MLSecOps responsibilities span across multiple roles involved in the AI/ML development life cycle. As all ML begins with data, data engineers play an important role in ensuring security through data governance. In the first phase of the life cycle, data engineers validate the integrity of training data. This validation step is especially critical given training data is often pulled from open-source or third-party data providers.14 During the later inference phase, data engineers employ detection and classification techniques to identify potential adversarial inputs and protect model integrity. Data scientists build security into the models by design. As part of the development process, they employ privacy-enhancing techniques such as differential privacy, a mathematical method for ensuring individual data points cannot be extracted from a data set. The role of data scientists also extends into the inference phase as they examine model outputs to detect vulnerabilities. For example, a data scientist may examine a model explainability plot, or a visual representation of model performance, to better understand the model’s underlying mechanisms and thus potential security vulnerabilities regarding how it handles edge cases. ML engineers further secure the life cycle through use of encryption techniques to protect data integrity throughout as well as validating the security of software and hardware components used during both the training and inference phases. Business analysts also have a role to play by setting strong policies around data and model protection, ensuring sourcing hardware from preapproved manufacturers. Further, to minimize leakage of sensitive data and proprietary ML models, they monitor externally published information to protect against reconnaissance efforts intend on informing model attacks. Throughout the life cycle, analysts consider vulnerabilities within the process that could be addressed through technical or nontechnical solutions and apply risk-quantification and benchmarking practices.
Set security standards and bring in the specialists
As part of model governance, organizations should develop and maintain a counter–adversarial AI framework. Dependent on the type of ML systems and applications an organization uses, different levels of defense and privacy thresholds may be warranted. Organizations can start with an assessment of AI projects, identifying those that involve critical systems and data and base recommendations on quantitative evidence. Currently, much of the evidence available about AI threats is based on academic metrics that are not always relevant in actual operations. Organizations should invent ways to measure both the vulnerability and the potential impact of adversaries attacking real-world systems.
Chief security officers, chief data officers, and other C-suite executives focused on AI should be proactive to ensure their organizations are using leading technologies in a rapidly evolving field. This includes understanding and evaluating the ecosystem for adversarial AI solutions when budgeting for investments. Although a small portion of funding is going toward AI/ML security research and infrastructure development, many private companies, academia, and governments are developing and investing in solutions to combat adversarial AI attacks. Academia and big tech lead the way in maintaining open-source libraries as well as through the publication of threat databases.
For example, in academia, researchers at Johns Hopkins University developed a set of tools called TrojAI to help test the robustness of ML models and protect them from trojan attacks. These tools generate data sets and models with trojans to test ML models quickly and at scale.15 In MIT’s Computer Science and Artificial Intelligence Laboratory, researchers developed a tool called TextFooler that uses adversarial text to test robustness of natural language models.16 Other popular open source frameworks—such as the Adversarial Threat Landscape for AI Systems (ATLAS), developed by MITRE with support from Microsoft and a broad coalition of private sector companies—use real-world examples to catalog possible attacks and corresponding defenses across multiple industry verticals.17
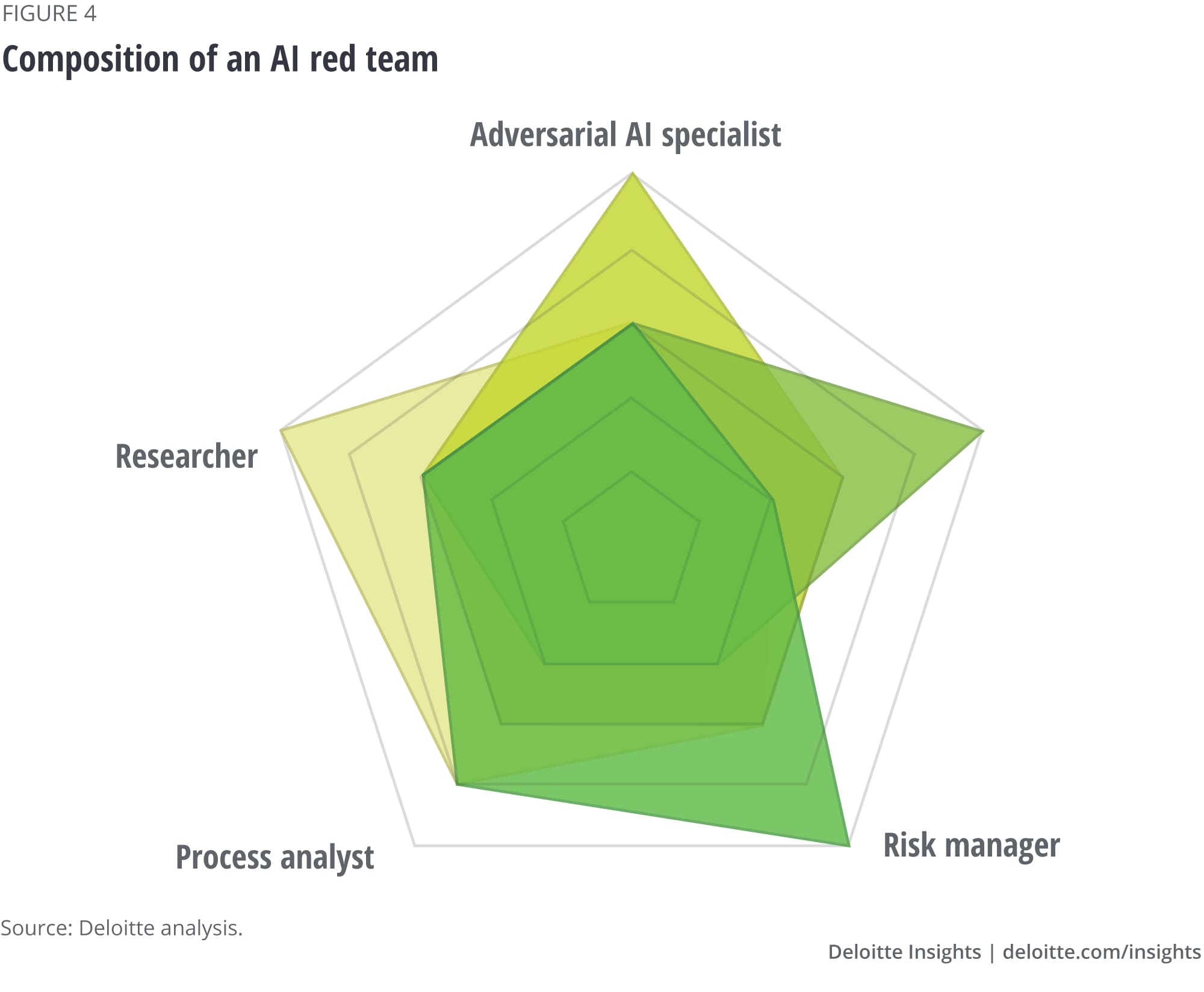
As the landscape of both adversarial attacks and defenses is rapidly evolving, organizations should invest in AI red teaming. Originating in the cybersecurity field, a "red team" (or "ethical hacker”) works to expose vulnerabilities with the objective of making a system stronger. These teams should operate independently to assure an objective review as a red team must be able to keep sensitive data secure, while being transparent about identifying risks. “Red teaming” is new to AI but can be traced back to stress testing exercises completed by the Department of Defense back in the 1960s largely for cybersecurity. Now, many large tech companies employ AI red teams to look for AI security vulnerabilities (figure 4).
The composition of a red team will depend on the needs of the organization. It may consist of software developers and data scientists or those more focused on human factors or insider threats. If an organization uses multiple models trained on datasets with the same distribution (often the case for large computer vision or language models), an adversarial AI specialist would be able to identify vulnerabilities to highly transferable attacks. However, with unique tabular data (rows and columns), launching a successful attack would require more brute force trial-and-error and would not require an expert.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}