
DevOps and SRE: A Capability Model for these Complementary Roles | Deloitte US has been saved
A blog post by Eric A. Marks, specialist leader, Cloud Strategy, Deloitte Consulting LLP
DevOps is an approach to application development with the goal of bridging the gap between development and operations teams. It emphasizes collaboration and communication to improve the speed and quality of software releases. DevOps automates the processes involved in software development, and it can enable the rapid and more frequent release of software. With DevOps, organizations can increase efficiency and improve their ability to deliver applications and services at high velocity.
Site reliability engineering (SRE) combines software engineering and operations principles to design, build, and maintain reliable software systems. Site reliability engineering teams are responsible for the availability, performance, and capacity of systems, as well as for building automation to prevent and mitigate outages. Site reliability engineering teams strive to reduce repetitive toil and ensure that systems are running smoothly and efficiently.
DevOps and SRE are complementary in both philosophy and practice. To effectively develop and maintain software applications, both SRE and DevOps should function and interact well together.
A DevOps/SRE capabilities model
The SRE and DevOps interaction model can be described using a reliability lifecycle model and is grounded in a set of capabilities that are unique to SREs, unique to DevOps, or are shared. The capabilities are essential building blocks to help identify and develop the roles and responsibilities, the skills and training, and the operating model within which both SREs and DevOps engineers work.
Highlighted in figure 1 are capabilities an organization can develop in DevOps and SRE domains to attain the highest level of maturity in the application software development life cycle (SDLC) and operations.
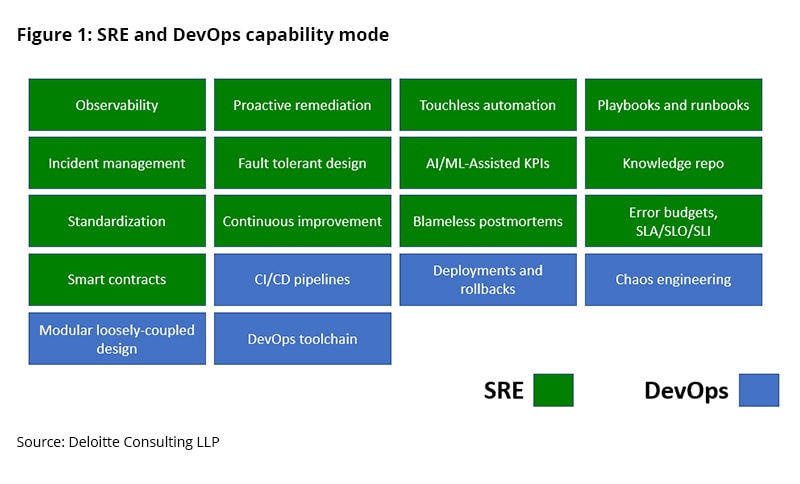
As illustrated in figure 1, the following SRE capabilities are necessary to support the reliability lifecycle model for a new application or service:
- Observability (monitoring, tracing, and other observability capabilities and tools)
- Proactive remediation
- Touchless automation
- Playbooks and runbooks
- Incident management
- Fault tolerant design
This is not to say that DevOps or other engineers do not leverage these capabilities; they do. These are simply better associated with an SRE operating model than they are for DevOps or other software engineering disciplines.
There are also several DevOps capabilities that are essential to achieve a high-performing DevOps operating model in the context of the reliability life cycle:
- CI/CD pipelines
- Deployments
- Rollbacks
- Chaos engineering
- Modular, loosely coupled application design
- DevOps/DevSecOps toolchain engineering, integration, and automation
While these are best practices and recommendations for division of SRE and DevOps capabilities, there are some that, by necessity, must be shared, such as the following:
- Playbooks and runbooks
- Standardization of processes and tools
- Continuous improvement
- Knowledge repository and lessons learned
This simple SRE/DevOps capability model helps clarify how SREs and DevOps engineers work together under a shared operating model in support of shared objectives. While their specific duties differ, they overlap in some areas and share in many capabilities, all to the benefit of achieving a high-performing software engineering organization.
SRE and DevOps as complementary capabilities
DevOps and SRE are complementary practices. For example, to deliver a system with a fault-tolerant design, the DevOps discipline will enable the application development team to build, test, and deploy that system through an automated CI/CD pipeline. Once the system is deployed, the SRE will leverage observability capabilities, such as monitoring, logging, and log analytics, to help respond to adverse change to the deployed application.
The SRE relies on observability tools and key metrics to perform their functions. Site reliability engineers are equipped with a robust set of observability capabilities—monitoring and visualization tools—that provide an end-to-end visibility of the deployed assets and their interactions. In addition, observability tools also provide insights and support detailed analysis of adverse events and facilitate problem resolution and root-cause analysis.
Upon discovery of system anomalies or instability issues, the SRE works with the DevOps team to assess the situation and then either perform a roll back if needed, or if possible, rapidly resolve the issue. If a rollback is deemed necessary, the SRE then works with the DevOps team to create a new release that addresses the issue. The SRE also works closely with the application teams to support deployment of new releases and ensure a smooth and error-free path to production.
Another area of collaboration occurs when the SRE team, equipped with meaningful insights into the performance of the systems, is able to provide system optimization feedback and recommendations. In this mode, the DevOps team engages with the application team to evaluate and incorporate those recommendations if they are viable. This process is thus a continuous feedback optimization loop where the system eventually reaches a point where it can operate within the agreed-upon error budget.
The difference between SRE and DevOps
Although we consider DevOps and SRE as two different disciplines, there is a fair amount of overlap in their respective responsibilities. Site reliability engineering is best described as a collection of engineering principles and practices, many derived from software engineering, and applying those software engineering practices to infrastructure and operations challenges to achieve operations excellence. The goal of the SRE discipline is to achieve operations excellence by creating scalable, reliable, and resilient software systems and services.
By contrast, a DevOps engineer introduces methodologies, processes, and tools that span the entire SDLC from coding and deployment to adding new features and performing maintenance and updates. DevOps engineers strive to reduce SDLC complexity and balance the needs of software developer goals, such as code quality, velocity, and faster releases, versus the goals of operations, which focus on stability, reliability, and availability.
A simple way to compare DevOps engineers to SREs is as follows: DevOps engineers industrialize the SDLC using automation and tooling to ensure that the SDLC is capable of delivering applications and services that meet functional, non-functional, and security/compliance/risk requirements. An SRE focuses on ensuring that the application or service, once released into production, is able to meet its defined SLA and is reliable, stable, and available through the use of automation techniques.
Although DevOps helps address the gap between operations and development, it does not clearly define how to accomplish these goals. Site reliability engineering embodies DevOps philosophies, yet it goes even further to help achieve reliability through engineering and operations activities. In some cloud ecosystems, SREs are the engineers who implement DevOps concepts and capabilities.
Figure 2 highlights some of the responsibilities of a DevOps engineer (in blue) as compared to a SRE (in green), as well as the overlapping areas (in blue and green).

As illustrated in Figure 2, the focus for DevOps is to enable an automated way of running enterprise software development lifecycle processes such that they are capable of delivering an application, a system, or a service reliably and with the necessary oversight and governance. By contrast, the primary focus for SRE is to ensure that the application, system, or service, once released into production, is operating under, or more appropriately within, a defined set of performance thresholds known as service level objectives (SLOs), service level agreements (SLAs) and service level indicators (SLIs).
An SRE relies on DevOps processes and automation to deliver business capabilities (applications, systems. services) that meet functional requirements and non-functional requirements (NFRs) such as reliability, stability, recoverability and more. The DevOps engineer relies on the SRE to enable and sustain a more predictable environment for deployments and maintenance of the deployed business capabilities.
The bottom line
Site reliability engineers and DevOps engineers are critical resources in a modern software delivery enterprise. They are also scarce. It is essential to optimize how SRE teams and DevOps teams are organized and how they operate to deliver high-quality software. Site reliability engineers and DevOps are complementary skill sets that must be aligned to a shared operating model and interaction model that drives desired productivity and software quality and ultimately revenue and customer satisfaction.
Get in touch

David Linthicum
Managing Director | Chief Cloud Strategy Officer
As the chief cloud strategy officer for Deloitte Consulting LLP, David is responsible for building innovative technologies that help clients operate more efficiently while delivering strategies that enable them to disrupt their markets. David is widely respected as a visionary in cloud computing—he was recently named the number one cloud influencer in a report by Apollo Research. For more than 20 years, he has inspired corporations and start-ups to innovate and use resources more productively. As the author of more than 13 books and 5,000 articles, David’s thought leadership has appeared in InfoWorld, Wall...