デジタルフォレンジック調査におけるドキュメントレビュー ブックマークが追加されました

ナレッジ
デジタルフォレンジック調査におけるドキュメントレビュー
クライシスマネジメントメールマガジン 第77号
近年、企業において不祥事が発生すると、かなりの割合で「第三者委員会」「特別調査委員会」「内部調査員会」等が設置されるようになりました。本稿では、これらの調査でほぼ必須で実施される手続き―電子メール等に保存されたデータ、特にコミュニケーションデータから手がかりを見つけるデジタルフォレンジック調査におけるドキュメントレビューについて解説します。
I. ドキュメントレビューとは
ドキュメントレビューとは、訴訟対応・不正調査等に伴い実施するデジタルフォレンジック調査において、膨大なデータの中から調査の観点に関連性のあるデータを漏れなく適切に見つける手続きである。ドキュメントレビューを通して事実をより深く理解するとともに、レビューの結果によっては調査方針が修正され、追加のデータ保全につながることもある。また、当初の調査目的ではない不正が見つかることで、調査範囲が拡大することもある。ドキュメントレビューは米国民事訴訟手続きであるeDiscovery(電子データの開示手続)における標準ワークフローのEDRM(Electronic Discovery Reference Model:電子情報開示参考モデル)と呼ばれるeDiscovery業務に関わる企業や法律事務所等に参照される標準的なモデルの1つの要素でもある。
ドキュメントレビューの対象となるデータは、調査対象のコンピュータ、スマートフォン、サーバー等から取得されたデータである。大量のデータの中から効果的なレビューを実施するために事前にキーワードや期間等により絞り込みを行う。これら絞り込みをかけたデータ(メール、ショートメッセージ、チャット、各種ドキュメント、画像データ等)を、プロトコルと呼ばれる調査概要書に記載された条件に基づき、レビュー担当者が目視でデータを振り分けていく。これらの作業は、網羅的、効率的、かつセキュアな環境で調査を実施するために、専用のプラットフォームが使用されるのが通常である。
データの絞り込みは、その事案のやり取りで頻出することが想定される単語・表現を元に検索用キーワードを作成して検索する、調査対象期間を区切る、メールやチャットのやり取りの送信者と受信者を絞る、メールのドメインで絞る等がある。
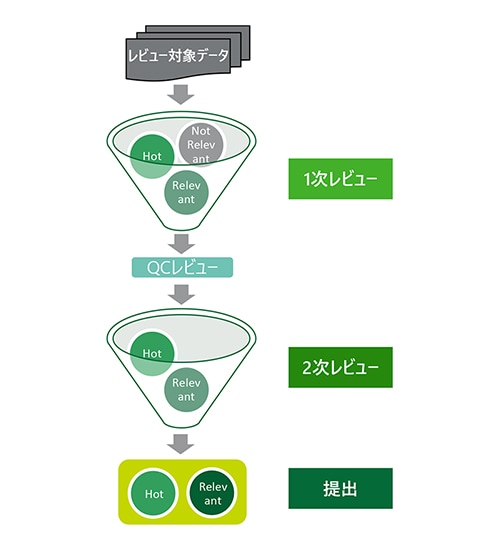
その後、実際に人の目でデータを確認する「レビュー」作業を行うことになるが、一般的なレビューの進め方は以下の通りである。まず、1次レビューにおいて、データの性質により大まかに分類を行う。1次レビューを行う目的は、キーワード検索等のシステムでふるい落とすことができない無関係なデーを取り除き、2次レビューで精査するためのデータを見つけだすことである。「Hot」(重要/事実を明確に裏付ける)、「Relevant」(関連性あり)、「Not Relevant」(関連性なし)等の仕分けを行うのが通常である。1次レビューを行ったデータは、QC(Quality Control)レビューにて内容を確認した後に、事案の内容を理解している会計士や弁護士等による2次レビューが実施される。2次レビューにて「Hot」もしくは「Relevant」と判断されたデータについて、調査委員会やクライアント企業等へ提出される。
II. ドキュメントレビュー対象データの変遷
近年におけるデジタル化の進展により、日々生成されるデータ量が爆発的に増え続けている。世界のデータ総量(生成、取得、複製、消費されるデータの総量)は今後も増加し続け、2025年には180ゼタバイト*1以上になり、その10年前と比較すると10倍以上に達すると予測されている。*2以前は、企業が保有するデータの量もそれほど多くなかったため、対象期間やキーワード検索により絞り込みをかけたデータを“人海戦術”でレビューすることも不可能ではなかったが、時間と費用の観点から現実的ではなくなってきた。デジタルフォレンジック調査で、費用の大半を占めるのが人の目を通す作業であるドキュメントレビューであるため、網羅性を担保しながら効率的に行うための技術を活用する必要性が高くなってきている。
*1: 1ゼタバイト(ZB)は10^21バイト=10億テラバイト(TB)=1兆ギガバイト(GB)
*2:IDC; Seagate; Statista estimates 世界のデータ総量の推移 2010年~2025年
(https://jp.statista.com/statistics/1410854/worldwide-data-created)
ここ数年の流れとして、AIによる「機械学習」を活用したレビューが行われるようになっている。AIといっても、人間が何もせずにAIが自動的にデータの選別を行い、結果を出してくれるわけではない。「機械学習」の仕組みは、まず人間が少量のデータについてサンプリングでレビューを行い、「Hot」「Relevant」と判断したコーディング結果をAIに学習させ、類似のテキスト、内容、コンセプトを有するデータに高いスコアを付けることで、対象データのスコアによる優先順位付けを行う。そうすることで、人がレビューをする際に、順位が高い、すなわち関連性が高いものから行うことが可能になるというものである。
AIを活用するメリットとして、まず、調査の初期段階で事案に関連するデータを見つけることで、そこから得た情報をレビューと並行して行う調査対象者へのインタビューに活かすことができるという点がある。また、より早い段階において、案件の全体像や重要な事実を把握することで、調査設計を見直すこともできるようになる。さらに、AIの学習を反復させたうえで、一定のスコア以下のものをレビュー対象から除外する判断材料となる。一方で、AIを活用するうえで注意すべき点もある。AIのスコアリング精度は、AIに学習させるサンプルデータのコーディングの正確さに依存するということだ。このため、AIに学習させるためのサンプルレビューについては、事案の内容をよく理解している弁護士等の専門家が対応することが望ましいといえる。また、AIへの学習は一度だけではなく、数回繰り返し行いながら精度を高めていく必要があるという点だ。そういった注意点やスタート時点における多少の手間はあるものの、AIを活用することで、調査時間を大幅に削減し、それが費用の削減につながることになる。
もう一つの傾向として、レビュー対象となるデータについても大きな変化が起きている。テクノロジーの急速な進化、そしてCOVID-19の影響によるテレワーク増加に伴い、社内外のコミュニケーション方法が大きく変化した。従来は、メールがビジネスにおけるコミュニケーションの中心であったが、最近はビジネスコミュニケーションツール上のチャット機能を利用する、「コミュニケーションのチャット化」が進んでいる。これまでメールを介して行っていたコミュニケーションやデータの授受について、ビジネスコミュニケーションツール上で行われることが多く見受けられるようになった。不正を示唆するコミュニケーションもチャットを介して行われることも多くなっている。チャットデータのドキュメントレビューは、メッセージのやり取りが繰り返されるトークルームやトークグループごとに区切って行うことが通常で、トークルームやグループが何カ月も何年も続いており、そのやり取りが膨大な量になる場合は日付で区切るなど特有の対応が必要となる。
III. おわりに
以上、デジタルフォレンジックにおけるドキュメントレビューについて足元のトレンドとともに概説した。対話型AIが生成AIブームのきっかけとなったことは記憶に新しい。生成AIは、デジタルフォレンジック調査においても、前述の機械学習以上の効率化を図るソリューションになっていくことが考えられる。実際、偽造された文書や画像等の分析で生成AIは既に活用され始めている。生成AIを利用した不正行為を、生成AIが検知するということも、近い将来に出てくるであろう。今後の技術の進歩に注目していきたい。
※本文中の意見や見解に関わる部分は私見であることをお断りする。
執筆者
デロイト トーマツ ファイナンシャルアドバイザリー合同会社
フォレンジック&クライシスマネジメントサービス
金 栄美 (マネジャー)
(2024.9.11)
※上記の社名・役職・内容等は、掲載日時点のものとなります。
不正・危機対応に関するナレッジやレポートなど、ビジネスに役立つ情報を発信しています。
不正・危機対応の最新記事・サービス紹介は以下からお進みください。
>> フォレンジック&クライシスマネジメント:トップページ <<
プロフェッショナル

岡田 大輔/Daisuke Okada
デロイト トーマツ ファイナンシャルアドバイザリー マネージングディレクター
その他の記事

訴訟・調査に備えるデジタルフォレンジック
クライシスマネジメントメールマガジン 第76号
有事におけるデジタルフォレンジック調査の初動対応と発生し得る問題
クライシスマネジメントメールマガジン 第60号