage data, social media data, and log files. This change in data volume, type and incoming speed, calls for platforms which can inexpensively process this high volume data in situ, i.e., in the context in which it physically lives and transform it at real-time streaming rate to keep up with its incoming speed.
With these changed requirements for ETL processing, the question arises - are the traditional ETL tools equipped to process big data? In this first article, of a two-article series, we explore the current role of the ETL tools in the data warehouse environment and the new requirements from ETL with the influx of big data.
The current role of ETL
ETL tools combine three important functions: extract, transform and load. These functions are required to get data from one data environment and put it into another data environment.
A typical data warehouse architecture extracts data from the source systems (data stored in form of databases, flat files, web services, etc.), followed by the ETL component that combines and transforms the data and loads it to the data warehouse. The data stream ends at the data marts or leading to reporting and analytics streams defined on top of the data warehouse.
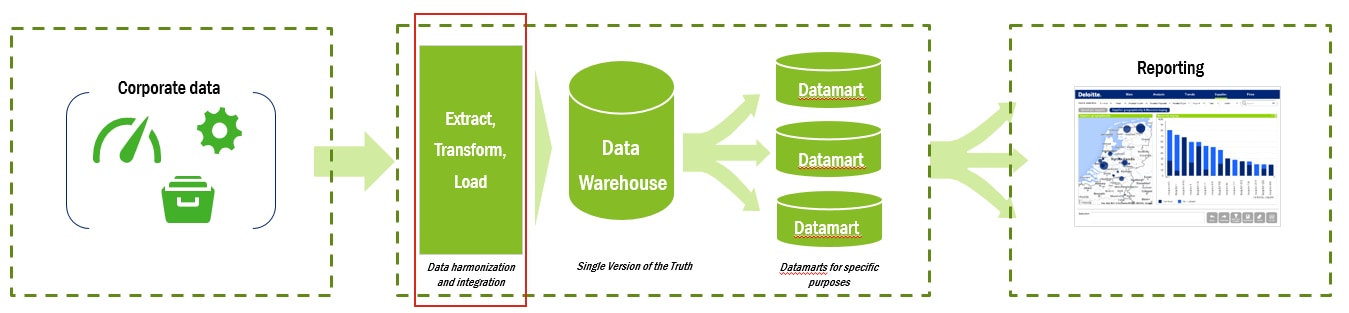
The limitation of traditional ETL is that it focused on relational processing, and as the data grows in size over time, the performance of the ETL process starts deteriorating.
Furthermore, ETL was aligned with the Schema-on-Write approach, used in database architectures over the years. With Schema-on-Write, you start by defining your schema, then you process/transform and load the data using the ETL process, then you read your data and it comes back in the schema you defined in the first step. This means you have to know how you are going to use the data beforehand.
To overcome those limitations, the Schema-on-Read approach has attracted more and more attention.
The future role of ETL... is ELT
The Hadoop Distributed File System is the classical example of the Schema-on-Read approach. With Schema-On-Read you read and store the data in its original form. When you are ready to use the data, then, at that time, you define the elements required to accomplish the task. So, instead of loading the data in a predefined schema once you receive the data, you defer the modelling to the moment you need the data.
Under primary successful use cases for Hadoop, Gartner mentions Traditional ETL - ‘Hadoop is being used successfully to augment and replace traditional extract, transform, load (ETL) environments’
With the advent of semi-structured, poly-structured, and unstructured data, the Schema-on-Read approach is gaining precedence as it allows you to load your data as-is and start to get value from it right away. This has transformed the ‘Extract-Transform-Load’ approach to an ‘Extract-Load-Transform’ approach.
The above change from ETL to ELT is just one example of how the traditional ETL environment is changing. To build ETL for the future, we need to focus on the data streams rather than the tools. We need to take in account the real-time latency, source control, schema evolution, and continuous integration and deployment.
Future ETL will be providing a data management framework – comprehensive and hybrid approach for managing big data. ETL solutions will encompass not only data integration but also data governance, data quality, and data security. They will be scalable, versatile, high-performance and flexible in order to be able to support the data-driven business initiatives and imperatives.
Continue reading with our second ETL article in this series, where we show how existing ETL tools are coping with these changes and discuss future applications & approaches for ETL.

Contact
