
ナレッジ
STAND(統計的異常検知手法)の適用事例と特徴
時系列間の関係性の変化をスコア化する新たな機械学習手法
機械システムの異常を早期に検知する為の新しい機械学習技術とその用途について紹介します
目次
- 機械システムの保守においては早期の異常検知が重要となる
- 自動的に異常を検知する手法の構築は難しい
- STANDを用いることで関係性の変化を監視して異常を検知できる
- STANDは様々なシステムの異常検知に適用できる
- STANDの技術的優位性
機械システムの保守においては早期の異常検知が重要となる
コンピューター、車両、工場等の機械システムは社会的に必要不可欠な基盤であり、これらの稼働率の低下は社会的・経済的に多大な損失をもたらす。その為、機械システムを常時監視して、可能な限り早期に異常を検知してシステムを保全することが重要となる。
機械システムにおける損失は、①何らかの異常が発生し、②それに起因する障害が起こり、③その結果としてシステムの稼働率が大幅に低下する、という順序で発生する。人手のみの監視による保全では、顕在化した障害を見つけて対処することで稼働率低下による損害を抑制する。一方で、機械学習等のIT技術を用いた監視では、障害発生前に異常を検知することが可能であり、より早期の対処をすることで人手のみの監視よる保全より大きく損害を抑制できるようになると期待される(図1)。
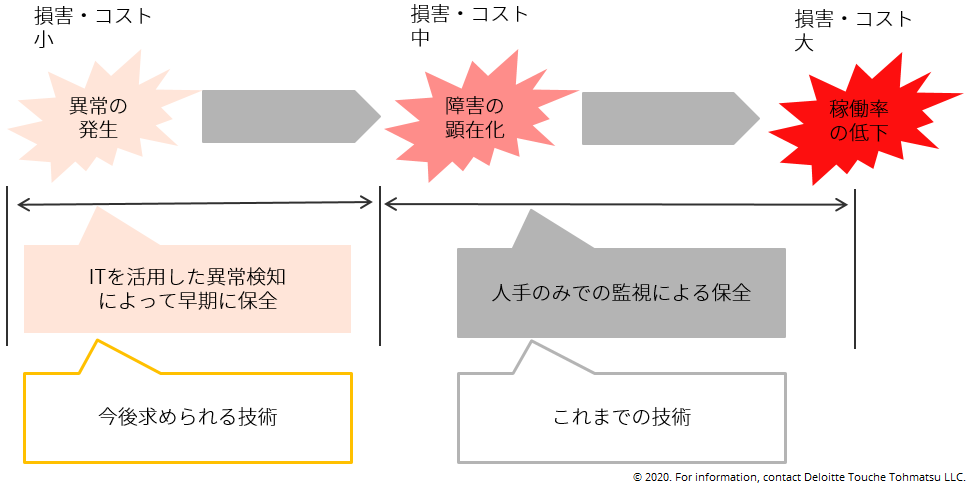
図1: IT技術を用いてより早期に機械システムの異常を検知することで、より大幅に損害を抑制できると期待される。
IT技術を用いた監視技術に対しては以下の二つが要請される。一つ目は、自動的であることである。それは、機械システムから得られるデータは多数の観測量(例えばIoTデータにおける多数のセンサーデータから)なる為に人手での監視が困難となることが多い為である。二つ目は、システム全体が異常かどうか判定できるのと同時に原因箇所の推定もできることである。それは、原因箇所の推定ができれば損失をより強く抑制できる為である。
自動的に異常を検知する手法の構築は難しい
上述の要請を満たす自動的な異常検知技術を構築することは、以下のような技術的な困難が伴う為に、そう容易ではない。
第一に、強い相関が存在する。機械システムにおいては要素間に強い相関関係がある為、単一要素のみを監視するだけでは異常の発生を検知できないことがほとんどである。例えば、ある種の機械には「電圧やギアの回転数が上下すること自体は異常ではないが、電圧が上がったのにギアの回転数が上がらないことは異常である」というような関係性がある。この場合、電圧やギアの回転数のみを個別に監視しても異常の発生は見つけられない。この例のような関係性を見ないと分からない異常をどのように検知するかが技術的な課題となる。
第二に、教師ラベルが存在しないことが多い。教師ラベルとは、各時点のレコードが異常か否かを表す「答え」のことである。教師ラベルがあれば観測されたレコードを異常なものと正常なものに分け、それらの間にどのような傾向の差があるかを見つけることで、異常時に共通する性質や傾向を見つけることができる。しかし、機械システムにおいて教師ラベルが記録されることは稀である。新規に観測されたものが異常かどうかは分からない(それが分かるということは問題が解決するということである)為、教師ラベルを付与するのは人手での作業となる。しかし、機械システムから得られるデータは膨大である(例えば、一分毎に観測され、それが一年分蓄積する)ことが多く、その全てにラベルを付与することは困難である。
このように、自動的な異常検知技術を構築する為には、「要素間の関係性に注目して異常を検知しなければならないが、どのような関係性があれば異常であるかという情報は与えられない」という困難を克服する必要がある。
STANDを用いることで関係性の変化を監視して異常を検知できる
上記のような背景からデロイト トーマツが独自に開発した機械学習技術がSTAND (STatistical ANomaly Detector)である。
STANDは複数の時系列を入力として、各時点でのそれらの時系列間での関係性の変化度をスコアとして出力する。時系列とは、例えば機械システム内のセンサーデータを一定の時間間隔で観測したものである。詳細については後述するが、このスコアを常時監視し、スコアが高い場合に異常が発生したとみなしてアラートを上げる、というのがSTANDの基本的な使い方である。つまり、関係性の急激な変化を異常として検知するというのがSTANDの機能である。
関係性の変化に注目するのは、上述の技術的な困難を克服することが目的である。まず、過去のデータの傾向・性質とは関係のない「何らかの現象」を異常だとみなすことができれば、教師ラベルがなくても異常検知の仕組みを構築できる。STANDにおいては、「何らかの現象」として関係性の変化を選んだことになる。
次に、「何らかの現象」として関係性の変化を選び、関係性が変化したら異常が発生したとみなすことで、機械システムの異常を効率よく検知できるようになる。機械システムは複数の構成要素(ギア、配線、回路等)からなり、それらの要素が科学的・工学的なルールに従って互いに関連しつつ動作する。この為、機械システムにおける異常は、動作の関係性が崩れる(それまでのルールから外れた動作をする)という形で現れることが多い。上述の例、「電圧やギアの回転数が上下すること自体は異常ではないが、電圧が上がったのにギアの回転数が上がらないことは異常である」はまさにそれに相当する。
STANDは、各時点における全体の異常度スコアと時系列毎の異常度スコアを出力する。全体の異常度スコア(以下、「全体スコア」と呼ぶ。)とは、時系列全体の関係性がどれだけ変化したかを表す値であり、この値が大きいことは関係性が急激に変化したことを表す。時系列毎の異常度スコア(以下、「個別スコア」と呼ぶ。)とは、ある時系列とそれ以外全ての時系列との関係性がどれだけ変化したかを表す値である。全体スコアは全時系列に注目して関係性の変化を定量化したものであり、各時点で一つの全体スコアが出力される。一方で、個別スコアは一つの時系列に注目して関係性の変化を定量化したものであり、入力時系列の数だけの個別スコアが出力される。
以下では、STANDの応用イメージを紹介しよう。20種類の経済時系列(為替と株価の時系列)にSTANDを適用する例を説明する。株価や為替の時系列には強い相関関係があることが知られており、何らかの法則に従って関連して動いていると期待される。この性質は上述の機械システムの性質と似ている。
このデータセットは11種類の株価指標(AORD, BVSP, CAC40, DAX, DJI, FTSE100, HangSeng, KOSPI, N225, RTSI, TSX_CMP)及び9種類の対米ドル為替(USDAUD, USDBRL, USDCAD, USDEUR, USDGBP, USDHKD, USDJPY, USDKRW, USDRUB)を日次で記録したものであり、公開されているデータを統合したものである。ここでは、2004年1月から2008年12月までのデータを入力として、この期間内の2008年9月15日のリーマンブラザーズの破綻より引き起こされた異常な経済時系列の変動をSTANDで検知することを試みる。
STANDを異常検知(システムの監視)に用いる際には、まず全体スコアに注目する。全体スコアが高い場合に、何らかの異常や変調が起こったとみなしてアラートを上げる。
上述の経済時系列に対するSTANDが出力した全体スコアが図2となる。全体スコアに幾つかのピークが見られ、その中の一つは2008年9月8日のものである。これはリーマンブラザーズ破綻(2008年9月15日)の直前に関係性の大きな変化が見られたことを示しており、STANDを用いて経済的な変調を検知できたということである。また、リーマンショック発生以前の2007年年末から2008年中はサブプイラム危機と呼ばれる経済的に不安定な期間であった。この期間における全体スコアは平均的に高くなっており、経済的な不安定さを高いスコア(関係性の大きな変化)として観測できたことを示している。
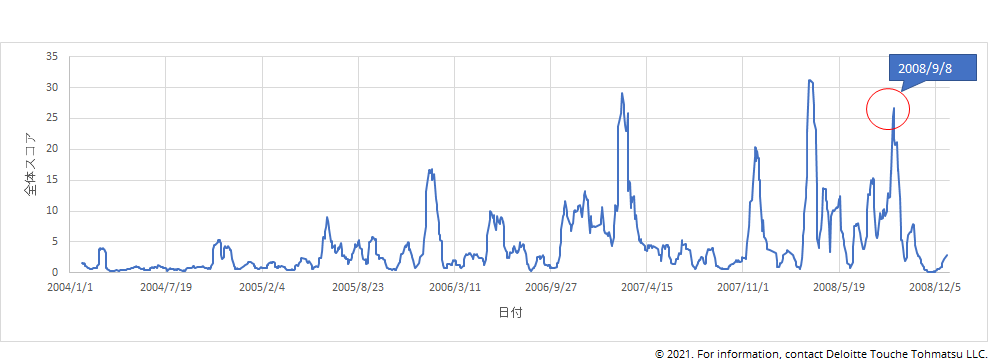
図2: 日次経済時系列に対する全体スコア。横軸が日付、縦軸がスコアを表す。スコアが高いほど株価・為替間の関係性の変化が大きく、何らかの経済的な変調が起こったとみなせる。
次に、全体スコアが高い時点における個別スコアに注目する。個別スコアが高いということは他の系列との関係性の変化が特に大きいということを意味する。この為、個別スコアに注目することで、高い全体スコア(システム全体の関係性の変化)に寄与する系列を見つけられる。因果関係を推定しているわけではないので原因箇所推定にはならないが、原因箇所推定の際に注目すべき時系列を列挙するという目的で個別スコアを使うことができる。
図2の全体スコアのピークの内、9/8のピーク(リーマンブラザーズ破綻の直前)に対応する個別スコアが図3となる。これらを見るとUSDRUB(ルーブルの対ドル値)のスコアが他の系列のスコアよりも高い。これは、9/8とその直前におけるUSDRUBの傾向が、その他の系列の傾向と大きく異なっていたことを表している。この期間において株価・為替が全体的に乱高下しているのに対して、USDRUBは安定して下落しており、確かにUSDRUBの傾向は他と異なっていた。このように、全体スコアが高い時点の個別スコアに注目することで他と傾向が異なる系列を抽出できる為、まず注目してみるべき系列が何かを見つけられる。
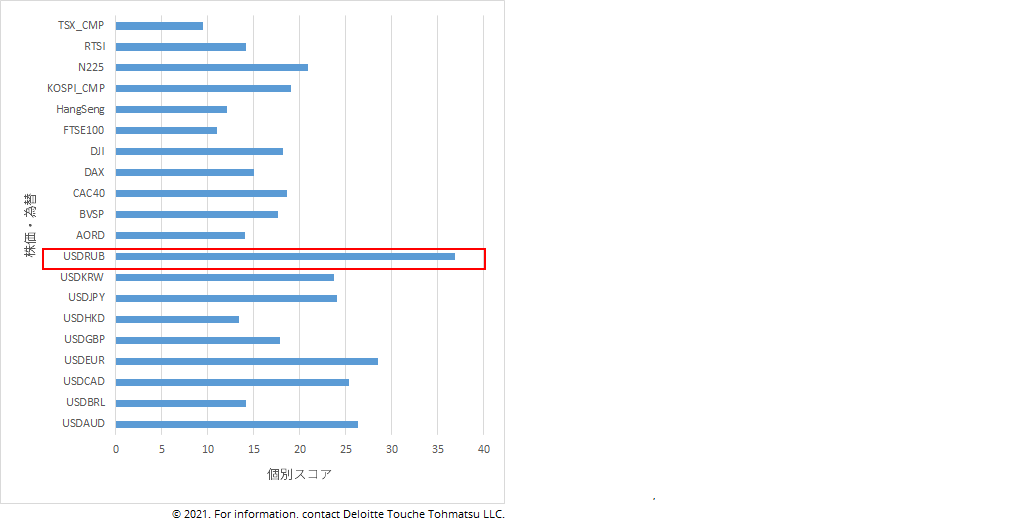
図3: 2008/9/8の個別スコア。スコアが大きいほど、その時系列(株価・為替)とそれ以外の時系列との間の関係性が大きく変化したということであり、他の時系列からの傾向の乖離が顕著であるといえる。
STANDは様々なシステムの異常検知に適用できる
STANDは様々な対象に適用できる。上述の例が経済時系列であったように、その対象は機械システムに限らない。科学的・工学的なルールに従って動作していて要素間の関係性が安定しており、異常の発生に伴ってその関係性が崩れると期待されるシステムが対象となる。
STANDの適用対象例を表1にまとめた。この表からも分かるように、STANDは特定の対象に限定されない様々な対象の異常検知に適用できる。機械システムは工学的なルールに従って動作しており、異常の発生に伴って「電圧があがるとギアの回転数が上がる」といったような関係性が崩れる。人体は科学的なルールに従っており、「不整脈が発生するとある種のイオンの濃度勾配間の関係が崩れる」といったように異常に伴う関係性の崩れが発生する。経済活動については一見これらのようなルールはなさそうだが、株価や為替の値自体は常に上下するのに対して、一定期間内でみるとそれらの間の相関関係は強くかつ安定していることが知られている。
STANDの適用対象 |
入力データ |
異常として検知されるもの |
|---|---|---|
自動車・船舶等の車輛 |
センサーデータ、走行ログ |
車両の故障 |
プラント |
センサーデータ |
稼働率の低下、プラントの故障 |
家電 |
動作ログ |
異常な動作、故障 |
コンピューターシステム |
パフォーマンスデータ |
異常な動作、故障 |
経済活動 |
株価・為替 |
経済的な変調 |
経済活動 |
企業間取引データ |
通常と異なる取引の発生 |
人体(脳) |
脳波データ |
てんかん発作の発生等の異常 |
人体(心臓) |
脈波データ、イオン勾配データ |
不整脈の発生等の異常 |
表1: STANDの利用シーン。科学的・工学的なルールに従って動作していて要素間の関係性が安定しており、異常の発生に伴ってその関係性が崩れる(と期待される)システムが対象となる。
また、上述の例を含めてここまででは教師ラベルがない場合(教師なしの異常検知)について述べた。しかし、教師ラベルがある場合(教師ありの異常検知)に対してもSTANDは適用できる。その際にはSTANDのスコアを入力として予測モデル(異常発生の有無や発生した異常の種類を判定するルール)を構築するという手法が用いられる。例えば、「センサー1のスコアが高く、センサー2のスコアが低い場合には異常Aが発生している」、センサー1のスコアが低く、センサー2とセンサー3のスコアが高い場合には異常Bが発生している」等といったルールを構築するイメージである。
STANDの技術的優位性
以下では、STANDの三つの技術的な特徴・優位性について説明する。
第一の特徴・優位性は、入力時系列全体の異常度を表す全体スコアと個別の時系列の異常度を表す個別スコアを出力できることである。経済時系列の例のように全体の異常を監視した後に注目すべき系列を見つけるという手順を踏むにはこれら二つが必要となる。また、関係性の変化に注目する際に時系列のペア(例えば10個の時系列がある場合に10×9÷2=45通りのペア)に対してスコアを付与するという方法も考えられるが、時系列の数と比較してペアの数は膨大になる為、監視すべき対象が多すぎるという問題が生じる。上記の手順を踏む際に時系列毎のスコアを出力するというのは、監視の手間を必要最小限に留めるという意味で有用である。
第二の特徴・優位性は、これらのスコアが同一の理論的枠組から導かれることである。全体スコアと個別スコアを別々の手法で導くならば、全体スコアが高い場合に個別スコアを見ても、それによって注目すべき系列が抽出できると主張するのは難しい。なぜならばスコア間の理論的なつながりが不明確だからである。STANDではこのような困難を理論的に解決している。
第三の特徴・優位性は、STANDの出力するスコアが統計的に自然な量となっていることである。どのような分析をするにせよ、その際に使う手法が理論的な背景に裏打ちされている方が望ましい。STANDのスコアは関係性の確率分布の変化量を表すものであって、統計的・理論的に自然な量となっており、このような要請を満たしている。
STANDでは、行列カーネル及び二重カーネル化スコアリングという独自の理論的手法を用いて、これらの特徴・優位性を実現している。これらの技術的な詳細に関しては論文(※1)を参照して頂ければ幸いである。
※1 有限責任監査法人トーマツ 広瀬 俊亮, 有限責任監査法人トーマツ 神津 友武「二重カーネル化スコアリングと行列カーネルを用いた異常検知」
J-STAGE 人工知能学会論文誌:https://www.jstage.jst.go.jp/article/tjsai/31/6/31_AI30-D/_article/-char/ja/(外部サイト)
まとめ
デロイト トーマツ独自の機械学習技術であるSTAND(STatistical ANomaly Detector)を紹介した。STANDは時系列間の関係性の変化をスコア化するアルゴリズムであり、主に異常検知を目的として使用される。STANDは何らかのルール(例えば科学的・工学的なルール)に従うシステムにおけるルールの変化(関係性の崩れ)を検知する手法であり、機械システム、経済活動、人体等に対して適用できる。本稿では、株価・為替の時系列データへのSTANDの適用例を示した。
何らかのシステムを監視し異常を早期に検知して対応することで、異常の発生による損害を抑制することへの需要は高い。自動的に大量のデータを扱えることなどから、異常の早期検知に対して機械学習や統計解析等の技術が役立つと期待される。本稿で紹介した、複数時系列との関係性の変化をみることで異常を検知するというやり方は、機械学習技術を用いた早期異常検知へのアプローチの一つである。
デロイト トーマツでは、ここで説明したSTANDに限らない、異常検知全般についての解説記事(※2)を提供している。そちらも参照して頂ければ幸いである。
※2 人手での検知と機械学習手法による検知の比較や機械学習手法の分類と特徴等について概観している。
サービス内容等に関するお問い合わせは、下記のお問い合わせフォームにて受付いたします。お気軽にお問い合わせください。


