Smarter, not harder: Beyond brute force compute
Businesses are getting more out of their existing infrastructure and adding cutting-edge hardware to speed up processes. Soon, some will look beyond binary computing entirely.
As technology has become a bigger differentiator for enterprises, businesses have built ever-more computationally complex workloads. Training artificial intelligence models, performing complex simulations, and building digital twins of real-world environments requires major computing resources, and these types of advanced workloads are beginning to strain organizations’ existing infrastructure. Typical cloud services still provide more than enough functionality for most business-as-usual operations, but for the cutting-edge use cases that drive competitive advantage, organizations now require highly optimized and specialized computing environments.1
Optimizing code bases for the hardware they run on is likely the first step toward speeding up business applications. An area that’s long been overlooked, this optimization can provide significant performance gains. Beyond that, emerging hardware geared specifically for training AI and other advanced processes is becoming an enterprise mainstay. Graphics processing units (GPUs), AI chips, and, one day, quantum and neuromorphic computers are beginning to define the next era of computing.
Most advances in computing performance have focused on how to get more zeros and ones through a circuit faster. That’s still a fertile field, but, as we’re starting to see, it may not be for much longer. This is leading researchers and tech companies to look for innovative ways to navigate around—rather than through—constraints on computing performance. In the process, they could be laying the groundwork for a new paradigm in enterprise computation in which central processing units (CPUs) work hand in hand with specialized hardware, some based in silicon, others, potentially not.
Now: Past performance not indicative of future returns
The last 50 or so years of computing—and economic—progress have been shaped by Moore’s Law, the idea that the number of transistors on computer chips, and therefore performance, roughly doubles every two years.2
However, chipmakers are increasingly running into physical constraints. At a certain point, there are only so many transistors a piece of silicon can hold. Some observers believe Moore’s Law is already no longer valid.3 This is contested, but at the very least, the end of the runway may be coming into view. Chips are getting both more power-hungry and harder to cool, which hampers performance,4 so even as chip manufacturers add more transistors, performance doesn’t necessarily improve.
All this comes at a bad time: Businesses are increasingly moving toward computationally intensive workloads. Industrial automation is ramping up, with many companies developing digital twins of their real-world processes. They’re also increasingly deploying connected devices and the Internet of Things, both of which create huge amounts of data and push up processing requirements. Machine learning, especially generative AI, demands complex algorithms that crunch terabytes of data during training. Each of these endeavors stands to become major competitive differentiators for enterprises, but it’s not feasible to run them on standard on-premises infrastructure. Cloud services, meanwhile, can help bring much-needed scale, but may become cost-prohibitive.5
The slowing pace of CPU performance progress won’t just impact businesses’ bottom lines. NVIDIA CEO Jensen Huang said in his GTC conference keynote address that every business and government is trying to get to net-zero carbon emissions today, but doing so will be difficult while increasing demand for traditional computation: “Without Moore’s Law, as computing surges, data center power use is skyrocketing.”6
After a certain point, growing your data center or increasing your cloud spend to get better performance stops making economic sense. Traditional cloud services are still the best option for enabling and standardizing back-office processes such as customer relationship management, enterprise resource planning (ERP), enterprise asset management, and human capital management. But running use cases that drive growth, such as AI and smart facilities, in traditional cloud resources could eventually eat entire enterprise IT budgets. New approaches, including specialized high-performance computing, are necessary.7
New: Making hardware and software work smarter, not harder
Just because advances in traditional computing performance may be slowing down doesn’t mean leaders have to pump the brakes on their plans. Emerging approaches that speed up processing could play an important role in driving the business forward.
Simple
When CPU performance increased reliably and predictably every year or two, it wasn’t the end of the world if code was written inefficiently and got a little bloated. Now, however, as performance improvements slow down, it’s more important for engineers to be efficient with their code. It may be possible for enterprises to see substantial performance improvements through leaner code, even while the hardware executing this code stays the same.8
A good time to take on this task is typically during a cloud migration. But directly migrating older code, such as COBOL on a mainframe, can result in bloated and inefficient code.9 Refactoring applications to a more contemporary code such as Java can enable enterprises to take advantage of the modern features of the cloud and help eliminate this problem.
The State of Utah’s Office of Recovery Services recently completely a cloud migration of its primary case management and accounting system. It used an automated refactoring tool to transform its code from COBOL to Java and has since seen performance improvements.
“It’s been much faster for our application,” says Bart Mason, technology lead at the Office of Recovery Services. “We were able to take the functionality that was on the mainframe, convert the code to Java, and today it’s much faster than the mainframe.”10
Situated
Using the right resources for the compute task has helped Belgian retailer, Colruyt Group, embark on an ambitious innovation journey that involves automating the warehouses where it stores merchandise, using computer vision to track and manage inventory levels, and developing autonomous vehicles that will one day deliver merchandise to customers.
One way to manage the compute workload is to leverage whatever resources are available. Brechtel Dero, division manager at Colruyt Group, says thanks to the proliferation in smart devices, the company had plenty of computation resources available.11 However, many of these resources were in operational technologies and weren’t tied to the company’s more traditional digital infrastructure. Developing that connective tissue was initially a challenge. But Dero says Colruyt benefitted from a supportive CEO who pushed for innovation. On the technical side, the company operates a flexible ERP environment that allows for integration of data from a variety of sources. This served as the backbone for the integration between information and operations technology.
“It’s about closing the gap between IT and OT, because machines are getting much smarter,” Dero says. “If you can have a seamless integration between your IT environment, ERP environment, and machines, and do it so that the loads and compute happen in the right place with the right interactions, we can make the extra step in improving our efficiency.”12
Specialized
Smarter coding and better use of existing compute resources could help enterprises speed up many of their processes, but for a certain class of problems, businesses are increasingly turning to specialized hardware. GPUs have become the go-to resource for training AI models, a technology that is set to drive huge advances in operational efficiency and enterprise innovation.
As the name suggests, GPUs were originally engineered to make graphics run more smoothly. But along the way, developers realized that the GPUs’ parallel data-processing properties could streamline AI model training, which involves feeding terabytes of data through algorithms, representing one of the most computationally intensive workloads organizations face today. GPUs break problems down into small parts and process them at once; CPUs process data sequentially. When you’re training an AI algorithm on millions of data points, parallel processing is essential.13 Since generative AI has gone mainstream, the ability to train and run models quickly has become a business imperative.
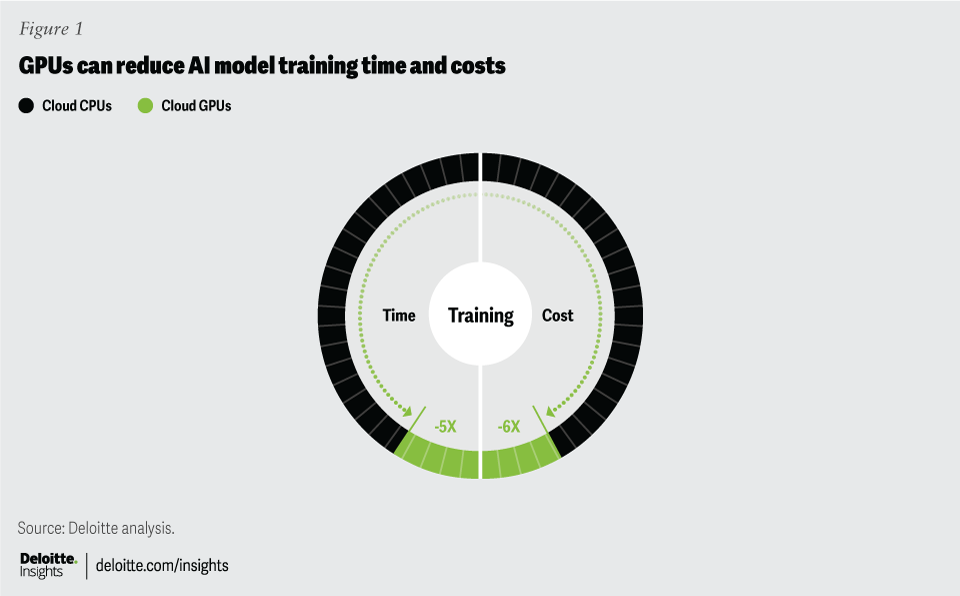
Large tech and social media companies as well as leading research, telecom, and marketing companies are deploying their own GPUs on their premises.14 For more typical enterprises, however, using GPUs on the cloud is likely to be the most common approach. Research shows cloud GPUs reduce AI model training costs by six times and training time by five times compared with training models on traditional CPUs on the cloud (figure 1).15 Most leading chip manufacturers are offering GPU products and services today, including AMD, Intel, and NVIDIA.
However, GPUs aren’t the only specialized hardware for training AI models. Amazon offers a chip called Inferentia, which it says aims to train generative AI, including large language models. These chips are built to handle large volumes of data while using less power than traditional processing units.16
Google also is in the AI chip game. It offers a product it calls Tensor Processing Units, or TPUs, which it makes available through the Google Cloud service. These processors fall under the category of application-specific integrated circuits, optimized to handle matrix operations, which underlie most machine learning models.17
Specialized AI chips are likely to continue to gain prominence in enterprise settings in the coming months as businesses realize the value of generative AI. Increased adoption of AI may strain most organizations’ existing data center infrastructure, and the higher performance of custom chips compared with general-purpose resources could become a major competitive differentiator.
This doesn’t mean enterprises will reap these benefits overnight. Historically, there’s always been a lag between the wide availability of specialized hardware and the development of standards and ecosystems necessary for using hardware to its fullest. It could be years before enterprises move at pace to adopt these innovations. Enterprises can develop ecosystem partnerships to prepare for emerging technologies and have ready the skills needed to take advantage of these innovations as soon as the business case is ripe.
Next: Beyond binary
The beauty of the CPU has always been its flexibility. It can power everything from spreadsheets to graphic design software. For decades, enterprises could run just about any application on commodity hardware without having to think twice.
But researchers and tech companies are developing new approaches to processing data and building entirely new worlds of possibilities in the process. One of the most promising new paradigms may be quantum computing—a technology that’s been discussed for years and whose impact is becoming clearer.
Quantum annealing is likely to be one of the first enterprise-ready applications of quantum computing, promising a new route to solving optimization tasks such as the traveling salesperson problem.18 These types of problems have traditionally been attacked using machine learning. But due to the complexity of optimization problems, the underlying math, and therefore computation, gets incredibly intricate, while still delivering less-than-perfect answers.
But quantum annealing uses the physical attributes of quantum bits to find an optimal solution, enabling quantum computers to find solutions to notoriously complex problems that involve a high number of variables—such as space launch scheduling, financial modeling, and route optimization.19 Quantum annealing can find solutions faster while demanding less data and consuming less energy than traditional approaches.
Quantum annealing may be the first widely available application of quantum computers, but it’s not likely to be the last. The technology is maturing rapidly and could soon be applied to a range of problems to which classical computers are poorly suited today. Quantum computers process information in fundamentally different ways than classical computers, which allows them to explore challenges from a different perspective. Problems involving large amounts of data over long periods of time are potentially a good fit. For example, IBM recently worked with Boeing to explore how quantum computing could be applied to engineer stronger, lighter materials and find new ways to prevent corrosion.
“It is time to look at quantum computers as tools for scientific discovery,” says Katie Pizzolato, director of theory and quantum computational science at IBM Quantum.20 “In the history of the development of classical computers, as they got bigger, we found amazing things to do with them. That’s where quantum is today. The systems are getting to a size where they’re competitive with classical computers, and now we need to find the problems where they provide utility.”
Quantum computers represent an entirely new way of performing calculations on data compared with our current state of binary computation, but it’s not the only new approach. Another promising field is neuromorphic computing. This approach takes its inspiration from the neuron-synapse connections of the human brain. Rather than a series of transistors processing data in sequence, transistors are networked, much like brain neurons, and computing power increases with the number of connections, not just transistors. The major benefit is the potential for increased performance without increased power.21
Better AI applications are the most likely use case for neuromorphic computing. While it’s still early days for this computing approach, it’s easy to see how a computer that is modeled on the human brain could give a boost to cognitive applications. Natural language understanding, sensing, robotics, and brain-computer interfaces are all promising use cases for neuromorphic computing. The field is still relatively new, but it has the backing of computing heavyweights such as IBM, which is developing a neuromorphic chip called TrueNorth,22 and Intel, which just introduced the second generation of its research-grade chip, Loihi.23
Optical computing is another promising approach. Here, processors use light waves to move and store data, rather than electrons crawling across circuit boards. The advantage is that data is literally moving at the speed of light. This field is less developed than quantum and neuromorphic computing, but research is underway at major technology companies, such as IBM and Microsoft.24
The common advantage to all these paradigms is using lower power than CPUs or GPUs while achieving similar, and potentially better, performance. This is likely to become even more important in the years ahead as businesses and nations as a whole push toward net-zero carbon emissions. Demand for faster and more pervasive computing is only going to increase, but simply spinning up more traditional cloud instances isn’t going to be an option if businesses are serious about hitting their targets.
This doesn’t mean these technologies are going to be a panacea for tech-related climate worries. There are still concerns around cooling and water use for quantum, and, as with any form of computing, bulky code could drive up energy requirements for technologies such as neuromorphic computing. The need for simplified code will persist, even as new computing options unfold.
These innovations aren’t likely to replace CPUs at any point. Traditional computing resources remain the most useful and trustworthy tools for the vast majority of enterprise workloads, and that’s not likely to change. But businesses may be able to advance their most innovative programs by incorporating some of these technologies into their infrastructure in the future. And just as we’re seeing cloud services that combine CPUs and GPUs in one product today, future offerings from hyperscalers may add quantum, neuromorphic, or optical capabilities to their products, so engineers may not need to even think about what kind of hardware is running their workloads.
Our informational worlds today are defined by zeros and ones, and, without a doubt, this model has taken us far. But the future looks ready to lean into the near-limitless possibilities of not-only-digital computing, and this could drive a new era of innovation whose outlines we’re only just beginning to see.

{kind=link}