RAGおよびマルチモーダルLLMの特徴と課題 ブックマークが追加されました
生成AIの活用は、企業の業務効率向上や新たなサービス提供に大きな可能性を秘めています。2023年より多くの企業が生成AIの導入に着手し、採用される主要な技術やその課題が明らかになってきました。本稿では、その最新の技術トレンドや、今後の活用が期待される技術をご紹介します。
国内企業における生成AI活用のトレンド
2022年11月にChatGPTが公開されたことを契機に、国内企業でも社内版チャットアプリの導入・開発が急速に広がりました。さらに、企業内の独自データを組み込んだ生成AIアプリケーションを導入する企業も出現し、現在もそのトレンドが続いています。
また、先進的な企業では、各種業務システムや顧客向けアプリケーションへの生成AIの組み込みや、特化型LLM(大規模言語モデル)の開発に取り組んでいます。
そのような過程で、多数の生成AI関連技術が登場していますが、今回は、その中でも企業での活用機会が多い主要技術について、その概要や課題、そしてその対策について紹介します。
RAG (Retrieval Augmented Generation)
LLMは事前に大量の情報を学習していますが、各企業が独自に保有している情報や最新の情報は学習していないため、そのような未学習の情報を補う技術としてRAG(Retrieval Augmented Generation)が幅広く採用されています。その代表的な実装方法は、以下の2ステップから構成されています。
- チャンク検索:自社独自の情報を含むドキュメントをチャンクと呼ばれる小さな単位に分割して検索エンジンに読み込ませ、ユーザからの質問に応じて必要なチャンクを検索する
- 回答生成:検索して得られたチャンクを、ユーザからの質問と一緒にLLMに読み込ませることで回答を生成する
RAGの実装自体は、OSSライブラリやクラウドベンダーが提供しているサンプルアプリを使用することで簡単に実現できますが、企業レベルで導入する際には問題が生じることがあります。
特に頻繁に発生するのが検索精度の問題で、社内の多くのドキュメントを検索エンジンに読み込ませた場合、ユーザからの質問の回答となる情報を含んでいるチャンクが検索できず、別のチャンクが誤って抽出されてしまうことがあります。
検索精度を改善するためには多くの手法が研究されていますが、絶対的な手法は確立されておらず、対象とするドキュメントの内容に応じて対応する必要があります。
デロイト トーマツでは、RAGにおける検索精度向上策として多くのノウハウを有しており、それを組み合わせながらお客様のシステム改善を行っています。効果が大きい手法の例としては以下のものがあります。
検索精度改善手法の例
- セマンティック検索:キーワード検索+ベクトル検索で取得したチャンクに対してセマンティックランカーで再度スコア付けを行い、上位のチャンクを採用する
- メタデータの付与:インデックス上に各チャンクの要約文や想定質問をセットする
- 階層的検索:直接チャンクを検索するのではなく、最初にドキュメントレベルで絞り込みをかける
- マルチモーダルRAG:文書中に画像やグラフ、チャート等が含まれる場合は、それらの視覚的情報も含めて検索可能とする
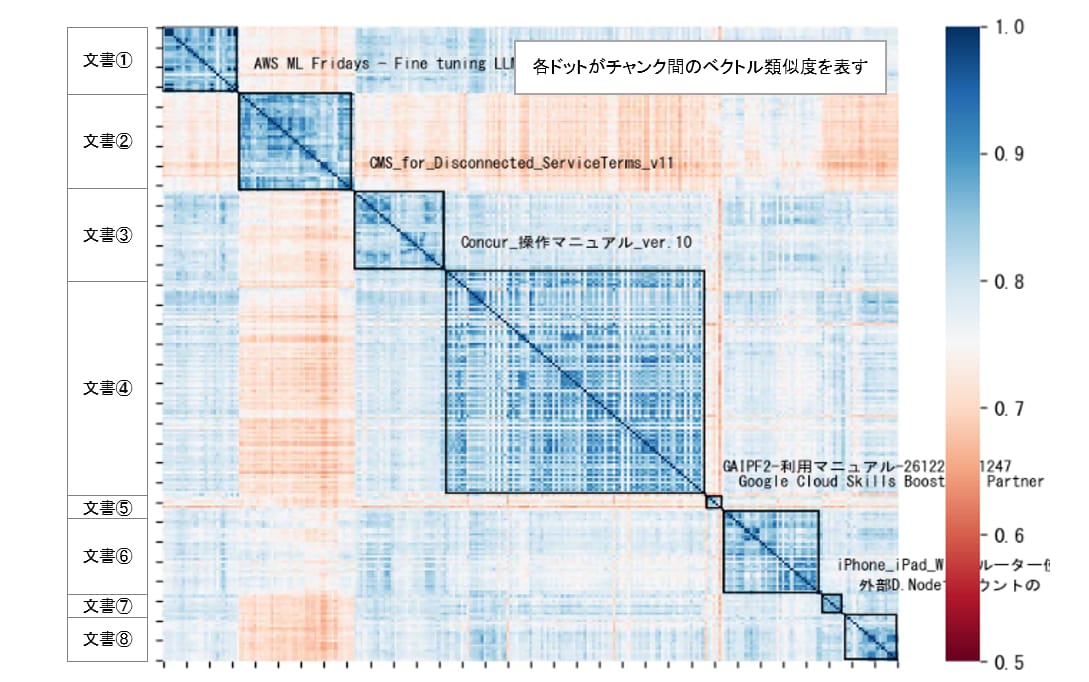
- ベクトル類似度の可視化:チャンク同士や文書同士のベクトル類似度を可視化し、類似状況に応じて対応を切り分ける
- ナレッジグラフRAG:取り込む情報の構造が明確な場合、文書中の情報をチャンクではなくグラフ構造データとして保持し、より厳密な検索を可能とする
マルチモーダルRAGイメージ
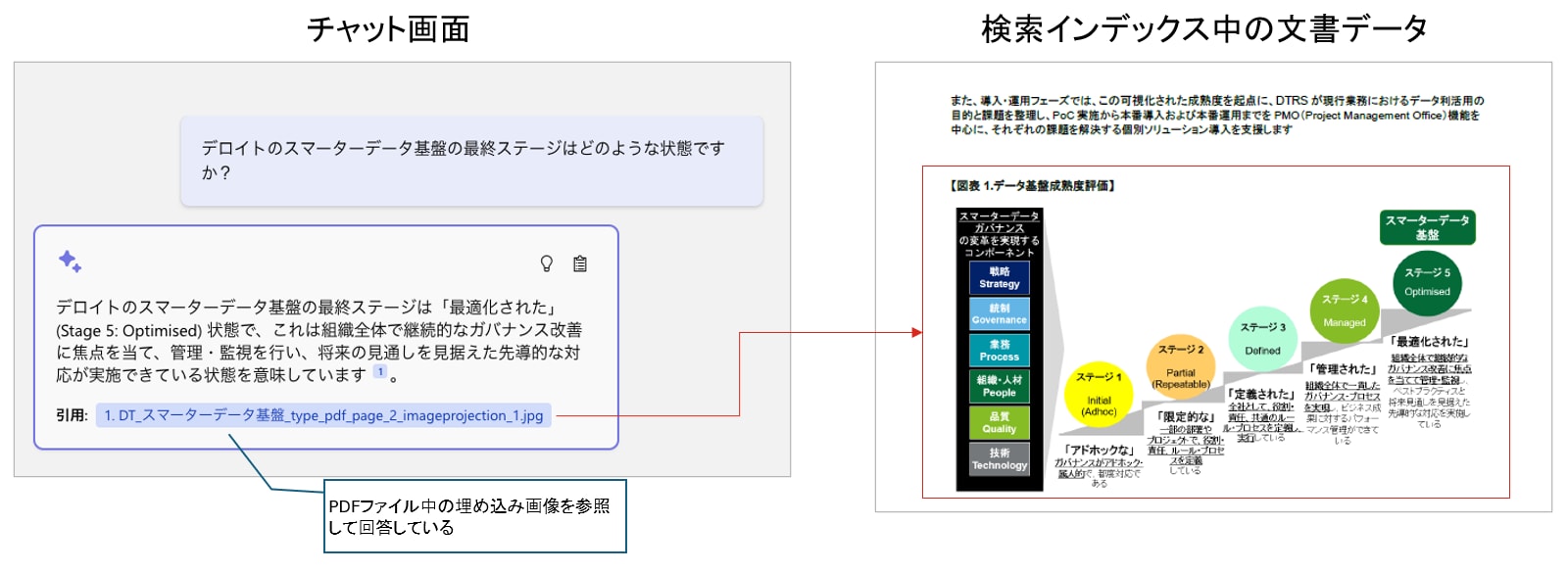
ベクトル類似度の可視化イメージ
マルチモーダルLLM
テキスト情報だけでなく、画像や音声も含めた複数の形式のデータを同時に扱うことができる「マルチモーダルLLM」の活用が広がっています。前述したマルチモーダルRAGもその活用方法の一つですが、LLMには幅広い知識が事前に学習されているため、一つのLLMで多様なタスクに対応することが可能です。
マルチモーダルLLMが対応可能なタスク例
- グラフやチャートの読み取り
- 構造物の亀裂、傾き、異常物の付着の検知
- パッケージやチラシのデザインの評価、誇大広告のチェック
- 製品のキズ、変色、組み立て不良の検知
- 不審者の侵入、災害発生の検知
マルチモーダルLLMの利用方法は、従来の画像認識AIと比較すると非常に容易で、プロンプトで指示文や画像を入力するだけで実装可能です。しかし、画像の認識精度は完璧ではなく、画像中のテキストが読み取れないケースや、読み取りたい物体の位置を正しく認識できないケース、何が正常で何が異常か判断できないケースなどがあります。
そういったケースに対して、精度改善の手法は様々ありますが、例えば以下のような手法が挙げられます。
画像認識精度の改善手法例
- OCRとの併用:OCRモデルにより画像中のテキストを抽出し、プロンプトに入力する
- 参考画像の入力:読み取りたい対象物の参考画像を入力する
- temperatureの調節:回答のランダム性を制御するパラメータ「temperature」の値を調整する
- 物体検知モデルとの併用:物体検知モデルを用いて認識したい物体の位置を特定する
以下では、今後の活用が期待される技術として、ロングコンテキストLLMとボイスボット・AIアバターを紹介します。
ロングコンテキストLLM
昨今では、従来のLLMよりもコンテキストサイズが大幅に拡大され、1Mトークンを扱うことが可能なLLMも登場しました。これは、1時間の動画や、文庫本10冊分のテキストに相当します。 このようなロングコンテキストLLMを活用することで、従来のLLMでは想定できなかった幅広いユースケースを実現できる可能性があります。例えば、以下のようなものが考えられます。
- 長期的な顧客コンタクト履歴に基づくNext Best Actionの提案
- 顧客対応の映像に基づく対応改善ポイントの提案
- 機器の不具合映像とマニュアル文書に基づく対処法の提案
- 過去の政策資料に基づく新たな政策案の提案
- 大量のプログラムの内容理解に基づくプログラム改修方法の提案
ただし、大量のデータを読み取る際のリードタイムやAPIコストが課題となるため、今後のユースケースの拡大には、推論時間の短縮やAPI料金の値下げが望まれます。
ボイスボット・AIアバター
現在、企業における生成AI活用の多くは社内向けのユースケースが大半を占めていますが、今後は、顧客対応への活用の広がりも期待されます。例えば、コンタクトセンターにおける音声での顧客対応や、Webサイトやアプリ上でのアバターによる顧客対応が考えられます。
このようなケースで特有の課題としては、ユースケースの目的に合わせて適切に会話を誘導するシナリオ制御や、顧客のイレギュラーな発話への対応、音声に合わせたアバターの動作の制御などがあります。これらは、一つひとつが難易度の高いテーマであり、また、互いに密接に関連しているため、専用フレームワークの活用が効果的です。
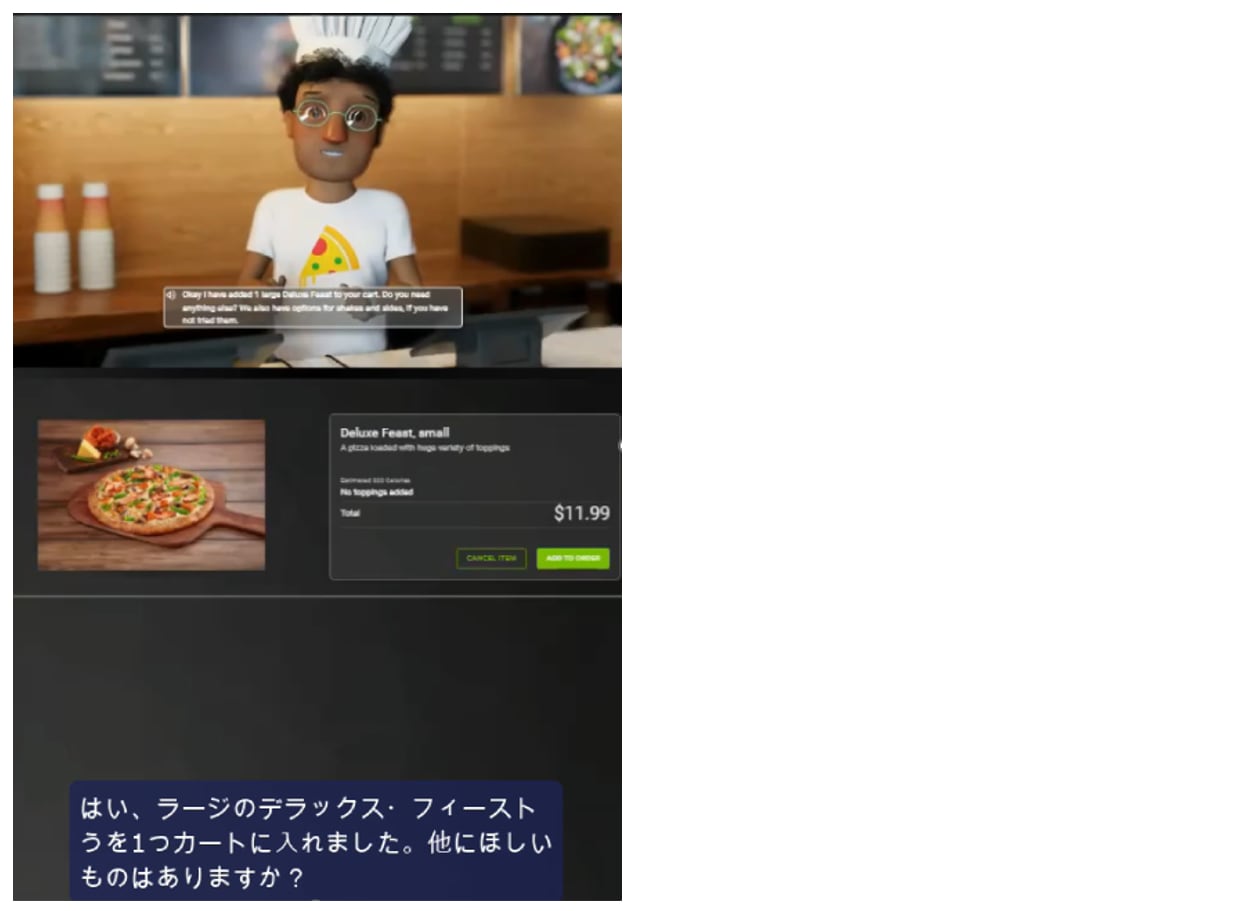
デロイト トーマツでは、音声やAIアバターによる顧客対応を実現するため、NVIDIAとのアライアンスのもと、Quartz Frontline AI™*というアプリケーションを開発し、パーソナライズされた顧客対応の自動化を実現しています。
Quartz Frontline AIを活用したAIアバターイメージ
上記以外にも、特化型LLMやマルチエージェント、小規模言語モデル(SLM)など、注目される技術は数多くあります。これらの技術により、今後はさらに複雑なビジネスプロセスへの応用や、新たな領域での活用が期待されます。
デロイト トーマツは常に最新技術を把握・研究し、ビジネスへの効果的な生成AI技術の適用を通じて、企業のデジタルトランスフォーメーションを加速させて参ります。
*Quartz Frontline AI™: 顧客の反応をダイナミックに認識、測定し、レスポンスを行う顧客エンゲージメントを高めるソリューションを提供します。ビジュアル化されたアバターによる会話機能を備えたFrontline AI™は、あらゆる言語でインテリジェントに会話し、顧客ロイヤルティを向上させるスムースな人間的体験を提供する、バーチャルのカスタマーサービス担当として働きます。
執筆者
松川 達也
デロイト トーマツ コンサルティング シニアマネジャー
航空系システム開発会社、BI専業コンサルティング会社、大手総合コンサルティングファームを経て現職。DX実現のためのAIシステム構築、データ分析、データマネジメント基盤の構築に関するコンサルティングサービスに強みを持つ。生成AI分野においては、デロイト トーマツ社内における生成AI タスクフォースにて技術検証チームをリードしつつ、多くの生成AI関連プロジェクトに従事している。
Recommended for you
Opens_in_a_new_window