AIを諸刃の剣としないために知っておくべき敵対的事例とその対策 ブックマークが追加されました

ナレッジ
AIを諸刃の剣としないために知っておくべき敵対的事例とその対策
AIの敵対的事例の例と、攻撃手法・防御手法の概要を知る
1 はじめに
AIの利活用により、社会や企業活動へもたらされる便益が計り知れないことに疑いの余地はありませんが、AI固有のリスクも存在します[1]。この記事では敵対的事例と呼ばれるリスクについて、技術的な側面から概観します。AIへの悪意ある攻撃に用いられる敵対的事例に関して、攻撃手法とそれに対する防御手法について解説します。各技術の詳細は今後の記事で解説予定です。
2 敵対的事例とは
AI固有のリスクの1つに敵対的事例(Adversarial Examples)[2]と呼ばれるAIの精度劣化を目的とした悪意ある摂動(微小な加工)を加えた入力データの作成があります。例えば、パンダの画像に対して、微小ではあるが意図して作成された摂動を加えると、人間にはパンダに見えるがAIはテナガザルと分類してしまう画像を作り出すことができます(図1)。実際にAIが活用される場面を想定した例では、自動運転に必要な技術の一つである画像認識技術において敵対的事例を悪用することで、AIが”Stop”の道路標識を”45km/h 制限”と誤認識する場合があると報告されています(図2)[3]。このような誤認識により自動運転車が停止すべき場所で加速してしまえば、重大な事故につながる恐れがあります。この自動運転技術における例は、AIが悪意ある攻撃により誤認識してしまう一例に過ぎません。AIの社会実装に向けて、私たちはAIを活用した全てのシステムやアプリケーションが同様の脅威を受けるおそれを認識する必要があります。日本の総務省情報通信政策研究所による「AI利活用ガイドライン」の取りまとめ[4]や、米国の国防高等研究計画局(DARPA)による「欺瞞に対するAIの堅牢性の保証プログラム」(Guaranteeing Artificial Intelligence Robustness against Deception, GARD)創設 [5]等からも分かる通り、AI固有のリスクの検討とその対応は重要性を増しています。
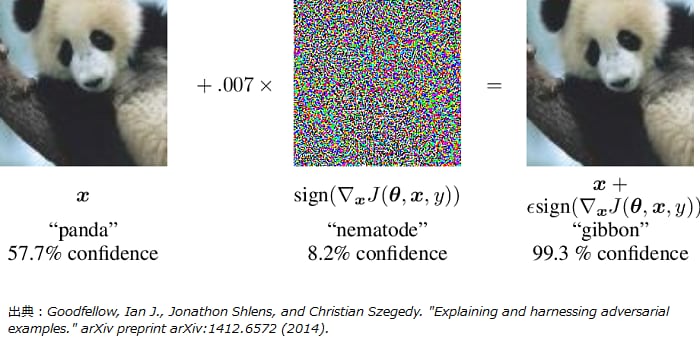
図1 (左)未加工の入力データで、AIは57.7%確信度でパンダと分類している。(中央)入力に加える摂動。(右)加工後のデータで、AIは99.3%の確信度でテナガザルと分類している[6]。
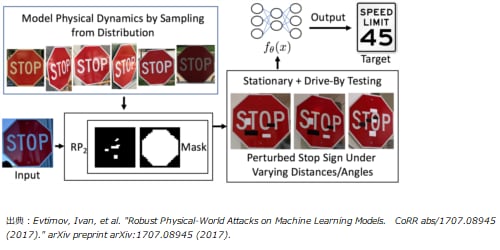
図2 ”Stop”の道路標識を”45km/h 制限”と誤認識させる加工処理の概念図[3]。
学術的な側面から見ても敵対的事例は大変興味深いものです。敵対的事例は「AIの錯視」と捉えることができます。人間にとっての錯視で有名なものの一つにミュラー・リヤー錯視があります。これは同じ長さの線分の両端を揃えて平行に描き、片方の線分の両端に内向きの矢印を付け、もう一方の線分の両端には外向きの矢印を付けると、内向きの矢印が付いた線分に比べて外向きの矢印が付いた線分は長く見えてしまう錯覚です。AIに入力するデータと悪意ある摂動を、それぞれミュラー・リヤー錯視における線分と矢印に置き換えて考えてみれば、敵対的事例を「AIの錯視」と捉えることは自然なことでしょう。未解明な部分が多い脳神経系の機構に迫る役割を錯視の研究が担うのと同様に、AIにとっての錯視である敵対的事例の深い理解はディープラーニング等の高度なアルゴリズムにおいてブラックボックスとして扱われている部分の解明に寄与することが期待されています。例えば、後述のAdversarial Trainingを用いるとAIが捉えた特徴がより人間の感覚に近くなり[7]、解釈性の向上に寄与することが期待されています。
3 敵対的攻撃
本節では敵対的事例を用いたAIに対する攻撃手法(敵対的攻撃)の概要を説明します。攻撃手法はホワイトボックス攻撃とブラックボックス攻撃に分けることができます。
■ホワイトボックス攻撃
攻撃者がAIの内部情報(アルゴリズム、パラメータ、学習データ等)を完全に知っている状況における攻撃です。攻撃に対する防御策を講じる上で最悪のシナリオを想定する場合や学術的な研究において重要になります。
■ブラックボックス攻撃
攻撃者がAIの内部情報の一部または全ての情報を知らない状況における攻撃です。例えば、AIのアルゴリズム等は不明だが、AIへの入力とそれに対するAIの予測ないしは判別の結果は得られる状況が該当します。ホワイトボックス攻撃に比べて、ブラックボックス攻撃はAIを活用したサービスに対して実際に起こる可能性が高い攻撃だと考えられます。
以下では研究が活発に行われている画像データの分類タスクにおいてWiyatnoら [8]の分類に倣い、主要な攻撃手法の概要を紹介します。典型的には画像データにおける敵対的事例の作成において加える摂動は人間に知覚できないよう、できる限り微小にすることが好ましいとされています。本記事執筆時点では、画像データの分類タスクにおいてディープラーニングが他の手法を圧倒しているため、以下で概観する手法の攻撃対象はディープラーニングにより作成されたモデル(ニューラルネットワーク)を想定します。
3.1 ホワイトボックス攻撃
3.1.1 制約付き最適化
制約付き最適化で主要な手法はSzededyらにより提唱されたL-BFGS[2]です。AIの学習は損失関数と呼ばれる関数を最小にするパラメータを探索することで行われます。損失関数はパンダの画像をAIに入力したとき、正しくパンダと分類した場合に小さな値を返し、誤ってテナガザルと分類した場合は大きな値を返すように設計されます。L-BFGSは学習によって固定されたパラメータをもつ損失関数に対し入力データに加える摂動を変えながら、入力データを任意のクラスに誤分類させることを目指します。すなわち、目的関数を損失関数(摂動が加えられた入力と誤分類させたいクラスを引数にもつ)とし、変数を加える摂動とした目的関数を最小化する最適化問題を解くことになります。ここで、摂動が大きくなるとペナルティが発生するように目的関数を工夫しておきます。また、画像データの階調は有限のため(例えば256階調)、摂動を加えた後のデータがその範囲内に収まっているように制約を課します。
3.1.2 勾配ベースの最適化
勾配ベースの最適化で主要な手法はGoodfellowらにより提唱されたFGSM(Fast Gradient Sign Method)[6]と呼ばれるものです。FGSMでは損失関数の入力データに対する勾配ベクトルを利用します。入力データの各成分について、対応する勾配ベクトルの成分の符号方向に摂動を加えて敵対的事例を作成します。この方法では、入力データがどのクラスに誤分類されるかは分かりませんが、L-BFGSに比べて計算コストが低く、高速に敵対的事例を作成することができます。
3.2 ブラックボックス攻撃
3.2.1 決定境界面近似
決定境界面近似で主要な手法はPapernotらにより提唱されたSubstitute Black-Box Attack[9]と呼ばれるものです。この手法は敵対的事例で非常に重要な概念であるTransferability(転移性)に関係しています。Transferabilityとは、「ある特定のAIを騙すことを目的に作成された敵対的事例は、他の同様のタスクを行うAIも騙すことができる」という性質のことです。いま決定境界面近似をしようとする攻撃者が攻撃対象となるAIから得られる情報は、入力データがどのクラスに分類されたかのみと仮定します。この場合に、攻撃者は攻撃対象のAIにデータを入力し、分類されたクラス(出力)を取得します。これを何回か繰り返すことで入力と出力のペアを用意し、攻撃対象となるAIの入出力関係を模したレプリカAIを作成します。レプリカAIに対してホワイトボックス攻撃を仕掛けることで敵対的事例を作成します。攻撃対象となるAIに大量のクエリを送信すると不正なアクセスとして検知される恐れがあるため、レプリカAIを作成するために必要なデータは工夫して用意する必要があります。
3.2.2 勾配近似
勾配近似で主要な手法であるZOO(Zeroth Order Optimization)[10]では、敵対的損失関数を定義し、近似的に計算されたその勾配を用いることで敵対的事例を作成します。ZOOにおいて攻撃の対象となるAIから得られる情報は、入力データが分類されるクラス毎の確率値と仮定します。敵対的損失関数は特定のクラスに誤分類させる場合(対象あり敵対的損失関数)とそうでない場合(対象なし敵対的損失関数)で定義が異なります。対象あり敵対的損失関数は誤分類させたいクラスの確信度(AIから出力される確率値を用いて定義される)が誤分類させたいクラス以外で最大の確信度よりも大きな値をとるときに最小値をとる関数として定義されます。対象なし敵対的損失関数も同様の考え方で定義することができます。近似的に計算された敵対的損失関数の入力に対する勾配を用いて、敵対的損失関数の値が最小になるように入力に摂動を加えることで敵対的事例を作成します。
3.2.3 進化アルゴリズム
One Pixel Attack[11]は進化アルゴリズムを活用した敵対的事例の作成方法です。今まで見てきた手法が画像全体に摂動を加えていたことと対照的に、画像の1ピクセル(または極めて少数のピクセル)に対してのみ摂動を加えることでAIに誤分類をさせることができます。One Pixel Attack を用いた攻撃の対象となるAIから得られる情報は、ZOOと同様に、入力データが分類されるクラス毎の確率値と仮定します。誤分類させたいクラスの確率値が最大になるように、どのピクセルに対してどの程度の摂動を加えるかを差分進化法で最適化します。
3.2.4 探査ベース
最後に生成モデルを活用したNNA(Natural Adversarial Attack)[12]と呼ばれる敵対的事例の作成方法を紹介します。ディープラーニングを用いた生成モデルはGAN(Generative Adversarial Network)がよく知られています。GANは潜在変数を複合化することで、画像などのデータを生成します。NNAでは敵対的攻撃に使用する入力データを潜在変数空間に写像するニューラルネットワークを用意し、潜在変数空間上で摂動を加えます。摂動が加えられた潜在変数をGANで複合化することで、敵対的事例が作成されます。
4 敵対的防御
本節では画像データの分類タスクに対する敵対的攻撃への防御手法を、前節と同様にWiyatnoら[8]の分類に倣い概要を紹介します。防御策としてAIの汎化性能の向上または敵対的事例の検知が有力であるとされています。残念ながら、現時点ではあらゆる攻撃に対して有効な防御手法は発見されていません。AIサービス提供者が敵対的攻撃への対策に投下するリソースに応じて、適宜防御策を講じる必要があります。
4.1 汎化性能の向上
敵対的防御の手法の一つ目はAdversarial Training[6]と呼ばれるものです。これはAIの学習データに敵対的事例を含めておく手法です。敵対的事例をどのように作るかによって防御能力は変化します。また、敵対的事例を含めて学習したAIは過学習する場合があるため注意が必要です。
4.2 敵対的事例の検知
防御手法のもう一つは入力が敵対的事例であるかどうかを判別するニューラルネットワーク(Adversary Detector Network, ADN)[13]を用意する方法です。ADNは攻撃対象のニューラルネットワークのある層からの出力を入力として、それが敵対的事例であるかを判別します。AIサービス提供者は攻撃者がADNも含めて攻撃を仕掛けてくる(ADNが敵対的事例だと判別できず、かつ画像分類器が誤分類してしまう)可能性があることに留意する必要があります。
5 終わりに
本記事では敵対的事例について直感的な理解に基づいて全体を俯瞰することを目的としました。今後は本記事で紹介した各トピックについてビジネス・テクノロジーの両面から詳細に解説するとともに、最新の動向についても紹介していく予定です。
■執筆者プロフィール
深澤 信也
有限責任監査法人トーマツ リスクアドバイザリー事業本部
デロイトアナリティクス
素粒子物理学において博士(理学)取得後、有限責任監査法人トーマツに入社。金融機関を中心に、データを活用した法人営業の効率化・高度化支援、機械学習を用いたマーケティング高度化支援等のコンサルティング業務に従事するとともに、機械学習・数理最適化・量子コンピュータといった分析技術の研究開発にも従事している。

[出典]
[1] AIの利活用とガバナンスに関する調査レポート https://www2.deloitte.com/jp/ja/pages/deloitte-analytics/articles/ai-governance-survey.htm
l[2] Szegedy, Christian, et al. "Intriguing properties of neural networks." arXiv preprint arXiv:1312.6199 (2013).
[3] Evtimov, Ivan, et al. "Robust Physical-World Attacks on Machine Learning Models. CoRR abs/1707.08945 (2017)." arXiv preprint arXiv:1707.08945 (2017).
[4] AIネットワーク社会推進会議 報告書2019の公表 https://www.soumu.go.jp/menu_news/s-news/01iicp01_02000081.html
[5] Defending Against Adversarial Artificial Intelligence https://www.darpa.mil/news-events/2019-02-06
[6] Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. "Explaining and harnessing adversarial examples." arXiv preprint arXiv:1412.6572 (2014).
[7] Tsipras, Dimitris, et al. "Robustness may be at odds with accuracy." arXiv preprint arXiv:1805.12152 (2018).
[8] Wiyatno, Rey Reza, et al. "Adversarial Examples in Modern Machine Learning: A Review." arXiv preprint arXiv:1911.05268 (2019).
[9] Papernot, Nicolas, et al. "Practical black-box attacks against deep learning systems using adversarial examples." arXiv preprint arXiv:1602.02697 1.2 (2016): 3.
[10] Chen, Pin-Yu, et al. "Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models." Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security. 2017.
[11] Su, J., D. V. Vargas, and K. Sakurai. "One pixel attack for fooling deep neural networks. CoRR abs/1710.08864 (2017)."
[12] Zhao, Zhengli, Dheeru Dua, and Sameer Singh. "Generating natural adversarial examples." arXiv preprint arXiv:1710.11342 (2017).
[13] Metzen, Jan Hendrik, et al. "On detecting adversarial perturbations." arXiv preprint arXiv:1702.04267 (2017).

サービス内容等に関するお問い合わせは、下記のお問い合わせフォームにて受付いたします。お気軽にお問い合わせください。

その他の記事

The Age of With
「人かAIか」の二者択一から、人とAIが協調する社会へ