Artykuł

Jak to się dzieje, że usługi IT są dostępne?
Część I. Krótko o bezpieczeństwie fizycznym i środowiskowym
Architecture Hub | Blog o architekturze IT | maj 2022
W jednej z poprzednich odsłon naszego bloga architektonicznego opisywałem pułapki deklarowanych dostępności systemów, np. 99,9%, 99,99%. Tym razem chciałbym przybliżyć, w jaki sposób takie dostępności można uzyskać – a nie zawsze jest to proste i oczywiste. Dzisiaj skupię się na warstwie fizycznej, a kolejnym odcinku przedstawię metody zabezpieczenia warstwy logicznej.
Cytując Williama James’a, łańcuch jest tak mocny, jak jego najsłabsze ogniwo, a w kontekście systemów informatycznych, dostępność i integralność usług IT zależy od każdego pojedynczego komponentu na ścieżce dostarczania usług, który może ulec awarii, powodując utratę dostępności usługi (np. awaria serwera aplikacyjnego, na którym działa usługa, spowoduje niedostępność usługi) lub utratę integralności w wyniku utraty lub uszkodzenia danych (np. w wyniku awarii dysku, na którym dane były zapisane możliwa jest bezpowrotna utrata danych). Stąd w krytycznych rozwiązaniach biznesowych raczej zawsze stosuje się nadmiarowość komponentów, tzw. redundancję. Ogólnie rzecz biorąc, można przyjąć, że prawidłowo zaprojektowana architektura techniczna dla krytycznych usług biznesowych, nie zawiera tzw. pojedynczego punktu awarii (z angielskiego SPoF – Single Point of Failure). Oczywiście, nawiązując do mojego poprzedniego artykułu na naszym blogu, Analiza Wpływu na Biznes (ang. BIA – Business Impact Analysis) wskaże nam, czy dla naszej usługi (usług) rzeczywiście potrzebujemy architektury bez pojedynczego punktu awarii, ale roboczo można przyjąć, że zazwyczaj tak jest, jeżeli myślimy o usługach krytycznych dla biznesu.
Co to oznacza w praktyce, że system nie ma pojedynczego punktu awarii? Czy to oznacza, że jest całkowicie odporny na awarie? Niestety nie. Oznacza to jedynie, że dobrze zaprojektowana architektura techniczna przetrwa awarię pojedynczego komponentu technicznego. Weźmy na ten przykład samolot. Kluczowym elementem zapewniającym, że samolot utrzymuje się w powietrzu jest silnik. Awaria jednego silnika w samolocie jednosilnikowym, z dużą dozą prawdopodobieństwa zakończy się katastrofą. W samolocie dwusilnikowym, awaria pojedynczego silnika na pewno będzie stresująca dla załogi i pasażerów, ale jest bardzo duża szansa, że nie zakończy się katastrofą, a samolot doleci do najbliższego miejsca, gdzie może bezpiecznie wylądować.
Z usługami informatycznymi jest podobnie. Jeżeli usługa działa na pojedynczym serwerze, a ten serwer ulegnie awarii, to usługi na nim uruchomione przestaną działać. Jeżeli nastąpi nie tylko awaria, ale również zniszczenie serwera (np. przepięcie elektryczne, które przepali podzespoły), wówczas nie dość, że usługa przestanie działać, to dodatkowo możemy utracić cenne dane.
Zarówno w przypadku samolotu, jak i usługi informatycznej, ilość elementów niezbędnych do prawidłowego działania jest znacznie większa. W obu przypadkach rozwiązania projektuje się w sposób redukujący ilość pojedynczych punktów awarii. O projektowaniu samolotów wiem niewiele, ale w zamian spróbuję przybliżyć techniki poprawy dostępności usług IT poprzez eliminację pojedynczych punktów awarii.
Niewiele osób zastanawia się nad takimi pozornie banalnymi zagadnieniami, jak to jest, że różne usługi IT działają. Dlaczego możliwe jest nawiązanie połączenia telefonicznego ze smartfona? Jak to się dzieje, że z każdego miejsca i o każdej porze można skorzystać z facebooka, wyszukiwarki google, bankowości elektronicznej? Po prostu klikamy i korzystamy – w danej chwili nie tylko my, ale także miliony innych osób. Gdyby architektura techniczna tych usług nie została właściwie zaprojektowana, zapewne często występowałby problemy z dostępnością i szybkością działania tych usług, a w przypadku awarii, również z utratą danych.
W jaki sposób projektuje się architekturę usług IT w kontekście zapobiegania utraty dostępności i utraty danych. W praktyce, na początek, z biznesowego punktu widzenia, określa się oczekiwaną dostępność danej usługi IT, przez pryzmat konsekwencji jej niedostępności. Następnie identyfikuje się wszystkie składowe usługi, które mogą stanowić wąskie gardło lub pojedynczy punkt awarii - co może zawieść, ulec uszkodzeniu. Dla każdego elementu składowego analizuje się prawdopodobieństwo jego awarii (jakie jest ryzyko, że element zawiedzie) oraz wpływ tej awarii na usługę IT (konsekwencje – finansowe, biznesowe, prawne, itp.). Następnie wyznacza się składowe, które należy szczególnie chronić / zabezpieczyć. W dalszej kolejności analizuje się możliwe opcje ochrony, w tym koszt ich wdrożenia. Na koniec, na podstawie powyższych, podejmowana jest decyzja, które elementy należy dodatkowo zabezpieczyć i jakie środki ochrony należy zastosować. Wszystkie kroki opisywane powyżej określa się jako Analizę Wpływu na Biznes – BIA (ang. Business Impact Analysis).
Posłużmy się następującym przykładem. Firma planuje uruchomienie systemu dla klientów do składania zamówień przez Internet. Zakłada się, że zamówienia będzie można składać 24 godziny na dobę, 365 dni w roku. Do działania, projektowany system będzie potrzebować serwera z Windows oraz bazą MsSQL Server, połączenia z Internetem, publicznego adresu IP oraz domeny internetowej (DNS).
Spróbujmy prześledzić, jakie w tym przypadku będziemy mieli komponenty usługi i co potencjalnie może zawieść. Pierwszym z elementów jest serwer. Serwer może ulec uszkodzeniu jako całe urządzenie (np. spalić się), ale awarii mogą ulec również pojedyncze komponenty techniczne serwera – zasilacz, karta sieciowa, dysk(i). W serwerach dane rzadko są przechowywane na dyskach lokalnych – zazwyczaj na zewnętrznej macierzy dyskowej, która z jednej strony oferuje większą wydajność i dostępność, z drugiej strony jest kolejnym skomplikowanym elementem, w którym poszczególne komponenty mogą również ulec awarii (kontrolery dyskowe, dyski, karty sieciowe, zasilacze, itd.). Na działanie serwera może wpłynąć brak zasilania sieciowego, czemu można zapobiec przez zastosowanie urządzenia do podtrzymywania zasilania – UPS (ang. Uninterruptible Power Supply). UPS pozwoli podtrzymać zasilanie na kilka, maksymalnie kilkadziesiąt minut, po czym wyłączy siebie i podłączone do niego urządzenia. Żeby zapobiec utracie zasilania serwera, poza UPS-em można zastosować generator prądu.
Dla naszej usługi, poza serwerem, istotne jest zapewnienie komunikacji sieciowej. Jeżeli serwer jest wyposażony w pojedynczą kartę sieciową, podłączoną do sieci LAN (zazwyczaj za pośrednictwem switch’a LAN), wówczas jej awaria spowoduje brak dostępności usługi. Jeżeli będą dwie karty sieciowe, podłączone do pojedynczego switch’a LAN, wówczas potencjalnym miejscem awarii staje się switch LAN. Switch LAN jest zazwyczaj połączony z firewall’em, dalej router’em WAN i dalej do operatora Internetu. Awaria każdego z wymienionych elementów może wpłynąć na omawianą usługę IT.
Projektując architekturę techniczną należy wziąć również pod uwagę usługi pomocnicze, których niedostępność może zakłócić działanie omawianej usługi IT, np. baza danych, DNS (Domain Name Service, odpowiedzialną za tłumaczenie nazw internetowych na adresy IP), Active Directory (do autoryzacji i autentykacji użytkowników oraz usług), usługi synchronizacji czasu, SSO (Single Sign On) oraz innych.
Jak można zauważyć, omawiana usługa IT jest uzależniona od bardzo wielu komponentów pośrednich, z których potencjalnie każdy może ulec awarii, a więc powinien być traktowany jako pojedynczy punkt awarii. Dostępność omawianej usługi IT jest więc zależna od poprawnego działania m.in.: serwera (w tym wszystkich jego komponentów), macierzy dyskowej (w tym wszystkich jej komponentów), zasilania (począwszy od zasilaczy w urządzeniach, na po operatora energii elektrycznej), łączności (wszystkich urządzeń sieciowych, po operatora Internetu), na awarii usług pomocniczych kończąc.
Przy okazji warto wspomnieć, że wiele urządzeń umożliwia prowadzenie prac serwisowych bez konieczności wyłączenia urządzeń. Możliwa jest bezpieczna aktualizacja oprogramowania sterującego urządzeniem (firmware), bez przerywania pracy, z możliwością wycofania zmian. Czasami możliwa jest wymiana fizycznego komponentu urządzenia w trakcie działania urządzenia (tzw. „hot-swap”), np. dysku w macierzy, zasilacza w urządzeniu, procesora lub kości pamięci w serwerze, karty sieciowej, itp. Warto jednak wcześniej zapoznać się z instrukcją, czy taka możliwość istnieje oraz jak bezpiecznie daną czynność przeprowadzić.
Jak wspomniano wcześniej, najczęściej stosowaną metodą redukcji ryzyka wystąpienia awarii usługi IT jest redundancja (nadmiarowość) jej elementów składowych. Na rysunku poniżej przedstawiona została przykładowa architektura fizyczna, odporna na awarie pojedynczych komponentów.
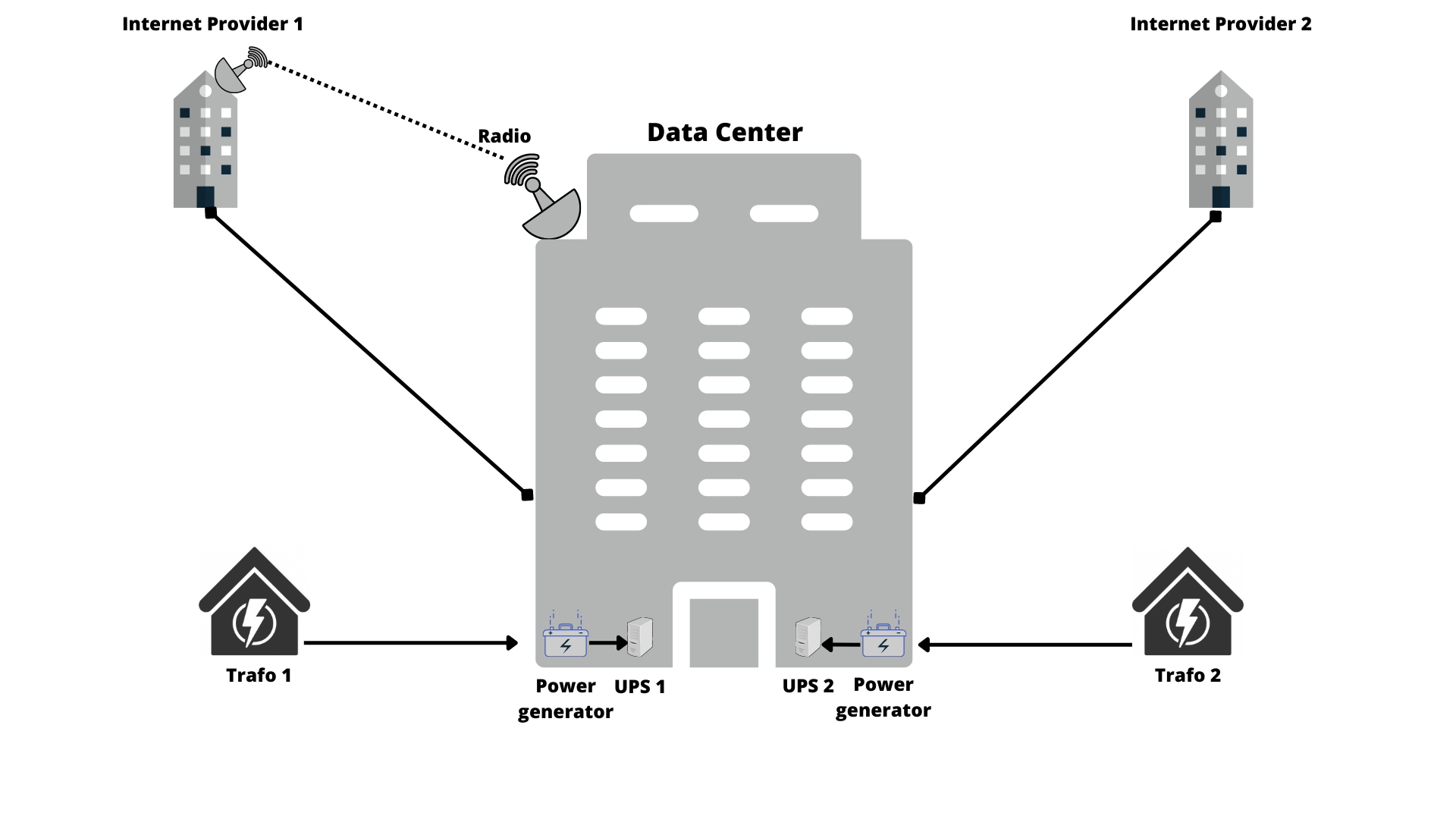
Zasilanie do centrum przetwarzania danych jest dostarczane dwoma niezależnymi torami, z dwóch niezależnych stacji trafo, wprowadzone do budynku osobnymi przewodami, z różnych stron budynku. Na każdym torze zasilania mamy generator prądu oraz UPS, tak więc niezależnie od awarii pojedynczego urządzenia, zasilanie urządzeń w centrum danych będzie zapewnione. Jeżeli wystąpi awaria dowolnego komponentu: zasilania po stronie operatora, generatora prądu, UPS-a – zasilanie do urządzeń nadal będzie nieprzerwanie dostarczane. Podobnie rzecz się ma z komunikacją. Dwa niezależne połączenia fizyczne, wprowadzone do budynku osobnymi przewodami, z różnych stron budynku, usługi komunikacyjne świadczone przez dwóch niezależnych operatorów Internetu, dodatkowo zabezpieczone linią radiową, która zapewni łączność w przypadku fizycznego uszkodzenia przewodów komunikacyjnych.
W środku data center sytuacja wygląda podobnie. Dwa niezależne tory prądowe są doprowadzone do szaf teleinformatycznych. Dodatkowo wszystkie urządzenia wyposażone są w dwa niezależne zasilacze, z których dowolny może ulec uszkodzeniu nie powodując przerwy w zasilaniu.

W przypadku komunikacji sieciowej, również wyeliminowane zostały wszystkie pojedyncze punkty awarii. Usługi sieciowe są dostarczane przez dwóch niezależnych dostawców, a więc awaria infrastruktury jednego z nich nie spowoduje zakłócenia naszej usługi IT. Mamy połączenia przewodami fizycznymi oraz linią radiową, a więc prawdopodobieństwo całkowitego zerwania łączności jest niewielkie. Występują dwa niezależne routery, z których awaria pojedynczego spowoduje jedynie krótką, kilku, kilkudziesięciosekundową przerwę w dostępności usługi IT. Idąc dalej, dwa firewall’e frontowe, działające w układzie połączonym (tzw. stacku), gdzie awaria pojedynczego urządzenia nie spowoduje nawet krótkiej niedostępności komunikacji. Analogicznie switch’e LAN oraz firewall’e wewnętrzne. Na koniec, każde urządzenie jest wyposażone w dwie karty sieciowe, przez co awaria pojedynczej karty nie zakłóci komunikacji.

Kolejnym elementem jest przestrzeń dyskowa na dane (ang. storage). Na poniższym rysunku serwery połączone są podwójnymi przewodami do macierzy dyskowej lub dwóch macierzy dyskowych. Na górnym rysunku serwery są podłączone tylko do jednej macierzy dyskowej, przez co pozornie mogłoby się wydawać, że stanowi ona pojedynczy punkt awarii. Jednakże, macierze dyskowe klasy biznesowej posiadają zawsze zduplikowane komponenty: dwa kontrolery dyskowe w układzie połączonym (tzw. stack’u), każdy podłączony do osobnego toru prądowego (lub nawet dwóch), gdzie awaria pojedynczego kontrolera nie spowoduje zakłócenia usług; dyski w układzie RAID, najczęściej z dyskami nadmiarowymi (tzw. spare), gdzie dane są zapisywane równolegle na wielu fizycznych dyskach, a równoczesna awaria nawet kilku dysków nie spowoduje niedostępności przestrzeni dyskowej lub utraty danych, a więc nie spowoduje zakłócenia usług; każdy z kontrolerów jest równocześnie podłączony niezależnymi liniami do urządzeń sieci LAN i/lub SAN (Storage Area Network). Można więc potraktować macierz dyskową jako komponent pozbawiony pojedynczego punktu awarii. Jeżeli jednak dla naszego przypadku biznesowego analiza ryzyka wskaże pojedynczą macierz dyskową jako potencjalnie źródło zakłóceń dla usługi IT, wówczas zawsze pozostaje możliwość równoległego zastosowania dwóch macierzy dyskowych z funkcją replikacji danych pomiędzy nimi.

Poza architekturą sieciową, serwerową, storage’ową (przestrzeń dyskowa), warto także bezpiecznie rozplanować fizyczne rozmieszczenie urządzeń w serwerowniach. W profesjonalnych centrach przetwarzania danych urządzenia rozmieszczane są w osobnych pomieszczeniach serwerowni, tzw. komorach, aby minimalizować negatywne skutki zdarzeń losowych (np. pożaru, który najprawdopodobniej zostanie szybko ugaszony automatycznym systemem gaszenia, bezpiecznym dla urządzeń elektrycznych). Jeżeli stosujemy replikację urządzeń, typu serwery, switch’e, router’y, macierze dyskowe, zazwyczaj umieszczane są one w osobnych pomieszczeniach, aby zminimalizować ryzyko ich równoczesnego uszkodzenia.
Na koniec warto zwrócić uwagę, że pojedynczym punktem awarii może być samo centrum przetwarzania danych. Takie zdarzenie jest mało prawdopodobne, ale możliwe. Centrum przetwarzania danych może zostać wyłączone z użycia lub nawet całkowicie zniszczone, np. w wyniku pożaru, powodzi, działań wojennych, katastrofy naturalnej, lotniczej. Co więcej, gdy takie zdarzenie będzie miało miejsce, jego konsekwencje mogą mieć skutki dramatyczne dla biznesu. Jeżeli wszystkie dane organizacji będą się znajdowały wyłącznie w takim pojedynczym centrum przetwarzania danych, wówczas nie dość, że usługi przestaną działać, to jeszcze istnieje ryzyko bezpowrotnej utraty danych. W ubiegłym roku zdarzył się pożar w jednym centrów danych globalnego dostawcy budżetowych usług chmurowych – budynek, wraz z urządzeniami i danymi klientów prawie doszczętnie spłonął. Rok wcześniej miał miejsce pożar w serwerowni jednego z większych operatorów telefonii komórkowej w Polsce. W pierwszym przypadku znaczna część klientów bezpowrotnie utraciła swoje dan – ale niestety w bardzo wielu przypadkach utrata dostępności usług oraz danych była konsekwencją nieprawidłowego zaprojektowana architektury usług IT oraz braku zrozumienia zakresu odpowiedzialności operatora chmury, określonego w warunkach świadczenia usług.
Na szczęście istnieją metody i technologie umożliwiające zabezpieczenie się na wypadek rozległej awarii centrum przetwarzania danych. Jak się zapewne można domyślić, istnieje możliwość skorzystania z drugiego, zapasowego centrum przetwarzania danych, odległego geograficznie. W najprostszym scenariuszu będziemy tam przesyłać wyłącznie kopie zapasowe, co zapewni ochronę przed bezpowrotną utratą danych, ale nie zapewni możliwości przywrócenia działania usług IT w krótkim czasie. W najbardziej zaawansowanym scenariuszu nasze usługi IT będą równocześnie i nieprzerwanie dostarczane z obu centrów przetwarzania danych, gdzie w tle będzie się odbywać replikacja danych on-line, a całkowita utrata pojedynczego centrum danych nie spowoduje nawet chwilowej niedostępności usług IT czy jakiejkolwiek utraty danych.
Podsumowując, pamiętajmy, że:
- Chrońmy usługi IT na wypadek określonych zdarzeń. Im więcej potencjalnych zdarzeń przewidzimy na etapie projektowania architektury IT, tym lepiej zabezpieczone zostaną działające na niej usługi.
- Rozwiązanie „idealne” rzadko będzie najlepszym wyborem, ponieważ nadmiarowe środki ochrony mogą nie mieć uzasadnienia biznesowego – koszty ich wdrożenia i obsługi mogą znacząco przewyższać ryzyko biznesowe.
- Architekturę usług IT należy projektować w kontekście oczekiwanych parametrów RTO (oczekiwanego czasu przywrócenia działania usług) oraz RPO (możliwa, akceptowalna utrata danych).
- Dobrze udokumentowane procedury awaryjne, regularnie testowane, znacząco zwiększają szanse na osiągnięcie zakładanego czasu przywrócenia usług IT oraz minimalizują ryzyko utraty danych.
- Jeżeli nie specjalizują się Państwo w projektowaniu ciągłości biznesowej usług IT, warto skorzystać z pomocy ekspertów.
W kolejnej odsłonie naszego bloga architektonicznego opowiemy o technikach replikacji danych - lokalnych (w ramach pojedynczej serwerowni, centrum przetwarzania danych) i rozproszonych (pomiędzy centrami przetwarzania danych). Ponadto dowiedzą się Państwo, do czego stosuje się klastry, w jaki sposób może być realizowana replikacja danych, co to jest i w jakim celu projektuje się rozwiązania HA (High-Availability), DR (Disaster Recovery), dlaczego warto mieć plany awaryjne BCP (Business Continuity Planning), czym się różnią usługi Active-Active od Active-Passive, Active-semi Active, do czego można wykorzystać chmury publiczne w zakresie planowania wysokiej dostępności oraz zapobiegania bezpowrotnej utracie danych, a także jakie są wymagania, konsekwencje i ograniczenia poszczególnych opcji zabezpieczeń.
Kontakt:

Kontakt marketingowy:

Rekomendowane strony

Mity i fakty usług subskrypcyjnych
Jaki jest prawdziwy potencjał modelu subskrypcyjnego i co wpływa na jego sukces?