顧客価値ベースのダイレクトマーケティング戦略 ブックマークが追加されました

ナレッジ
顧客価値ベースのダイレクトマーケティング戦略
CRM(顧客関係管理; Customer Relationship Management)で獲得した顧客により多く、より長期の購買を働きかけ、LTV(顧客生涯価値; Life Time Value)を高める上で、「購入確率の高い顧客層に対する集中的アプローチ」は効率的なビジネスを実現する。
本稿では、昔ながらのマーケティングツールとして認識されがちなダイレクトメールやカタログの効果を、アナリティクスによって最大化するためのアプローチについて論じる。
課題とアプローチ: ダイレクトマーケティングにおける基本的な考え方
メールやソーシャルメディアを活用したデジタルマーケティングが全盛を迎える一方、ダイレクトメール(以下,DMという)やカタログの郵送量は増加している[1]。ある調査によると、デジタル化に乗り遅れた世代だけでなく、ミレニアル世代も郵送のカタログに関心を示しており[2]、Amazon.com, Inc. のような効率的でデジタル化されたオンライン小売業者までが、いまやDMやカタログを印刷していると報告されている。昔ながらのアナログなマーケティングツールはデジタルマーケティングツールに取って代わられると考えられていた。しかし、小売業者あるいは保険代理店など、物理的な店舗を持たないビジネスを中心に、DMやカタログによるキャンペーンの活用による効果的な商品の提示について改めて検討が進んでいる。
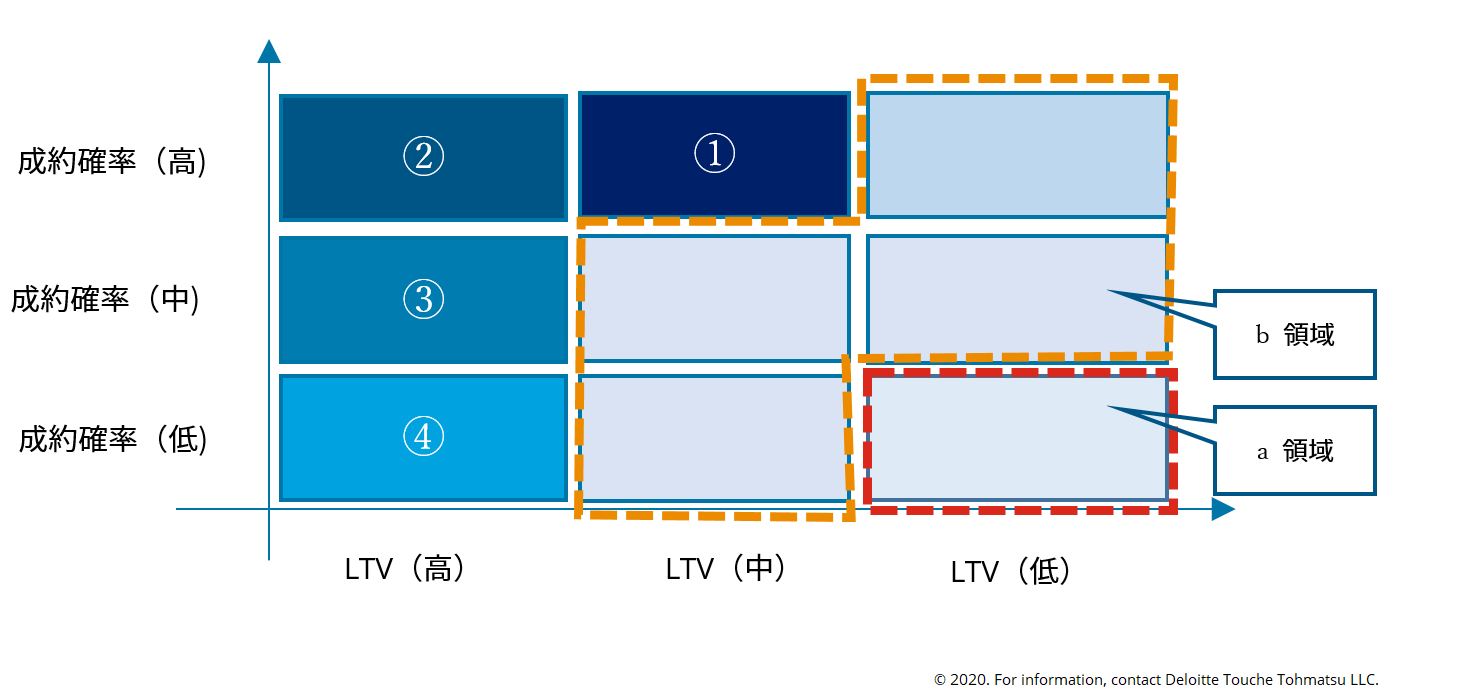
DMやカタログの効率的なビジネスを実現する上で、成約が見込める顧客かどうかを示す「成約確率」の順位付けは非常に重要である。「顧客価値ベースのダイレクトマーケティング戦略」においては [3]、LTVと成約確率がともに低レベルの顧客(図1 a領域参照)に対しては、ROI(費用対効果; Return on investment)が見込めない、あるいは、マイナスでさえあり得るため一般的にDM送付は行われない。同様に対象外となる領域として、LTVが比較的低い顧客 (図1 b領域参照)に対しても送付にかかる費用を正当化できないため、DMを送付しない判断がされる。
一般的にDMの送付は、LTVと成約確率のそれぞれが中〜高レベルの顧客がターゲットになる。最も重要視されるのは、図2 に示す①「生産性が最高レベルかつ、反応率が中程度の顧客層 」だが、② 「生産性,反応率ともに高水準の顧客」が最も優先されないことに注意が必要である。これは、①と比較してニーズが顕在化していることが多く、積極的なアプローチが必要ない傾向にあるからである。したがって②に続いて、③「中程度の生産性と高い反応率の顧客」が3番目の優先順位となる。④「生産性は低いが反応率が高い層」については、オファーなしでも取引してもらえることを想定し、DM送付をやめるかの判断が必要になる。
図1 顧客価値ベースのダイレクトマーケティング戦略
機械学習を用いた成約率予測モデルの構築
消費者の多様化と共に、顧客の行動や購買決定もより複雑なものになっている。これらを共通した単一のモデルで測ることは容易ではなく、複雑な因果関係を表現するモデル分析が必要とされる。近年、このニーズを満たすために機械学習が積極的に用いられており、複雑で膨大なデータから、1人ひとりのターゲットの行動を高精度で予測し、影響度が高い要素を的確に見つけ出すことが可能になった。顧客の過去の購買行動を探り、Emailやプッシュ通知を活用することで、顧客理解やクロスセルの促進といったマーケティング活動に寄与できることが期待されている。
以下では、マーケティング活動に資する成約率予測モデルについて、いくつか例を挙げて紹介する。
不均衡データの取り扱い
一般的に成約確率予測は、商品購入(成約)を示す正例が少ないことが特徴である。一般社団法人日本ダイレクトメール協会の調べによると、DMの成約率はおよそ1%から5%程度と報告されている[1]。つまり、例えば、正例1%・負例99%となるデータにおいて全て負例を予測するモデルは精度99%となる。そのため、機械学習モデルを構築するために正例・負例のデータ数比がバランスするようなデータで学習する「サンプリング」と呼ばれる手法を用いる[4]。特に、データ量の負例を減らす「ダウンサンプリング」を実施すると、本来は少数派クラスであった正例の割合が相対的に大きくなるため予測される正例の確率(事後確率)が大きくなる。そのため、予測確率の情報を用いた効果検証を行う場合には、ダウンサンプリングを行ったデータセットで学習されたモデルの予測確率に対してキャリブレーション(calibration)※1を行うことでバイアスの影響を除去する必要がある[5,6,7]。
※1:モデルの出力値を正解ラベル分布に近づける操作のこと
特徴量選択
XGBoost,LightGBMなどの勾配ブースティング決定木(Gradient boosting decision trees)系アルゴリズム[8,9,10]は近年人気が高い一方で、特にスパースなデータ※2を扱う場合に過学習を引き起こしやすくなる。そのため、特徴量選択には過学習しやすい特徴量の削除を目的として ”null importance” を用いた手法を採用することで回避できる[11]。これは、ターゲット変数をシャッフルしたデータセットを複数作成し、そのデータそれぞれに対して学習モデル(nullモデルと呼ぶ)を構築したときに、ある特徴量の実際のモデルによる重要度(actual importance)と複数のnull モデルから得られる特徴量重要度(null importance)の パーセンタイル値 (例えば =75)の対数比がある閾値以上(例えば0)になれば選択するという手法である。このように,変数を少なくすることで解釈性を上げると同時に、高次元データによって、パフォーマンスが下がることを防ぐことにもつながる。
※2:スパースとは「まばらな」を意味し、物事の本質的な特徴を決定づける要素はわずかであるというデータのこと
過去企画へのオーバーフィッティング回避
ここで一般的に、DMを発送する企画内容は毎回同様のものではなく、送付先の性質や件数が一定程度異なるため、単純にモデルを構築すると、過去における特定の企画にオーバーフィッティングしてしまう。その背景を踏まえ、顧客の成約確率を予測する機械学習モデルを構築する際のポイントについて示す。ここで注目する課題は、機械学習の学習データに存在するバイアス問題として扱われる。バイアスの問題は特に学習データが人口統計学的に偏っている場合に公平性の観点から顕著になる場合がある。例えば、与えられた文章がポジティブ、ネガティブ、中立的のどの意見を述べているかを分析するセンチメント分析においては、差別的または攻撃的な単語が含まれている文章であればすべてネガティブと判断するモデルは、バイアスを含んだ学習データにオーバーフィットしている可能性が高い。なぜなら、差別的な単語であっても辞書的な説明を与えている文章であればモデルは中立的と判断するのが自然だと考えられるからである。例えば、Borkanら[13]はSubgroup AUC等の工夫された評価指標導入によるバイアス問題の解決手法を提案している。意図しないバイアスを含んだ特定のグループ(具体的には過去企画等)にオーバーフィットしているとき、Subgroup AUC等の指標は悪くなるように設計されているため、これらの指標をモニタリングしながらモデルを構築することで,学習データのバイアスに対してロバストなモデル※3構築の達成が期待される。
※3:外れ値を取り除くとこなく受ける影響を小さくしたモデルのこと
施策の効率性検証: リフト率を指標に施策を検討する
機械学習モデルの予測結果を利用する際の重要な指標の一つに「リフト率」がある。これは英単語の”lift”、すなわち「持ち上げる」という単語由来であり、ランダムな顧客にプロモーション施策を行なった時の結果に比べて、結果がどの程度改善するかを示す概念である。
例えば、10万人に送付するとコストは1千万円(初期費用はゼロと仮定し、100円/通としてコストを算出)というDMがあるとする。その成約確率は現状1 %程度(= 1,000人)しかない。1件あたり1万円の粗利が期待される場合,1千万円程度の売上が得られる.これでは,単純に利益がないDMプロモーションとなる。そこで、このDMの送付先を成約確率2%の人だけ5万人とした時、コストは500万円削減され、500万円の利益が得られる。

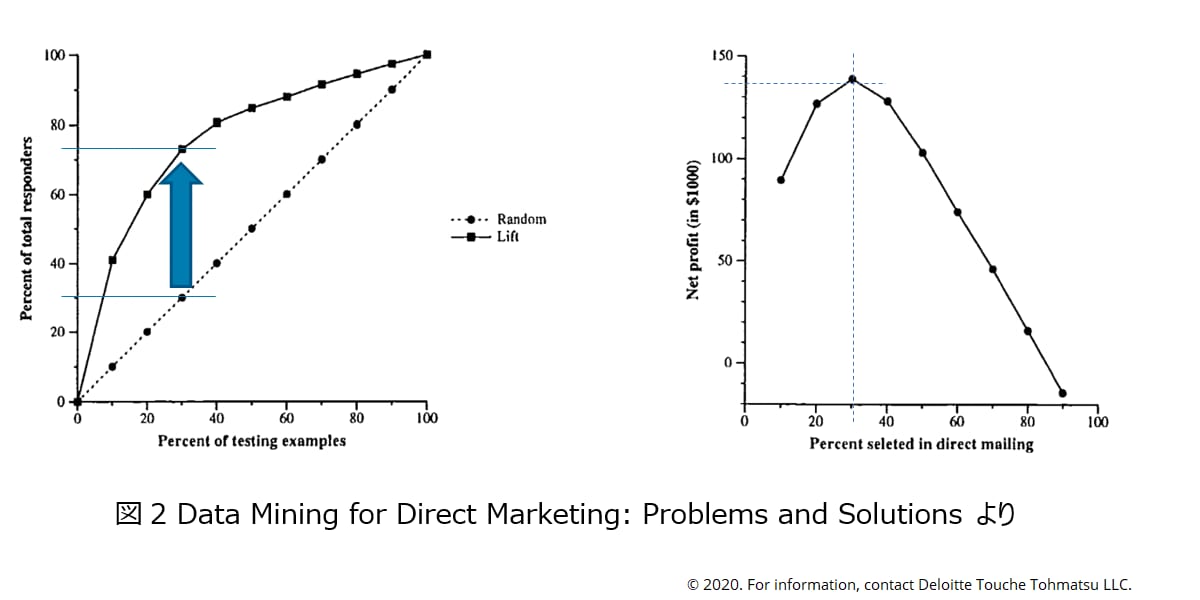
この例は、機械学習モデルを活用して購買確率の高い順に並べることができれば、購入確率の高い顧客層に集中的にアプローチすることで効率的なビジネスが実現できることを示している[12]。図2(左)はDMの配信数と購入数の関係を、「ランダムに送った場合」と「購入確率の高い順に送った場合」の効率性である「リフト」の概念を表したものである。顧客をランダムに並べ順番にDM を送ったとすると、送付数に比例して反応が得られる(図2(左)点線)。次に、顧客を期待成約確率の高い順に並べると図2(左)の実線のようなグラフになる(左側にいる顧客ほど成約確率が高く、右に行くほど成約確率が低い顧客)。もしこのように顧客を順位付けすることができたとすれば、全体の30%に配信するだけで70%超の反応が得られることがわかる。そして、この場合の利益をグラフにすると図2(右)のようになり、利益を最大化するには30%前後に絞ってDMを送ればよいということがわかる。
まとめ
スマートフォンをはじめとするモバイルの普及により、情報量が急激に増加した現在の社会において消費者のニーズは多様化しており、マスマーケティングのような均一なアプローチだけではマーケティング効果を得ることが難しくなっている。そこで重要になるのが、顧客1人ひとりに合わせてカスタマイズしたアプローチを展開するOne to Oneマーケティングである。One to Oneマーケティングの考え方自体は決して新しいものではないが、機械学習をはじめとするテクノロジーやアルゴリズムの発展とともに進化を遂げている。近年では膨大な顧客情報を統合管理・活用できるDMP(Data Management Platform)やマーケティング活動を自動化するマーケティングオートメーションツールが活発に提案されており、何万人、何百万人に対しても、顧客1人ひとりに応じたタイムリーでカスタマイズされたコミュニケーションが可能になってきている。
物流と製造のアウトソーシングの集約が進み、条件が均一化されつつ現在、もはや過去10年間とは異なり業務効率だけでは差別化要因になりえない。消費者に共感して感情的なつながりを喚起する能力があるかどうかが、デジタル化が進むほどに、決定的な競争優位性のひとつになるのではないだろうか。レガシーなチャネルであるDMやカタログ送付は、依然としてマーケティングコミュニケーションにおける強力な媒体になり得ると筆者は考えている。
[参考文献]
[1] 一般社団法人日本ダイレクトメール協会:「DMメディア実態調査2018」報告(要約版), available from <https://www.jdma.or.jp/upload/research/20-2019-000013.pdf>(accessed 2020-04-03)
[2] Jonathan Z. Zhang: “Why Catalogs Are Making a
Comeback”, Harvard Business Review, February 11, 2020, available from <https://hbr.org/2020/02/why-catalogs-are-making-a-comeback>(accessed
2020-04-03).
[3] Peter Doyle, “Value-based Marketing:
Marketing Strategies for Corporate Growth and Shareholder Value”, Wiley; 1版 (2000/12/1), ISBN-10:
0471877271, ISBN-13: 978-0471877271
[4] Nitesh V. Chawla,Kevin W. Bowyer,Lawrence O. Hall,W. Philip Kegelmeyer,“ SMOTE: Synthetic Minority Over-sampling Technique,”Journal of
Artificial Intelligence Research,Vol.16,pp. 321-357, (2002).
[5] B. Zadrozny & C. Elkan, “Obtaining
calibrated probability estimates from decision trees and naive Bayesian
classifiers”, Proceedings of the Eighteenth International Conference on Machine
Learning, (2001).
[6] Andrea Dal Pozzolo, Olivier Caelen,
Reid A. Johnson, Gianluca Bontempi, “Calibrating Probability with Undersampling for
Unbalanced Classification”, IEEE Symposium Series on Computational
Intelligence, (2015).
[7] Xinran He, Junfeng Pan, Ou Jin,
Tianbing Xu, “Practical Lessons from Predicting Clicks on Ads at Facebook”,
Proceedings of the Eighth International Workshop on Data Mining for Online
Advertising, (2014).
[8] Tianqi Chen, Carlos Guestrin, “XGBoost:
A Scalable Tree Boosting System”, the 22nd ACM SIGKDD International Conference,
(2016).
[9] Guolin Ke, Qi Meng, Thomas Finley,
Taifeng Wang, “LightGBM: A Highly Efficient Gradient Boosting Decision Tree”,
31st Conference on Neural Information Processing Systems, (2017).
[10] Liudmila Prokhorenkova, Gleb Gusev,
Aleksandr Vorobev, “CatBoost: unbiased boosting with categorical features”,
32nd Conference on Neural Information Processing Systems, (2018).
[11] Altmann A, Toloşi L, Sander O,
Lengauer T, “Permutation importance: a corrected feature importance measure”,
Bioinformatics, Volume 26, Issue 10, 15 May 2010, Pages 1340–1347.
[12] Charles X. Ling, Chenghui Li, “Data Mining for
Direct Marketing: Problems and Solutions”, Proceedings of the Fourth
International Conference on Knowledge Discovery and Data Mining, (1998).
[13] BORKAN, Daniel, et al. Nuanced metrics for
measuring unintended bias with real data for text classification. In: Companion
Proceedings of The 2019 World Wide Web Conference. 2019. p. 491-500.

サービス内容等に関するお問い合わせは、下記のお問い合わせフォームにて受付いたします。お気軽にお問い合わせください。

その他の記事

The Age of With
「人かAIか」の二者択一から、人とAIが協調する社会へ

AIを諸刃の剣としないために知っておくべき敵対的事例とその対策
AIの敵対的事例の例と、攻撃手法・防御手法の概要を知る