
Artykuł
O naukowcach od danych słów kilka, czyli czym tak naprawdę zajmuje się Data Science?
Rola Data Science w organizacji
Marzec 2021
Data Science w organizacji nie służy do tego, aby poszukiwać jednorazowych odpowiedzi na postawione pytania, ale raczej po to, by w sposób ciągły wspierać procesy biznesowe. Nic więc dziwnego, że coraz więcej firm buduje ten obszar u siebie bądź też postrzega go, jako kluczowy element w toku swojej transformacji cyfrowej.
Stwierdzenie „dane są nowym paliwem XXI wieku” pojawia się coraz częściej na ustach wielu niczym słynne „jesteś na mute” z 2020 roku. Analogia danych i paliwa jest jak najbardziej zasadna, nawet na kilku płaszczyznach. Oprócz oczywistego aspektu napędzającego wiele rzeczy, paliwo ma również tę cechę, że wlane do niewłaściwego pojazdu nie pozwoli nam ujechać daleko, a czasem wręcz nie ruszymy z miejsca. Całkiem podobnie bywa z danymi. Zyskująca ostatnio coraz większą popularność branża Data Science jest z pewnością jedną z tych, która pomoże to paliwo zatankować w odpowiednich miejscach organizacji, bardzo często tworząc przy okazji nowatorskie, wysokooktanowe jego mieszanki. Tylko, co to właściwie oznacza mieć Data Science w organizacji? Kogo potrzebujemy zatrudnić i za co nasi Data Scientists pobierać będą niemałe przecież wynagrodzenia? A może tak naprawdę mamy już u siebie taką funkcję, ale na przykład działa ona pod inną nazwą (życie i takie zna przypadki). Z odpowiedzią na te i wiele innych pytań wokół Data Science spieszymy w niniejszym tekście, wyjaśniając przy okazji kilka kluczowych pojęć powiązanych, które niczym grzyby po deszczu wyrastają w każdej dyskusji o tej tematyce.
Implementując odpowiednie narzędzia i mechanizmy pozyskujemy i przechowujemy coraz większe ilości danych w naszej organizacji. Dane same w sobie zazwyczaj niewiele znaczą i aby niosły ze sobą jakąś wartość, trzeba przekształcić je kolejno w informacje, a następnie w wiedzę. Informacje uzyskujemy poprzez łączenie ze sobą i agregowanie poszczególnych źródeł oraz nadanie im semantyki w postaci chociażby różnych słowników biznesowych. Do tego z pomocą przychodzą nam Inżynierowie Danych (ang. Data Engineers), którzy zajmują się tworzeniem i automatyzacją tego typu przetwarzań, wspierani przez Analityków Danych (ang. Data Analysts), którzy pomagają odpowiednie źródła zidentyfikować oraz zinterpretować. Tak przygotowane dane i informacje trafiają następnie do hurtowni danych lub do przeróżnych środowisk raportowych i analitycznych, gdzie czekają już rzesze chętnych, pragnących wydobywać z nich wiedzę.

Najbardziej podstawowym i dobrze wszystkim znanym sposobem wydobywania wiedzy z danych jest raportowanie. Jak wiemy, raportowanie polega na dalszym agregowaniu danych na wyższe poziomy oraz wyliczaniu pewnych wskaźników, statystyk, czy jakkolwiek tych miar nie nazwiemy. W tradycyjnym raportowaniu struktury, do których dążymy są wcześniej zdefiniowane i przedstawiane w raporcie w ten sam sposób za każdym razem, odpowiadając konkretnej potrzebie biznesowej. Od pewnego czasu, wraz z rozwojem odpowiednich narzędzi, coraz bardziej popularny i preferowany przez organizacje staje się nowocześniejszy i bardziej przystępny sposób raportowania, czyli tzw. BI (ang. Business Intelligence). Narzędzia klasy BI dają możliwość dystrybucji raportów oraz prezentacji wyników w postaci uruchamianych w przeglądarce internetowej interaktywnych dashboardów, zamiast uciążliwego rozsyłania poprzez email dziesiątek plików XLS i PPT. Bardziej rozbudowane dashboardy dają też użytkownikom możliwość ich modyfikacji, filtrowania i nakładania na siebie różnych wymiarów danych w celu nieco pogłębionej ich eksploracji. Wspólną cechą obu tych podejść jest jednak fakt, że aby stworzyć raport zarówno tradycyjny, jak i interaktywny klasy BI, musimy z góry wiedzieć, do czego dążymy z punktu widzenia potrzebnej wiedzy, przestawianych miar, a często wręcz również układu graficznego.
Rys 1. Przykłady interaktywnych dashboardów BI w technologii Tableau
Czy zawsze musimy jednak wiedzieć, czego od danych oczekujemy? Co w przypadku, kiedy dysponujemy dużą ilością informacji płynących z danych, które gromadzimy już od dawna i po prostu chcielibyśmy je jakoś wykorzystać adresując konkretne problemy biznesowe? Tak oto, po lekko być może przydługim wstępie, docieramy wreszcie do miejsca, w którym wkracza Data Science, wraz z całą swoją magią.
Praca Data Scientista polega głównie na przecieraniu szlaków podczas przeprawy przez nieprzebrane ilości danych, w poszukiwaniu właściwej, choć nie zawsze jedynej możliwej drogi do celu. Do rozpoczęcia działania Data Scientist potrzebuje właśnie tego celu, stawianego zazwyczaj ze strony biznesowej oraz dużo, dużo danych. Im więcej, tym lepiej. Po przeanalizowaniu potrzeby biznesowej, zwykle to Data Scientist poszukuje dostępnych źródeł danych, mogących mieć zastosowanie w danym przypadku. Nie zawsze są to dane przetworzone i poukładane już w informacje. Często spojrzeć trzeba również w nowe obszary, których nikt jeszcze wcześniej nie eksplorował.
Po zidentyfikowaniu i zrozumieniu dostępnych źródeł, przychodzi czas na dobór metod. Tych Data Scientist musi posiadać bardzo szeroki wachlarz, ponieważ problemy przed nim stawiane mogą być bardzo różnej natury. Innych metod użyjemy na przykład do prognozowania ryzyka odejścia klienta lub prawdopodobieństwa, że kupi od nas określony produkt, czy spłaci zobowiązanie finansowe, a inne zastosujemy poszukując wzorców w bazie naszych klientów tak, aby wyodrębnić wśród nich podobne grupy, którym proponować będziemy lepiej dopasowane produkty, uwzględniające ich potrzeby, czy styl życia. Na jeszcze innych metodach będziemy się opierać analizując dane z czujników IoT (ang. Internet-of-Things) tak, aby w porę wykonywać przeglądy i naprawy maszyn produkcyjnych, zanim ulegną one awarii. Odpowiednio wybrana metoda posłuży do budowy modelu dostarczającego nam potrzebnej wiedzy do realizacji postawionego celu biznesowego. W zależności od specyfiki problemu, czasem interesować nas będzie sam wynik przeliczeń modelu, na przykład prognoza zapotrzebowania na dany produkt w pewnym regionie, a czasem więcej odpowiedzi przyniesie nam sama postać modelu, z której możemy wnioskować na przykład o tym, jakie konkretnie czynniki wpływają na zwiększenie ryzyka odejścia klienta.
Większość metod wykorzystywanych w Data Science ma podłoże statystyczne, co pozwala przenosić nam modele i wnioski zbudowane na pewnej podgrupie obserwacji (np. podgrupie klientów), na całą populację (np. klientów, którzy dopiero dołączą do nas w przyszłości). W zależności od stopnia skomplikowania problemu, z pomocą przychodzą algorytmy o różnej złożoności. Do tworzenia segmentacji klientów czy dopasowania kampanii marketingowych, wykorzystamy podstawowe techniki Data Mining. W trudniejszych przypadkach (jak chociażby przy modelowaniu zachowań klientów) z pomocą przychodzą algorytmy uczenia maszynowego (ang. Machine Learning), które pozwalają opisywać modelowane zjawisko setkami, a nawet tysiącami różnych cech i wyłapywać bardzo skomplikowane zależności. Wreszcie, gdy przyjdzie nam analizować obrazy, czy też ludzką mowę, sięgniemy po techniki tzw. uczenia głębokiego (ang. Deep Learning), nazywane też często ową słynną sztuczną inteligencją (ang. Artificial Intelligence – AI) ze względu na to, że w pewnym sensie pozwalają one naśladować kognitywne zdolności ludzkie oraz samodzielnie uczyć się na popełnianych błędach. Nie zawsze jednak najbardziej skomplikowany model będzie najlepszym rozwiązaniem. Ogólna zależność jest taka, że im bardziej skomplikowany model budujemy, tym bardziej nastawiamy się na jego wynik, ponieważ sama interpretowalność jego postaci staje się trudna, a często wręcz niemożliwa dla człowieka.

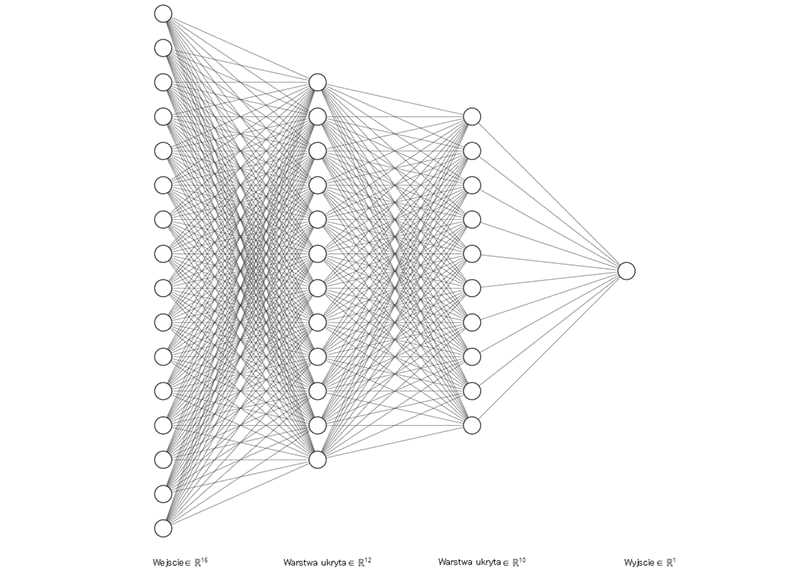
Rys 2. Przykładowy schemat złożonego modelu ML – sieci neuronowej
Często pojawia się jeszcze kwestia prezentacji pierwszych lub pośrednich wyników. Doświadczenie pokazuje, że wielu Data Scientists źle znosi robienie slajdów w Power Point, a same slajdy równie źle znoszą to połączenie. Na szczęście każdy Data Scientist dysponuje zazwyczaj zestawem technik i narzędzi do wielowymiarowej wizualizacji danych, która z powodzeniem zastąpi tradycyjne wykresy w dokumentach i pozwoli lepiej zrozumieć prezentowane rezultaty.
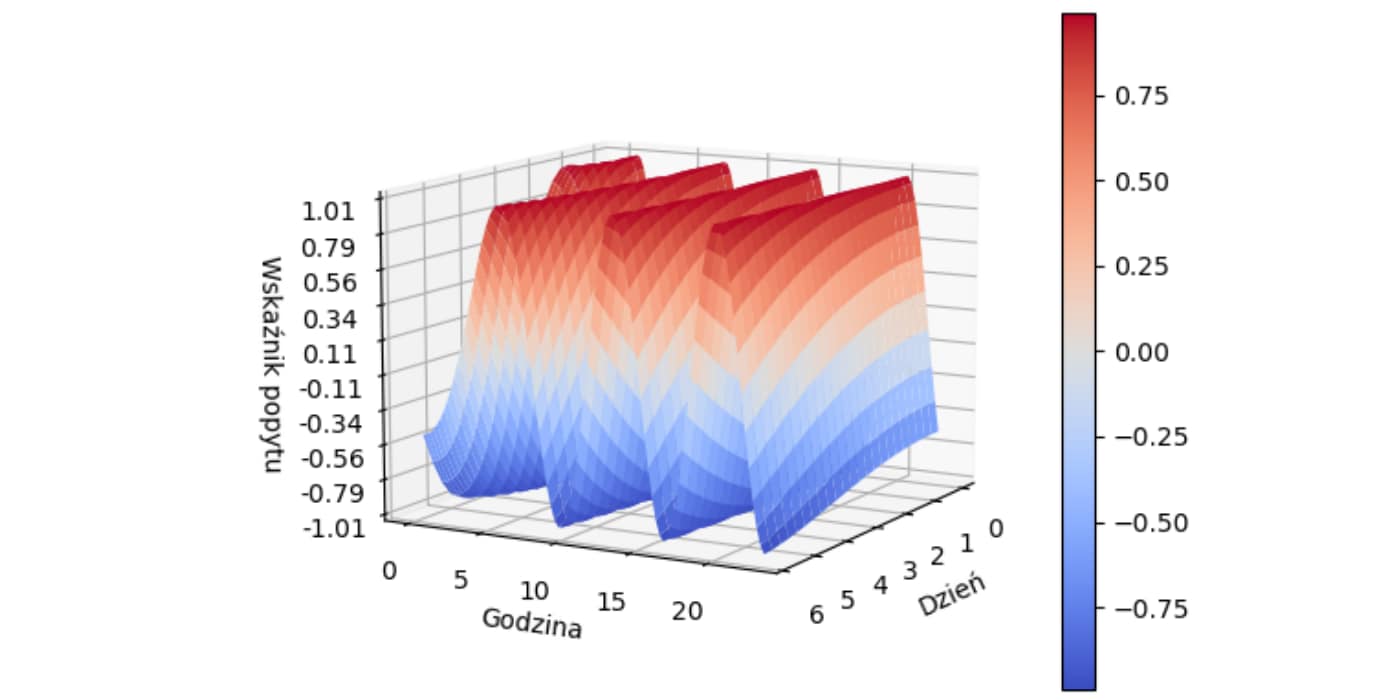
Rys 3. Przykład wizualizacji funkcji wielowymiarowej na potrzeby prezentacji zależności
Jak widać, jest wiele kwestii, które Data Scientist musi samodzielnie rozstrzygać i realizować na każdym etapie budowy rozwiązania. Do tego dochodzi znajomość technologii do przetwarzania danych i budowania modeli. Nie należy zapominać również o bardzo pomocnej intuicji biznesowej lub przynajmniej umiejętności rozmawiania z biznesem w poszukiwaniu tych intuicji, ponieważ nawet najlepszy algorytm zadziała zawsze skuteczniej we współpracy z człowiekiem.
Data Science w organizacji nie służy do tego, aby poszukiwać jednorazowych odpowiedzi na postawione pytania, ale raczej po to, by w sposób ciągły wspierać procesy biznesowe. Oczywiście w procesie budowy modelu bardzo często zdarza się, że dostajemy dodatkowe wnioski niejako „gratis” bądź też udaje się potwierdzić lub obalić pewne wcześniejsze hipotezy. Przede wszystkim jednak chodzi nam o to, aby ów owoc pracy, czyli zazwyczaj pewien model, włączyć w tzw. „cykl produkcyjny”, czyli obudować go w taki sposób, aby samodzielnie był w stanie pobierać i przekształcać potrzebne dane oraz dostarczać wyniki do odpowiednich osób lub systemów. W zależności od struktury organizacyjnej, cyklem produkcyjnym modeli może zajmować się Data Scientist lub też dedykowany do tego celu inżynier uczenia maszynowego (ang. Machine Learning Engineer). W pełni zautomatyzowany model może dostarczać wyników, gdy zostanie o to poproszony, bądź też cyklicznie: co miesiąc, co godzinę, a nawet w ułamku sekundy.
Każdy taki produkcyjnie działający model będzie się jednak z czasem starzał i wymagane będzie cykliczne odświeżenie jego parametrów (przeważnie raz na kilka miesięcy, tygodni a w wyjątkowych wypadkach minut). Nominalnie czynność ta należy również do Data Scientista, natomiast są już na rynku dostępne rozwiązania, które pozwalają automatyzować także ten element cyklu życia modelu. Jak już wcześniej wspominaliśmy, istnieją też pewne rodzaje modeli, które potrafią same uczyć się na swoich błędach.

Jak widać, Data Science to nie tylko chwilowa moda, czy kilka dobrze brzmiących haseł, ale realne wsparcie dla biznesu, realizujące wszechstronne tematy i pomagające efektywnie skonsumować potencjał płynący z gromadzonego w organizacji „paliwa XXI wieku”. Nic więc dziwnego, że coraz więcej firm buduje ten obszar u siebie bądź też postrzega go, jako kluczowy element w toku swojej transformacji cyfrowej. Wiele firm posiada już w swojej strukturze całe dobrze funkcjonujące działy Data Science, inne decydują się budować mniejsze, lokalne funkcje, dedykowane do wsparcia konkretnych obszarów biznesu. Modele organizacyjne mogą być oczywiście różne i zależą ściśle od specyfiki firmy.
Należy jednak pamiętać, że zatrudnienie kilku zdolnych Data Scientists zazwyczaj nie wystarcza do osiągnięcia sukcesu. Oprócz talentów konieczne jest też między innymi: właściwe dostosowanie struktury organizacyjnej, wypracowanie kultury współpracy z biznesem, dostarczenie odpowiednich narzędzi oraz osadzenie funkcji we właściwym miejscu cyklu zarządzania danymi w organizacji (ang. Data Governance). To wszystko nie jest proste. Dlatego też wiele firm decyduje się na wsparcie konsultantów zewnętrznych, którzy mogą pomóc w zaplanowaniu, stworzeniu i osadzeniu funkcji Data Science w organizacji, czy też realizacji pierwszych projektów, które później zostają przekazane zespołowi wewnętrznemu. Coraz bardziej popularny staje się również model subskrypcyjny (ang. Software-as-a-service), w którym kupowane jest od firmy zewnętrznej gotowe rozwiązanie, które zwyczajnie otrzymuje ustalone dane i zwraca żądany wynik, a płatność za usługę jest naliczania wedle jej faktycznego wykorzystania. W przypadku, gdy potrzebujemy niewielu, ale za to bardzo konkretnych lub złożonych rozwiązań, taki model staje się znacznie bardziej efektywny kosztowo i pozwala szybciej osiągnąć pożądany cel biznesowy.
Ogromna i wciąż rosnąca popularność tematyki Data Science jest jak najbardziej uzasadniona. Nikt nie zadaje już sobie pytań „czy?”, ale raczej „kiedy?” i „w jaki sposób?” uda się zmaksymalizować potencjał drzemiący w danych organizacji. Jest to bez wątpienia obecnie kluczowy element budowania przewagi konkurencyjnej na rynku. Zdecydowanie warto więc inwestować w obszar Data Science w organizacji i dobrze zaplanować sobie model jego rozwoju, dzięki czemu będzie on mieć znacznie większą wartość, niż tylko wizerunkową.
Kontakt:


