Using synthetic data to enhance autonomous driving has been saved

Analysis
Using synthetic data to enhance autonomous driving
The future of AV testing and development
High-profile incidents have highlighted the critical importance of rigorous testing for autonomous vehicles (AVs). When real-world data is absent, creating a synthetic dataset can bring the performance of artificial intelligence (AI) models remarkably close to those trained on real-world data. Learn more about the value of synthetic data in improving autonomous model training.
Today’s AV training gap
Despite the tremendous progress in autonomous driving technology, high-profile incidents have highlighted some of the significant challenges that remain. From vehicles becoming immobilized to tragic pedestrian accidents, these events underscore the importance of rigorously testing and comparing self-driving systems across a wide range of scenarios.
Some of these incidents can be attributed to rare edge cases that are difficult to analyze through real-world testing alone. However, autonomous vehicles should be prepared to handle a wide variety of complex multi-agent interactions, adverse weather conditions, construction zones, and other potentially hazardous situations.
Collecting sufficient real-world training data to cover this spectrum can be an immense challenge. Road testing and manual data annotation are likely time-consuming and costly and may be impractical for capturing infrequent events. This is where synthetic data generation is emerging as a powerful tool to augment and diversify the training datasets for autonomous driving perception systems.
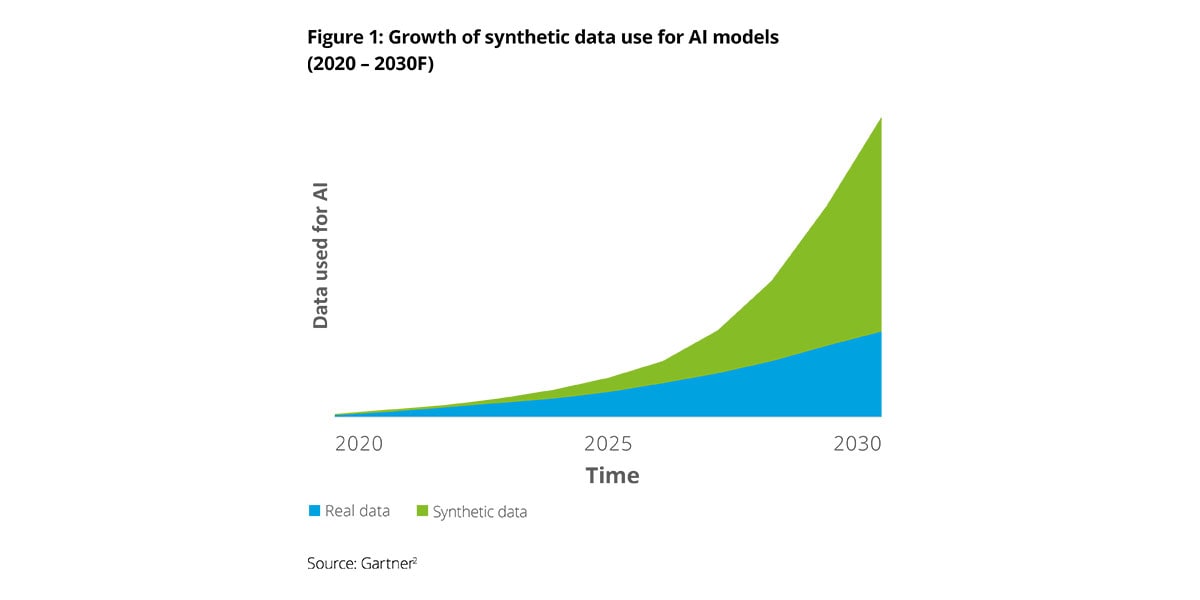
The rise of synthetic data
By leveraging advanced simulation platforms, it is possible to create virtually limitless permutations of environments, weather conditions, sensor configurations, and edge cases, all with precise, pixel-level annotations. This allows developers to rapidly iterate, test, and validate their autonomous driving solutions—ultimately paving the way for safer deployments on public roads.
In fact, synthetic data is expected to play an increasingly important role in model training for autonomous driving, fundamentally reshaping the automotive industry’s approach to solving data-centric challenges.
Where real-world data falls short
When it comes to model training for autonomous driving, the need for high-quality, annotated data is critical. Traditional data collection methods involve operating fleets of sensor-equipped vehicles that gather data from real-world environments. While effective, this approach is plagued by several key issues. First, collecting and annotating real-world data is an arduous task that requires a significant investment of time and resources. Second, the range of scenarios real-world data is able to capture can be limited.
There are also ethical and legal considerations. Data privacy regulations limit the scope of real-world datasets that can be collected and used. Biases inherent in real-world data also pose significant challenges, particularly when algorithms trained on such data are expected to operate in diverse and unpredictable environments.
Why synthetic data should be the way forward
By definition, synthetic data is information generated via computer algorithms or simulations, designed to mimic the properties of real-world data. Unlike traditional data, synthetic data can be generated quickly and in large quantities, drastically cutting down on time and resource investments.
Synthetic data offers a controlled environment to run a wide range of scenarios, helping capture real-world situations such as a jaywalking pedestrian. And the risk of data privacy issues is eliminated because synthetic data is generated and not collected.
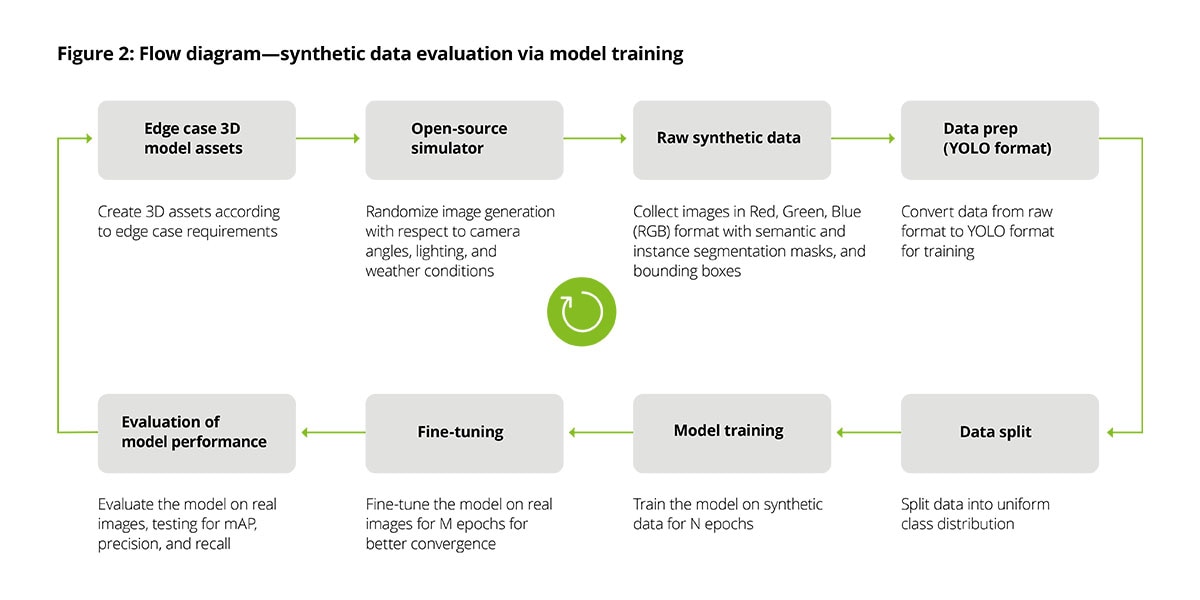
Open-source driving simulators
The integration of synthetic data into the development of autonomous driving systems underscores a broader industry trend toward leveraging digital simulations to overcome constraints of real-world data collection. Open-source simulators for autonomous driving research are emerging as essential tools in this arena.
These simulators not only provide a foundational suite of assets and vehicles, but also invite expansion to encapsulate a broader spectrum of real-world scenarios. By integrating and enhancing open-source simulator capabilities with additional assets, diverse environments and conditions can be simulated with a high degree of realism.
Moving forward
As the field of autonomous driving continues to progress, synthetic data will likely become an invaluable tool for training artificial intelligence models. Extensive experiments using an open-source simulator have shown that synthetic data can provide a solid foundation for model training. Furthermore, blending synthetic and real-world data can lead to AI models that are not only accurate but also resilient and capable of handling a variety of situations.
Experiments also underscored the fact that when the availability of real-world data is limited, the accuracy of AI models can be enhanced by supplementing synthetic data. In situations where real-world data is completely absent, creating a large, varied, and randomized synthetic dataset can bring the performance of the AI models remarkably close to those trained exclusively on real-world data. This underscores the significant potential value of synthetic data in improving autonomous model training and performance.
Get in touch

Recommendations

Modernizing our intersections
Autonomous vehicle applications and data

Explore Deloitte’s Autonomous Vehicle Practice
Accelerate the development of autonomous vehicles with Deloitte.