
Artykuł
Data Vault – najczęstsze wpadki
Cykl: Oswoić Data Vault | Publikacja #2
Jak mówi studencki dowcip: Teoria jest wtedy, kiedy wszystko wiemy, ale nic nie działa. Praktyka jest wtedy, kiedy wszystko działa, ale nikt nie wie, dlaczego.
„So true” - chciałoby się powiedzieć. Do głowy przychodzi mi scenka z budowy domu wiele lat temu – miały być wstawiane okna dachowe, co wtedy było dość nowym rozwiązaniem i kiedy spytałem majstra, dlaczego wyrzuca instrukcje montażu do śmieci nawet nie próbując ich czytać, ten na to (tłumacząc z „żargonu budowlańców”) – A co oni tam wiedzą? Głupoty piszą w tych instrukcjach!
Jak łatwo zgadnąć, bez poprawek się nie obeszło.
Tak więc o ile innowacyjność i ogólnie - robienie rzeczy po swojemu - nie raz przynosi nam korzyści, o tyle warto jednak najpierw zapoznać się z dobrymi praktykami i doświadczeniami innych w danej dziedzinie, a ponad wszystko - z zaleceniami producenta, który zna swój wyrób od podszewki. Nie inaczej jest w przypadku Data Vault.
Poniżej lista „popularnych” błędów, z którymi miałem okazję się spotkać, pomimo wyraźnych ostrzeżeń zawartych w „biblii” Data Vault (Building a Scalable Data Warehouse with Data Vault 2.0 – Dan Linstedt, Michael Olschimke).
Artykuł zawiera specjalistyczną terminologię, która w większości wyjaśniona jest w pierwszej części cyklu
Przejdź do pierwszej części cykluW Raw Data Vault nie powinno być żadnej logiki biznesowej. Pamiętajmy: Data Vault ma z definicji przyjmować zarówno dane „dobre” jak i „złe” czy „brzydkie”. Aby to umożliwić na wejściu nie może być absolutnie żadnej logiki biznesowej. W warstwie Raw Data Vault powinniśmy przyjmować praktycznie wszystko co przychodzi ze źródła i w takiej formie jak przychodzi. W zasadzie jedynym krokiem porządkującym dane wejściowe jest integracja kluczy biznesowych. Jeśli złamiemy tę zasadę i będziemy od razu ładować dane do Business Data Vault – czyli aplikując transformacje na wejściu – np. poprzez mapowanie wszystkiego na siłę do modelu logicznego naszej firmy – bardzo szybko wpadniemy w tarapaty. Jakakolwiek zmiana logiki biznesowej (a ta lubi się zmieniać!) spowoduje konieczność przebudowy i co gorsza – obsłużenia zmian w danych historycznych. O zwinności i skalowalności takiego rozwiązania… po prostu zapomnij.
Budując Raw Data Vault, prędzej czy później spotkamy się z kwestią braku dobrego klucza biznesowego. Istnieją pewne „encje”, które bardzo często niosą ze sobą ten problem. Sztandarowym przykładem jest Klient. Bardzo często jego dane przechowywane są w wielu systemach źródłowych, jakość i kompletność danych jest bardzo różna i zazwyczaj nie ma dobrego klucza identyfikującego osobę, co powoduje duplikaty nawet w ramach jednego systemu. W takich sytuacjach często nie ma wyboru – trzeba konstruować Huby w oparciu o klucze techniczne pochodzące ze źródeł. Data Vault posiada mechanizmy pozwalające na zarządzanie takimi danymi na wyższych warstwach – np. Same-As-Link (SAL), natomiast są to sytuacje wyjątkowe. Jeśli pozostawimy zarządzanie modelem naszym developerom istnieje duże ryzyko, że ulegną pokusie pójścia na łatwiznę i wszystkie Huby w naszym Raw Data Vault oprą o klucze techniczne, a to spowoduje bardzo szybkie „spuchnięcie” modelu i zbudowanie tzw. Source Vault – czyli niezarządzalnego śmietnika, który nie pokaże korzyści płynących z Data Vault – bo jedną z głównych jest integracja kluczy biznesowych!
Poniższy diagram ilustruje przykładowy model z czterema Hubami, w których używane są klucze biznesowe (po lewej stronie) vs. wersja oparta o klucze techniczne (Source Vault).
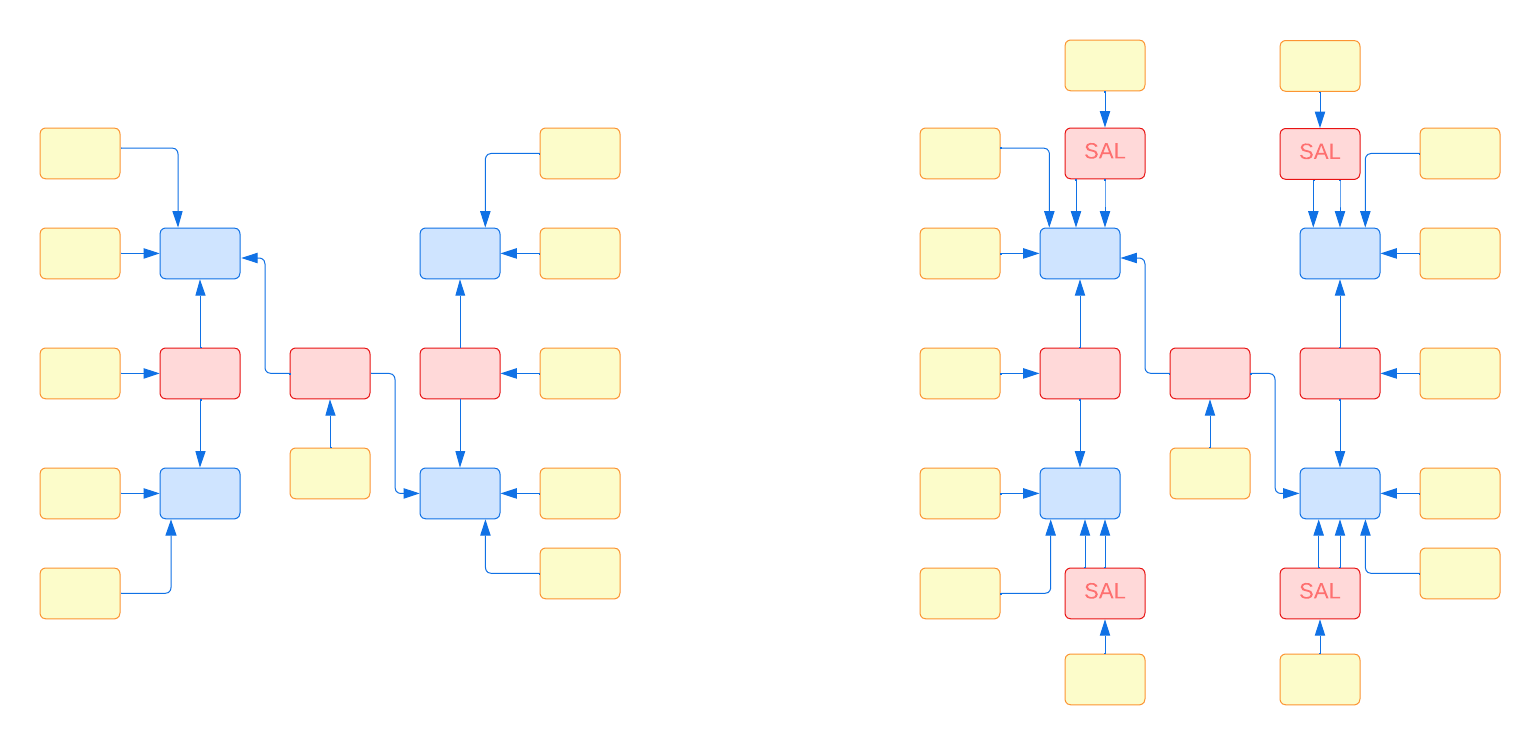
Zarządzanie kojarzy się z centralizacją, a ta z „wąskim gardłem”. Ale pewnymi rzeczami jednak trzeba zarządzać centralnie – moim zdaniem jedną z nich jest model. Jak pisałem wyżej – jeśli zostawimy to developerom, bardzo szybko zderzymy się z redundancją i łamaniem podstawowych zasad (w szczególności wspomnianym brakiem integracji kluczy biznesowych). Nie wszystkim trzeba zarządzać niskopoziomowo, ale warto określić sobie co jest dla nas kluczowe i co powinno być uzgodnione globalnie. Zachęcam do przemyślenia aspektów takich jak: klucze biznesowe vs. techniczne, zarządzanie danymi referencyjnymi, relacje między encjami, zarządzanie źródłami danych, wizualizacja modelu (to może banalne, ale uwierz mi – tutaj obraz jest naprawdę wart więcej niż tysiąc słów!)
Opcji jest wiele – darmowych i płatnych, ale bez tego na dłuższą metę nasza hurtownia się nie obroni! Data Vault szablonem stoi, a to prosi się o automatyzację – w niej bowiem tkwi pełen potencjał Data Vault. Pamiętajmy, że automatyzacja w pierwszej kolejności wymaga zdefiniowana zasad – wspomnianych szablonów. Musimy wiedzieć jakie typy obiektów chcemy tworzyć, ustalić dobre konwencje nazewnicze i ustalić jak będziemy zarządzać zmianami. Warto też ustalić co nie będzie podlegać automatyzacji – a taką rzeczą w szczególności jest wspomniana identyfikacja kluczy biznesowych!
Data Vault to nie tylko Huby, Linki i Satelity w ich podstawowej formie. Przy rosnącej liczbie źródeł danych, brakiem pełnej kontroli nad jakością tego, co ładujemy do hurtowni oraz rosnącymi wymaganiami do raportowania, nasz system bardzo szybko stanie się niewydolny, jeśli nie będziemy korzystać z opcji dla „nerdów”. Warto zawczasu pomyśleć o tym, jak obsłużymy dane niespójne (tu z pomocą przychodzą np. ghost records i zero keys), jak zoptymalizujemy zapytania łączące dane z wielu źródeł, lub odpytujące dane historyczne (hint: PIT & Bridge tables), czy jak wystawimy dane do konsumpcji. Nie łudźmy się: żaden normalny człowiek nie będzie w stanie pisać poprawnych zapytań do „czystego” modelu Data Vault!
Istnieją różne podejścia do próbowania nowych rzeczy. „Go big or go home”, mówią niektórzy. Brzmi fajnie, ale może sporo kosztować. Jeśli Data Vault jest czymś nowym dla Twojej organizacji, warto na początku trochę poeksperymentować. Kluczowe (i zazwyczaj nie tak łatwe, jak się wydaje) jest według mnie znalezienie dobrego „use case’u”, który będzie jednocześnie: mały i szybki do zaimplementowania, przydatny dla biznesu i pozwalający na przetestowanie jak największej liczby funkcjonalności Data Vault. Idealnie byłoby – zanim rozkręcimy duży projekt – wiedzieć jak będziemy zarządzać modelem, jak ustalimy klucze biznesowe, jak zautomatyzujemy wytwarzanie kodu, jak podejdziemy do danych referencyjnych i podstawowych, jak będziemy tworzyć Business Vault, jak będziemy optymalizować wydajność i wystawiać dane do konsumpcji. Jeśli te aspekty zaadresujemy dopiero na etapie „dużego projektu”, albo gorzej – odłożymy na przyszłość, a zajmiemy się od razu integrowaniem danych z naszych 20 źródeł, z kolei zarządzanie modelem zostawimy naszej armii developerów – nasz „big bang approach” może skończyć się (jak sama nazwa wskazuje) wielkim wybuchem… Czego nikomu nie życzę!
Kontakt:

Kontakt marketingowy:


