深層学習特許類似度マップの特徴と事例 ブックマークが追加されました

事例紹介
深層学習特許類似度マップの特徴と事例
AI x 特許情報分析
深層学習モデル及びデータ可視化手法を活用した新規アプローチにより、独自の探索的特許分析手法を開発
研究開発の背景
特許情報は多様な目的のために利用することのできる極めて有用なデータである。例えば、企業の場合には特許データを効果的に分析することで競合他社との差別化を図る事業戦略の策定や、自社の弱みを補完する買収・提携企業候補の選定を行うことができる。また、大学の場合には研究開発成果を事業化するためのパートナー企業の探索等にも役立てることができる。特に近年は技術領域間のボーダレス化が急速に進んでおり、こうした環境の中、膨大な特許情報に基づいて最新の技術動向を継続的に把握しておくことは様々な技術開発の主体にとって必要不可欠といえる。
一方で、特許出願は日本だけでも1年あたりおよそ30万件存在し、全世界では1年に300万件を超える出願が存在する(2018年時点)ため、自社関連技術領域のみに絞ったとしても、そのすべてに目を通すことは事実上不可能であるケースが多い。したがって通常の特許調査においては、キーワードやIPC等の特許分類によって絞り込みをかけた、いわゆる分析対象特許母集団を定義し、その集団の中で人間による特許文書読み込み作業を含む詳細な分析を実施する。しかし一般的には、調査対象とすべき特許を漏らさないことと、対象特許母集団の数を人間が読み込み可能なオーダーに抑えることの両立は困難である。
上記の問題を解決するためのアプローチの一つは、調査対象とすべき特許を漏れなく含むものの、関連性の薄い特許(ノイズに相当)も含む比較的広い母集団を定義しておき、その中で真に調査対象とすべき特許集団を探索的に特定していく、というものである。このアプローチを実践するにあたり、特許マップは有用なツールといえる。特許マップ(パテントマップ)は一般に、大量の特許情報を、調査目的に合致した観点から整理し可視化した一群のチャートのことをいい、特許庁による出願技術動向調査等でも活用されている1。中でも、特許情報の可視化手法の一つである特許類似度マップは、探索的に調査対象特許を特定していくという分析目的において特に有用である。特許類似度マップ上では通常、各発明がベクトルとして、発明間の類似度がベクトル間の距離として、それぞれ表現される。これにより、類似の技術が空間的に近距離に配置されるため、類似技術が密集したクラスタが形成されることが多く、その場合、調査対象とすべき技術に対応するクラスタをマップ上で特定することで、それ以外の特許をノイズとして除外することが可能になる。したがって、特許類似度マップの有用性を高め、調査効率を向上させるためには、1)マップ上で明確にクラスタを特定可能なこと、および2)マップ上での探索的分析を平易かつ直感的な操作で実施可能なこと、の2点が必要条件といえる。
本研究開発においては、以下で詳細を説明する通り、1)を新規に考案した特許請求項判別タスクおよび深層学習モデルを用いて、2)をBI(Business Intelligence)ツールを用いて、それぞれ実現した。
1 特許庁 特許出願技術動向調査
https://www.jpo.go.jp/resources/report/gidou-houkoku/tokkyo/index.html(外部サイト)
深層学習を利用した特許類似度マップ
特許類似度マップを作成するにあたっては、類似する発明が空間的に近距離に配置されるよう、個々の発明をベクトル表現化する必要がある。特許法上、発明間の類似性判断の根拠となる「特許発明の技術的範囲」は、原則として特許請求の範囲(請求項)に記載された文のみに基づいて定められる。したがって、ベクトル表現化の対象文書としては請求項を用いることが理想的である。
従来、特許文書のベクトル表現化には、単語(あるいはN-gram)の出現頻度をベースとするTF-IDF(Term Frequency-Inverse Document Frequency)法が広く用いられてきた。一方で、請求項の記載においては一般に、公知部分に相当する単語が繰り返し言及され、新規部分に相当する単語の登場頻度が相対的に少なくなるケースが多い。こうした場合、TF-IDF法では、各発明を真に特徴づける新規部分よりも公知部分のほうがベクトル表現に強く反映される結果になってしまう。また、請求項ではしばしば意図的に、単語の置換による上位概念または下位概念への言い換え(例、履物→サンダル)が行われるが、TF-IDF法は単語間類似度を考慮に入れることが難しいため、請求項間の類似関係が適切に評価されないケースがある。このような理由から、請求項文書を対象としてTF-IDF法による特許類似度マップを作成しても、マップ上で技術クラスタが特定されにくく、特に、比較的少数(1000件程度)の特許文献からなる分析対象母集団についてこの課題が顕著であった。
以上の課題を解決するため、我々は、新規の「類似請求項判別タスク」によって訓練した深層学習モデル(self-attended LSTMモデル)による請求項文書埋め込み手法を開発した。深層学習モデルのアーキテクチャおよび訓練の詳細については、本稿の趣旨を超えるものであるため、先行文献2を参照されたい。本アプローチにおいては、一の特許に含まれる複数の請求項が互いに類似のものと仮定し、これらを類似請求項データセットとしてモデルの訓練に使用した。これは、「特許出願が設定登録を受けるためには、当該出願に記載された発明を公知技術との対比において新規なものたらしめる技術的特徴(構成)部分が請求項間で共通していなければならない」、という特許法上の要件(発明の単一性要件)があるため、本質的構成が共通している同一特許中の複数請求項は互いに類似するものと考えられる、という理由に基づく。
上記のself-attention機能を備えた深層学習モデルを、同一特許由来の請求項ペアを用いて訓練することにより、モデルはペア間に共通する新規の技術的特徴に対してより強いattentionをかけ、請求項をベクトル化することが期待される。また、深層学習モデルへのインプットとなる単語は、大量の特許文書から訓練された単語埋め込みモデルによりベクトルに変換して使用するため、単語間類似度についても考慮に入れることが可能である。したがって、本アプローチにより、TF-IDF法による課題を解決することが可能である。
Cornell University, [1703.03130] A Structured Self-attentive Sentence Embedding, arxiv.org
https://arxiv.org/abs/1703.03130(外部サイト)
新規アプローチによる効果の検証
本研究による提案手法の効果を示すため、特許母集団データとして、日本国特許庁による公開公報、登録公報のいずれかに掲載された日本語特許出願の中で、1)家電メーカーAを出願人に含む2010年1月以降の出願約1200件、2)「電気自動車」という単語を発明の名称、要約もしくは請求項のいずれかに含む2010年1月以降の出願約5000件、のそれぞれを用いた実験結果を図1および図2に示す。いずれの実験結果からも、深層学習手法によるマップの方が、従来手法と比較して明確に技術クラスタを特定可能であることを、エントロピーを用いた定量評価(ΔHの絶対値が大きいほどより明確にクラスタが形成されていることを意味する)によって確認できた。
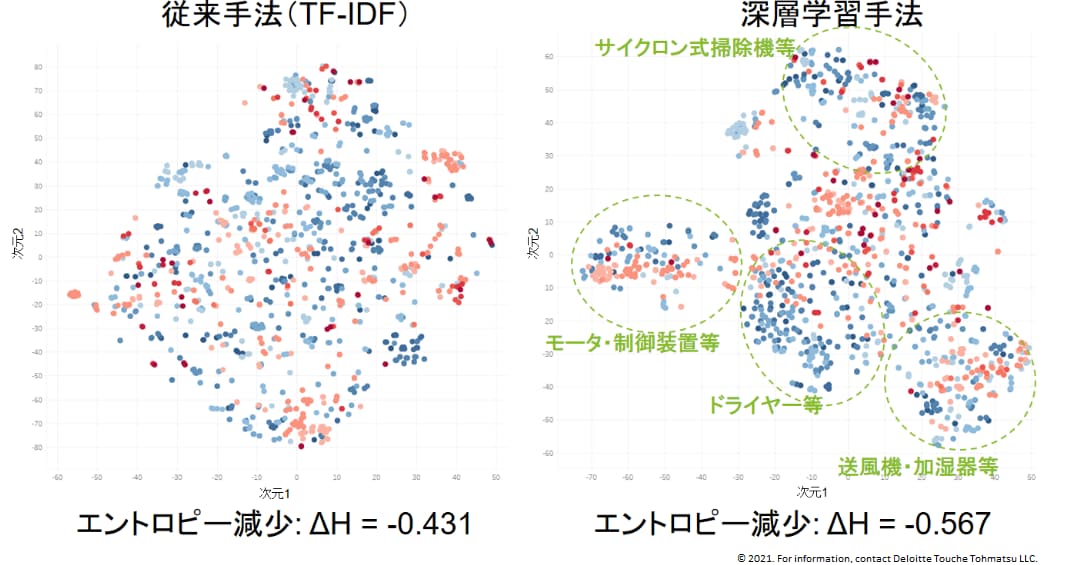
図1. 家電メーカーAの出願データ(約1200件)で作成した特許類似度マップの例。出願年を色で反映しており、古い出願が赤、新しい出願が青で示されている。クラスタ形成の程度の定量評価として、各マップと同じ領域に同じデータ数のランダムな分布を作成し、各マップ上のデータ分布についてのエントロピーの、ランダム分布エントロピーからの減少の程度を評価した。
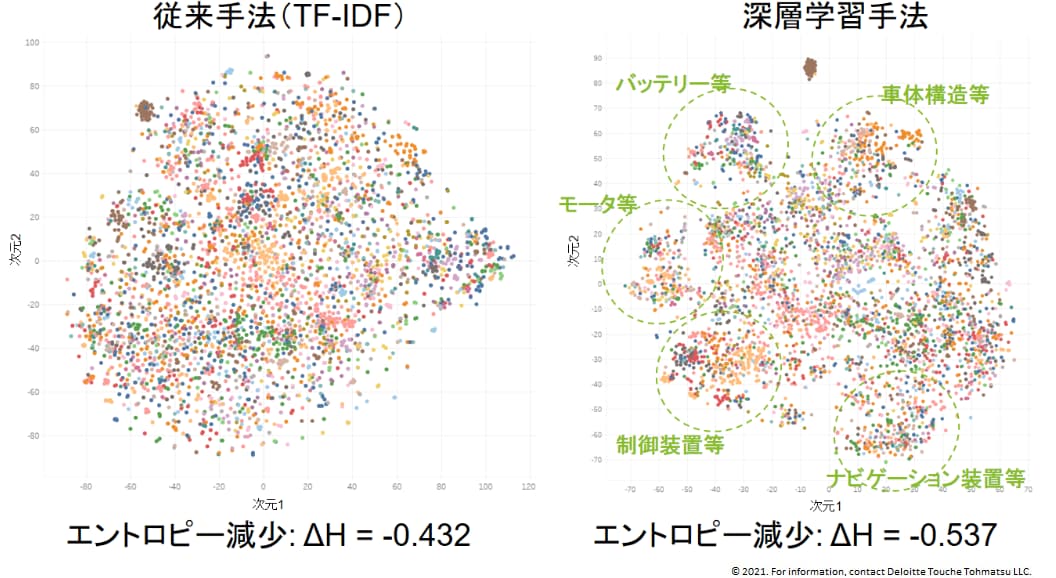
図2. 「電気自動車」に関連する出願データ(約5000件)で作成した特許類似度マップの例。出願人を色で反映している。図1と同様、クラスタ形成の程度の定量評価として、ランダム分布からのエントロピー減少幅を評価した。
BIツールを用いた特許類似度マップ上での探索的分析
BIツールとして、Tableau Software社が提供するTableau(デスクトップ版)を使用した。以下では例として、上記「電気自動車」に関する約5000件の出願からなる母集団を用いた結果を示す。ダッシュボード上では、提案手法によって2次元ベクトル表現化した特許出願群を容易にマップ化することができるうえ、マップ上の各点にカーソルを合わせると各出願の詳細情報(出願人、出願年、発明の名称、請求項など)をポップアップ画面上で閲覧することができる(図3)。さらに、投げ縄ツール等によってマップ上のクラスタを自由選択することで、請求項中の頻出ワードに関するワードクラウドや、頻出IPCおよびFタームに関するワードクラウドなどをそれぞれ閲覧することが可能である(図4)。これらの機能を活用することにより、マップ上で探索的にクラスタを特定することが可能であり、図4では例として「電気自動車の空調装置」に関連する技術クラスタを特定している。時系列的な情報や各出願の請求項数などの情報をマップ上に反映させることもできるため、多様な角度から探索的分析を実施することが可能であるといえる。

図3. BIツール上での情報可視化。各点(個々の出願)にカーソルを合わせることで詳細情報を閲覧することができる。
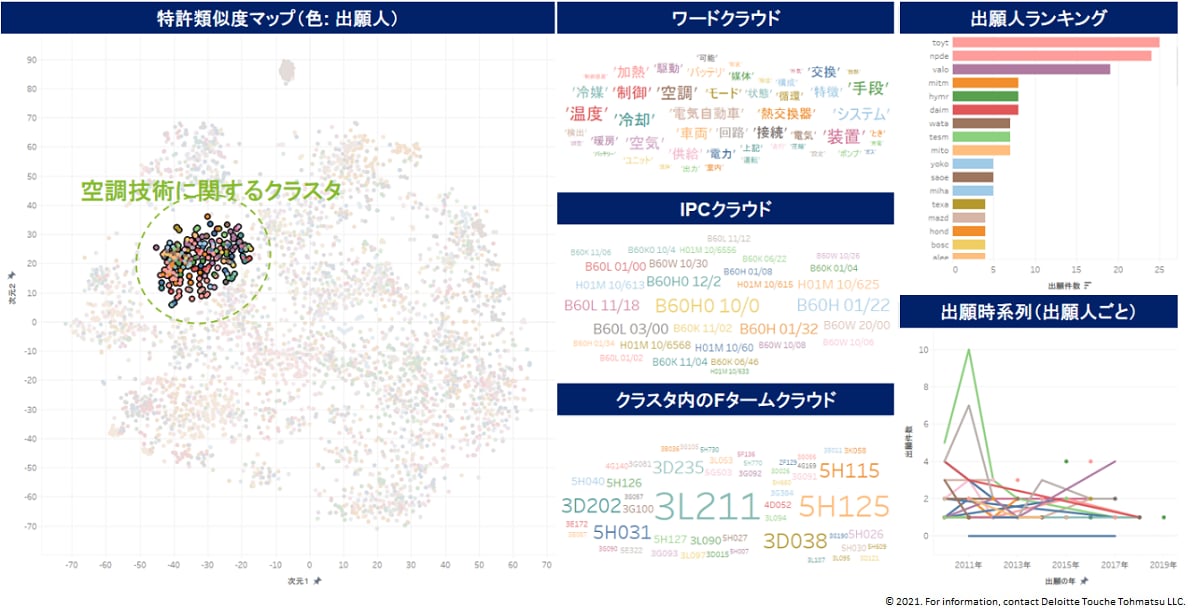
図4. 探索的な技術クラスタ分析の例として、「電気自動車の空調装置」に関するクラスタをマップ上で特定し、内包される特許の性質をワードクラウド等によって調べた。
本稿では、デロイトアナリティクスのR&Dが新規に考案した「類似請求項判別タスク」により訓練した深層学習モデルを用いることで、従来技術と比較して、クラスタをより明確に特定することが可能な特許類似度マップを構築することができることを示した。また、BIツールによる可視化手法を組み合わせることで、容易な操作で探索的にマップ上のクラスタを特定し、内包される特許の性質を調べることができることを示した。本アプローチは、特許データ、深層学習環境、およびBIツールさえあれば比較的簡便かつ安価に実施することが可能であるため、今後、IPランドスケープの実践等の場面において広く活用されていくことを期待したい。
サービス内容等に関するお問い合わせは、下記のお問い合わせフォームにて受付いたします。お気軽にお問い合わせください。

プロフェッショナル

神津 友武/Tomotake Kozu
デロイト トーマツ リスクアドバイザリー パートナー
その他の記事

知財学会で、デロイトアナリティクス神津が技術探索手法に関する研究発表を実施
深層学習特許類似度マップによる技術探索手法

Deloitte Analytics R&D(研究開発)の取り組み
AIに関連した先端技術の研究開発を行う