
Effective Site Reliability Engineering (SRE) Requires an Observability Strategy | Deloitte US has been saved
A blog post by Paul Barnhill, managing director, Deloitte Consulting LLP; and Jay McDonald, managing director, Deloitte Consulting LLP
Site reliability is a growing concern in the marketplace. A key priority is to make sure you have a sound observability strategy, because observability empowers SREs and production resilience. Regardless of whether your IT infrastructure is hosted on-premises, in cloud, or hybrid, having a robust observability capability to provide a 360-degree view of your applications, databases, and infrastructure health is key to avoiding major issues and making informed decisions. Your SRE journey must include a sound observability road map.
Cloud migration is forcing enterprises to reevaluate their site reliability practices and investments. Reliability and resilience are more difficult in cloud, and many enterprises have realized that their lift-and-shift cloud migration tactics have hampered their ability to sustain—much less improve—their total availability metrics and performance objectives.
Trends that are forcing organizations to enhance their site reliability include:
- Increasing ‘always-on’ expectations—Digital giants have set a high bar. Customers (both internal and external) now expect the same fast, reliable, and smooth experience.
- Complexity being introduced at scale—Technology has always been a complex problem, even on-premises. The new challenge is manual interventions. Process control does not scale in a modern context that includes containers, multi-cloud, and microservices.
- Adverse effects of shift-left mindset—The shift-left culture has created a compounding effect on developers when production support is needed.
Why are monitoring and observability core to effective reliability and resilience engineering?
The traditional way of using software metrics and monitoring is not sufficient in today's computing environment. This approach is reactive; it may have served the industry well in the past, but modern systems demand a better method.
Observability tools were born out of sheer necessity when traditional tools and debugging methods could not identify what software did in production.
For a software application to have observability, you must measure how well the internal states of a system can be inferred from its external data and information outputs.
- Understand the system state of your applications, even new ones you have never seen before and couldn’t have predicted.
- Understand the inner workings and state of a system by observing and interrogating with external tools.
- Understand the internal state of a system without shipping any new custom code to handle it.
Three pillars of observability

Observability requires the collection and analysis of the following data from your software:
- Metrics
- Metrics are numeric representations of data measured over intervals of time.
- The main benefit of metrics is that they provide real-time insight into the state of resources.
- Traces
- A trace is a representation of a series of causally related distributed events that encode the end-to-end request flow through a distributed system.
- Distributed traces are used to isolate the root cause of an infrastructure or code problem.
- Logs
- An event log is an immutable, time-stamped record of discrete events that happened over time.
- Logs provide a comprehensive record of all events and errors that take place during the life cycle of software resources.
What does observability deliver for SRE?
Effective observability can help to identify some of these issues:
- Sudden spikes in concurrent users leading to long load time or other unexpected behavior that affects disk or CPU usage.
- Inefficient code, memory leaks, or synchronization issues and deadlock.
- Physical memory constraints or low-performing CPUs.
- Lack of a centralized location to automatically identify vulnerabilities across services, processes, and applications.
- Database performance not optimized due to over/underuse of indexes, leading to poor performance.
- Software settings not configured sufficiently to handle the workload.
- Third-party services used by the application impacting performance.
The building blocks of effective observability
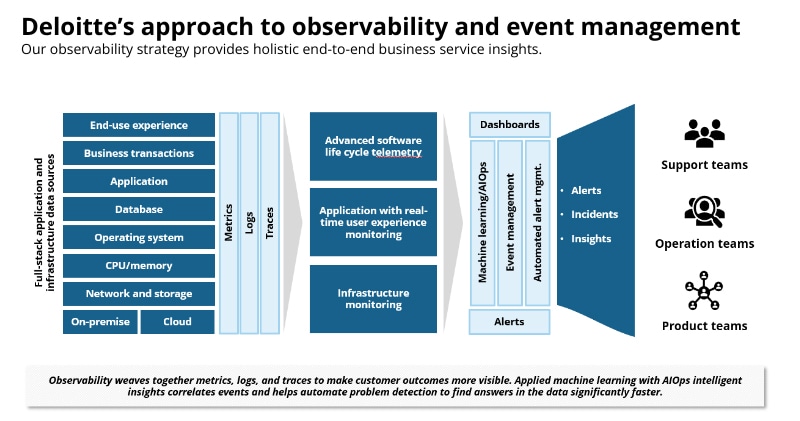
We see our clients making observability the starting point in their SRE journey. The essential components of effective observability include:
- Collecting and analyzing metrics, traces, and logs.
- Monitoring and instrumenting all network, infrastructure, and applications into a common observability system.
- Collecting and streaming all telemetry data into a distributed data store to leverage automated correlation techniques. This helps to reveal actionable events and reduce excess toil among the limited pool of responder teams.
- Some examples are:
- Data visualization combined with network topologies, providing dashboards to help engineers find the root cause.
- Real user monitoring and synthetic testing, providing insights into the user experience.
- Deploying and managing monitoring agents and instrumentation thresholds in a microservices and hybrid cloud environment.
- Leveraging AIOps to test a high volume of events and reduce alarm volumes across domains. This helps to identify anomalies and outlier events and detect critical issues proactively.
- Some examples are:
- Combining AI/ML with topology, user experience metrics, network, systems, applications, and database alarms to find probable cause events by applying statistical techniques, such as graph analysis, random forest, and decision trees.
- ML-focused performance monitoring to track baselines and establish dynamic performance management metrics.
- Using ML to identify specific device and application behaviors from the norm or baseline performance indicators with the help of trend analysis, pattern recognition, and clustering statistical methods.
- Using automation to respond to production issues, improve incident management, and reduce risk from outages.
- Building playbooks for repeatable tasks, technical troubleshooting actions, tasks from lessons learned, and organization-specific processes. These should be accessible so that they can be immediately used during an incident. Playbooks should contain minimal manual intervention tasks and should be parameterized for wider usage.
- Some examples are:
- Monitoring the console logging actions in a production environment and triggering playbooks to restart a server instance.
- Monitoring untagged resources for cloud sprawl and automatically running the playbook when a service exceeds the allowed threshold. This will notify stakeholders and temporarily restrict permissions to create new resources.
Practicing observability and SRE together improves reliability. Your observability system can expose what is happening with software running in the environment and inform your SREs they are improving overall service level objectives.
Get in touch

David Linthicum
Managing Director | Chief Cloud Strategy Officer
As the chief cloud strategy officer for Deloitte Consulting LLP, David is responsible for building innovative technologies that help clients operate more efficiently while delivering strategies that enable them to disrupt their markets. David is widely respected as a visionary in cloud computing—he was recently named the number one cloud influencer in a report by Apollo Research. For more than 20 years, he has inspired corporations and start-ups to innovate and use resources more productively. As the author of more than 13 books and 5,000 articles, David’s thought leadership has appeared in InfoWorld, Wall Street Journal, Forbes, NPR, Gigaom, and Lynda.com. Prior to joining Deloitte, David served as senior vice president at Cloud Technology Partners, where he grew the practice into a major force in the cloud computing market. Previously, he led Blue Mountain Labs, helping organizations find value in cloud and other emerging technologies. He is a graduate of George Mason University.